
- 0.6B Qwen3インタープリタがQwen3-32Bへの直接プロンプティング(68.70%)を上回る73.78%の精度を達成しながら、推論メモリを約50分の1に削減
- 自然言語の処理仕様を4BコンパイラがLoRAアダプタに変換し、プログラム1つあたり約23MBのファイルとしてキャッシュ・バージョン管理・オフライン実行が可能
- 1000万サンプルのベンチマーク「FuzzyBench」を合わせて公開。800以上のカテゴリをカバーし、再現性の高い評価環境を整備
研究の背景
「このメッセージは緊急か?」「この壊れたJSONを修復して」「個人情報を除去して」など、現代のソフトウェア開発には従来のコードでは書きにくい処理が数多く存在します。こうした処理は入力と出力の対応が本質的に曖昧で、正規表現や条件分岐では表現しきれません。
近年はLLMへのプロンプト呼び出しでこれらを解決するケースが増えています。しかし、大規模モデルへのAPI呼び出しは応答が遅く、コストがかかり、ネットワーク接続が前提です。かといって大規模モデルをローカルで動かすにはメモリが膨大になります。Harvard大学らの研究チームは2026年7月、この問題に対する全く新しいアプローチを「Program-as-Weights(PAW)」として発表しました。
コンパイラとインタープリタの発想を借りる
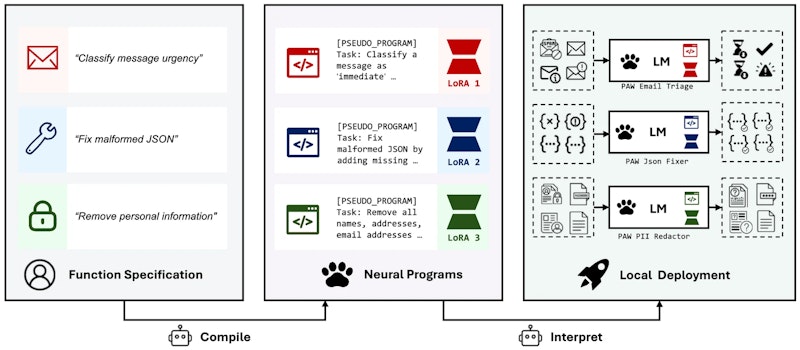
PAWの核心は、従来のソフトウェア開発にあるコンパイラとインタープリタの分離という設計思想をLLMに持ち込むことです。通常のプログラムはソースコードとして書かれ、コンパイラが機械語に変換します。PAWでは「自然言語で書いた処理仕様」が入力であり、「ニューラルネットワークの重み(LoRAアダプタ)」がコンパイル後のプログラムに相当します。
仕様のコンパイルは一度だけクラウド上で行い、生成されたLoRAファイルを手元に保存しておけば、その後の実行はオフラインで完結します。コンパイル済みプログラムは通常のファイルと同様にキャッシュでき、バージョン管理システムで管理でき、ライブラリ関数のように呼び出せます。
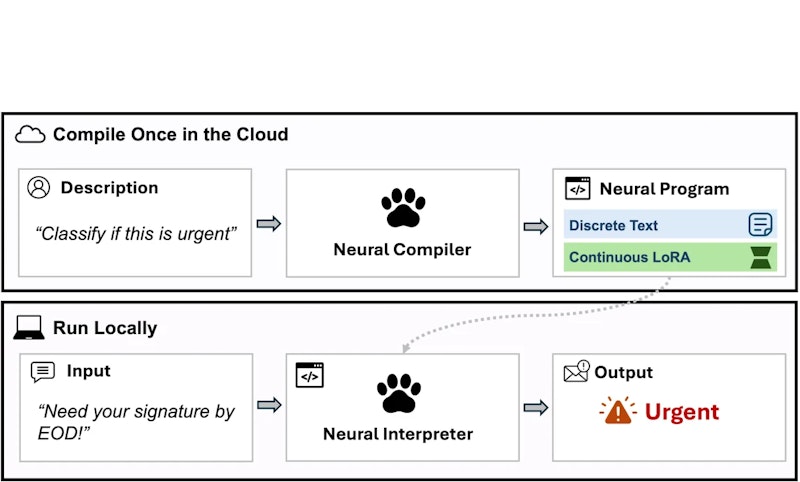
アーキテクチャの仕組み
PAWのパイプラインは3段階で構成されます。
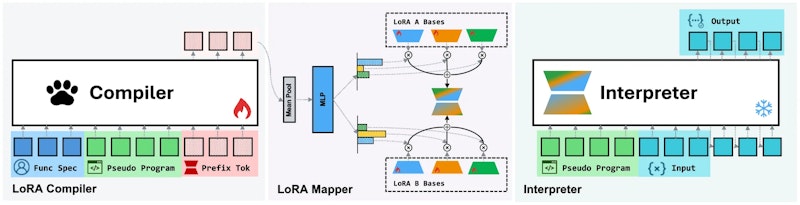
- 疑似コンパイル: 凍結されたQwen3-4Bが自然言語の仕様を読み込み、タスク説明と入出力例を含む「疑似プログラム」を生成する
- LoRAコンパイル: 訓練済みのLoRAコンパイラが仕様と疑似プログラムを読み込み、深さ方向に平均プーリングした隠れ状態をMLPに通じてLoRA行列の混合係数に変換する。共有の学習済み基底行列(ランク64、モジュール種別ごとに64基底)を線形結合することで、関数ごとに異なる約3850万パラメータのLoRAを生成する
- ローカル実行: 凍結した0.6Bのインタープリタが疑似プログラムとユーザー入力を受け取り、対応するLoRAを動的に適用して出力を自己回帰的に生成する
量子化モデル(Q5_K_M)とLoRA(Q4_0)を合わせたインタープリタ全体は約507MBで、プログラムあたりの追加LoRAファイルは約23MBと非常にコンパクトです。複数の処理仕様を「プログラムライブラリ」として管理し、呼び出し時に対応するLoRAだけを切り替えるという運用が可能です。
FuzzyBench: 1000万サンプルの評価基盤
PAWの評価のために、研究チームは1000万サンプルの合成データセット「FuzzyBench」を構築・公開しました。テキスト分類、パース処理、フォーマット変換、ツール呼び出し、セマンティック検索など800以上のサブカテゴリを29バージョン・7つの大カテゴリに整理しています。
テストセットは2つの強力なモデルが一致した解答のみを正解とするフィルタリングを適用しており、評価の信頼性を高めています。また、仕様文にわざとタイポを混入させた実験では、疑似プログラムが中間表現として機能することで精度低下がわずか4.5ポイントに留まり、入力の揺らぎに対するロバスト性も確認されています。
実験結果
FuzzyBenchでの完全一致精度を比較すると、PAWアプローチの優位性が数値で示されています。
手法 | 精度(完全一致) |
|---|---|
PAW(Qwen3 0.6Bインタープリタ) | 73.78% |
Qwen3-32B 直接プロンプティング | 68.70% |
通常のフルファインチューニング | 58.40% |
固定LoRA(r=64) | 52.10% |
0.6Bという極めて小さなモデルが32Bモデルへの直接プロンプトを5ポイント以上上回る精度を達成しています。推論メモリは32Bモデルの約50分の1に削減され、MacBook M3では毎秒31.6トークン・コールドロード0.48秒で動作します。Agents-A1のように小さなモデルで大規模モデル相当の性能を引き出すアプローチが注目を集める中、PAWは「コンパイル」という全く異なる切り口でこの課題に取り組んでいます。
まとめと今後の展望
Program-as-Weightsは、処理ロジックをLoRAアダプタというファイルとして表現することで、バージョン管理・キャッシュ・オフライン実行・ライブラリ化といったソフトウェア工学の恩恵をLLMベースの処理に持ち込む研究です。「仕様を書けば動くプログラム」をクラウドで一度生成し、その後はネットワーク不要で何千回でも呼び出せるというモデルは、エッジデバイスや低コスト推論への応用において現実的な選択肢になりえます。
現状の適用範囲はテキスト中心の「ファジー関数」に限られており、コンパイラ自体の訓練コストや、仕様の品質が出力精度に与える影響については今後さらなる検証が必要です。また、生成されるLoRAのサイズや精度はインタープリタとなるベースモデルの能力にも依存するため、より小さなベースモデルへの拡張性も課題として残ります。それでも、自然言語で仕様を書くだけで小型モデルが大規模モデル相当の精度で動作するという実証は、LLMの実用化における新しい方向性を示しています。







