
- Zero-shot・Few-shot・CoT・ReActの4つの主要手法を仕組みから図解で解説
- LLMの動作原理に基づいた各手法の使い分けガイドを提示
- 2026年のReasoning Model(o3・DeepSeek-R1)との関係性を解説
プロンプトエンジニアリングとは何か
プロンプトエンジニアリングとは、大規模言語モデル(LLM)を効率的に使用するためのプロンプトを開発し最適化する技術です。同じ質問でも、問い方を変えるだけでLLMの回答精度は劇的に変わります。
この技術が重要な理由は、LLMが「次に来る単語を予測する」という仕組みで動いているためです。適切なプロンプト設計により、モデルの持つ知識を最大限に引き出すことができます。Attention機構を基盤とするTransformerモデルは、プロンプト内の文脈をどう理解するかが性能に直結します。
本記事では、実務で最も使われる4つの手法(Zero-shot・Few-shot・CoT・ReAct)を、LLMの動作原理から段階的に解説します。
Zero-shotプロンプティング
Zero-shotとは何か
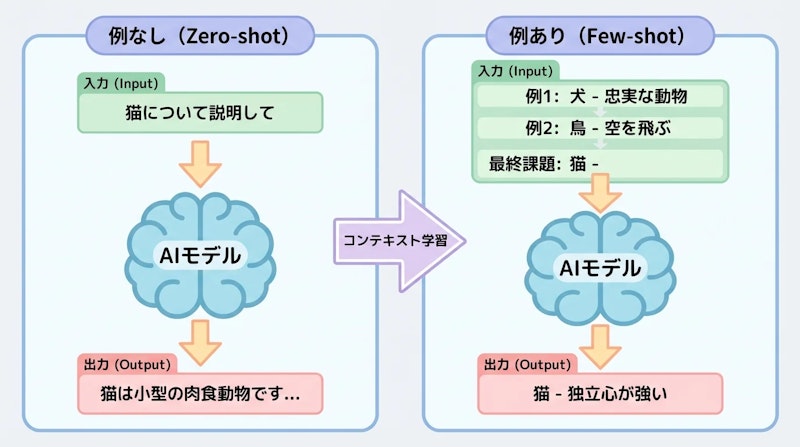
Zero-shotプロンプティングは、LLMに事前の例を一切提供せずに、指示文だけでタスクを実行させる手法です。最もシンプルで、かつ最も広く使われているアプローチです。
例えば「次のテキストを中立、否定的、肯定的のいずれかに分類してください。テキスト: 休暇はまずまずでした。」という指示だけで、モデルは「中立」と正しく分類できます。
なぜZero-shotが機能するのか
この手法が機能する理由は、現代のLLMが次の2つの技術で訓練されているためです。
- 指示チューニング(Instruction Tuning)— 多様な指示文に従うよう学習
- 人間のフィードバックからの強化学習(RLHF)— 人間の好む回答パターンを学習
これらにより、モデルは見たことのないタスクでも、指示文から意図を推測して実行できるようになっています。
Zero-shotの使いどころ
Zero-shotは以下のような場面で最適です。
- シンプルな分類タスク(感情分析、トピック分類など)
- 要約や翻訳など、定型的なタスク
- 例を用意する手間を省きたい場合
ただし、複雑な推論タスクや専門的な判断が必要な場合は、次に紹介するFew-shotやCoTが必要になります。
Few-shotプロンプティング
Few-shotとは何か
Few-shotプロンプティングは、プロンプト内に1〜5個程度の例を示すことで、モデルの性能を向上させる手法です。モデルは提供された例からパターンを認識し、新しい入力に対して同様の方式で応答します。
例えば、新しい単語「whatpu」を文中で使う例を1つ示すと、モデルは別の新しい単語「farduddle」も適切に文中で使えるようになります。これが文脈学習(In-Context Learning)と呼ばれる現象です。
Few-shotの実践例
感情分析タスクでは、意図的に逆のラベルを付けた例を示しても、モデルは正しく学習できます。
これは素晴らしい! // ネガティブ
これは酷い! // ポジティブ
なんてひどい番組なんだ! // この場合、モデルは「ネガティブ」と正しく出力します。これは、モデルがプロンプト全体の構造から「逆のラベル付けルール」を理解したためです。
Few-shotの限界
Few-shotは多くの場面で有効ですが、複雑な推論タスク(例: 奇数の合計が偶数かどうかの判定)では精度が不十分な場合があります。このような場合には、次に紹介するChain-of-Thought(CoT)が必要です。
Chain-of-Thought(CoT)プロンプティング
CoTとは何か
Chain-of-Thought(CoT)プロンプティングは、中間的な推論ステップを明示的に示すことで、モデルの複雑な推論能力を引き出す手法です。Wei et al.(2022年)により提唱されました。
この手法の核心は、「答え」だけでなく「答えに至る過程」をモデルに示す点にあります。人間が算数の問題を解く際に途中式を書くのと同じ原理です。
CoTの2つのアプローチ
CoTには2つの主要なアプローチがあります。
- Few-shot CoT — 推論ステップを含む例を数個提示する
- Zero-shot CoT — 「ステップバイステップで考えてみましょう」という一文を追加するだけ
特にZero-shot CoTは驚くべき効果を持ちます。例えば、リンゴの個数を数える問題で、この一文を加えるだけで正答率が大幅に向上します。
CoTの実践例
通常のプロンプトでは「11個」と誤答するリンゴ問題も、「ステップバイステップで考えてみましょう」を追加すると、以下のように正しい推論プロセスが展開されます。
最初に10個のリンゴがありました。
2個を隣人に渡したので、10 - 2 = 8個になりました。
また2個購入したので、8 + 2 = 10個になりました。
答え: 10個この手法は、算数問題だけでなく、論理的思考が必要なあらゆるタスクで有効です。
ReActフレームワーク
ReActとは何か
ReActは「Reasoning(推論)+ Acting(行動)」の略で、Yao et al.(2022年)により提唱されたフレームワークです。LLMが推論トレースとタスク固有のアクションを交互に生成する仕組みです。
従来のLLMは「考える」だけでしたが、ReActは「考えて行動する」サイクルを実現します。これにより、外部ツールとの連携が可能になります。
ReActの動作原理
ReActは2つの主要な要素で機能します。
- 推論トレース生成 — モデルが思考プロセスを明示化し、アクション計画を誘導・追跡・更新する
- アクション実行 — 外部ソース(知識ベース、検索エンジン、APIなど)との連携により、実際の情報を取得する
例えば、「最新のAI論文を3つ教えてください」という質問に対し、ReActは以下のように動作します。
思考: 最新論文を知るには検索が必要だ
行動: Google Scholar APIで検索を実行
観察: 3つの論文タイトルを取得
思考: これらを要約して提示しよう
最終回答: [論文リスト]ReActの実用性
ReActは、ChatGPTのプラグイン機能やGPTsの基盤技術として実装されています。LLMが単なる「回答マシン」から「タスク実行エージェント」へと進化する鍵となる手法です。
2026年のReasoning Modelとの関係
2024年末から2026年にかけて、OpenAIのo3シリーズやDeepSeek-R1など、推論特化型モデル(Reasoning Model)が登場しました。これらのモデルは、CoTの原理を内部メカニズムとして組み込んでいます。
従来はユーザーがプロンプトでCoTを指示する必要がありましたが、Reasoning Modelは自動的に内部で推論ステップを生成します。これにより、複雑な数学問題やコーディングタスクでの精度が飛躍的に向上しています。
ただし、プロンプトエンジニアリングの重要性は変わりません。むしろ、モデルの推論能力が高まったことで、より高度な指示設計が可能になっています。Zero-shotやFew-shotで基礎を固め、必要に応じてCoTやReActを組み合わせる戦略が、今後も有効です。
まとめ
プロンプトエンジニアリングの4つの主要手法を理解することで、LLMの能力を最大限に引き出せます。シンプルなタスクにはZero-shot、パターン学習が必要ならFew-shot、複雑な推論にはCoT、外部ツール連携にはReActと、タスクに応じて使い分けましょう。
2026年のReasoning Modelは推論能力を内蔵していますが、適切なプロンプト設計がその性能を左右します。本記事で紹介した手法を実務で試しながら、自分なりのプロンプト設計パターンを確立していくことをお勧めします。







