
- LLM(Gemini)が3Dバウンディングボックス軌跡とカメラ動作を計画し、動画生成の制御信号として与えるアーキテクチャを提案
- 画面外に消えたオブジェクトの外観・特性を記憶し、再登場時も同一性を維持する「永続的動的オブジェクトメモリ」を実現
- 画質評価指標PSNRで18.1を達成し、比較対象のHyDRA(13.4)やInfinite-World(14.6)を含む全指標で既存手法を上回る
研究の背景
動画生成の分野では、カメラワークや登場するオブジェクトの動きを細かく指定できる「制御可能な世界モデル」への需要が高まっています。ゲームエンジンの代替やロボットの学習環境として活用するには、「どのキャラクターがどこへ移動するか」「カメラをどう動かすか」をテキストで柔軟に指示できる機能が欠かせません。
しかし従来の動画生成モデルは、意味的な動き制御と視覚的な描画を同じネットワーク内で処理していたため、複雑な動きの指示が困難でした。また、登場人物が画面外に消えた後に再登場するシーンでは外見が別人のように変わってしまう問題も看過できません。WorldDirectorはこれら二つの課題を正面から解決することを目指した研究です。
WorldDirectorの全体設計
WorldDirectorの核心は、「意味的な動き制御」と「視覚的な画像生成」を明確に分離する設計にあります。LLMが3Dの物体軌跡とカメラ動作を計画し、その計画を2Dの位置情報に変換してから動画生成モデルに渡す、という二段階の流れをとります。
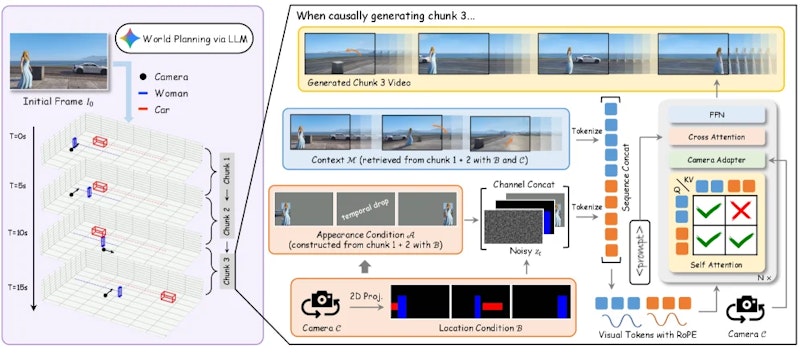
動画生成モデルへの入力は3種類の条件で構成されています。まず位置条件(Location Condition)は、各フレームにおけるオブジェクトの位置をバウンディングボックス(物体を囲む矩形の枠)として色分けしたもので、空間的な配置を制御します。次に外観条件(Appearance Condition)は、コンテキストフレームから取得したRGBの特徴量を用いてオブジェクトの見た目を保持する役割を担います。3つ目のコンテキストメモリ(Context Memory)は過去のフレームを参照することで、長期にわたる視覚的一貫性を保証します。これら3種類の条件はチャンネル方向またはシーケンス方向に結合され、生成モデルへ同時に入力されます。
LLMによる3D軌跡制御
WorldDirectorはGeminiを活用して、ユーザーのテキスト指示を3Dバウンディングボックスの軌跡とカメラの動きへと変換します。「犬が走って木の後ろに消え、5秒後に反対側から現れる」といった自然言語の指示が、フレームごとの具体的な3D座標として出力されます。生成された軌跡は透視変換によって2D座標に投影され、動画生成モデルへの確定的な制御信号となります。
この仕組みにより、物理的に妥当な動き計画をLLMが担い、ピクセルレベルの描画は別のモデルが担うという明確な役割分担が実現されました。さらに「テンポラルドロップ(Temporal Drop)」という技術も採用されており、最初の16フレームを過ぎると6フレームごとに1フレームのみを外観参照として利用します。これによってモデルがテキスト指示に従った自然な動きを生成するよう促され、この機構を取り除いた実験ではキャラクターが滑るように不自然に移動する現象が確認されています。
永続的動的オブジェクトメモリ
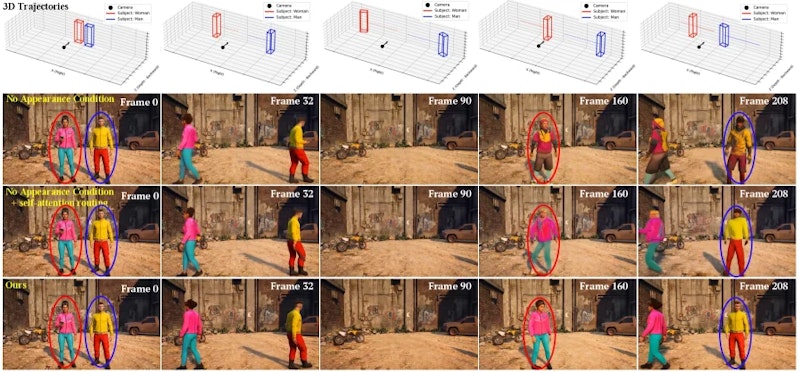
WorldDirectorの最大の特徴が「永続的動的オブジェクトメモリ」です。オブジェクトが画面外に消えた後も外観情報を記憶し続け、再登場時に同一の外見を維持します。従来のモデルでは一度フレーム外に退場したキャラクターが別人のように描画されていましたが、この仕組みによって長時間のシーンでも一貫した映像が生成できるようになりました。
実装上の重要な工夫として、非対称注意マスク(Asymmetric Attention Mask)が導入されています。生成中のフレームはコンテキストメモリを参照できますが、逆方向の情報伝達は遮断されるため、ノイズを含む生成途中の状態がクリーンな記憶を汚染しません。動画生成は「因果的チャンク生成」という方式で行われ、前のチャンクの境界フレームを引き継ぎながら次のチャンクを逐次的に(自己回帰的に、つまり前の出力を次の入力として使いながら)生成していきます。静的な背景と動的なオブジェクトの両方を対象とするデュアルストリーム選択戦略により、静止した景色とキャラクターの動きが共存する複雑なシーンでも安定した出力が得られます。
テキスト指示によるシーン生成
WorldDirectorは「Promptable World Events」と呼ばれる機能も備えています。ユーザーがテキストでシーンのイベントを指示すると、LLMが物体の軌跡とカメラワークを自動計画し、複数の登場人物が絡み合う複雑な場面を長尺で生成できます。例えば「街中を走り去る自動車と、それを見送る歩行者」のような状況を自然言語だけで指定できるため、スクリプトを書かずにシーンを演出できます。
この機能の背後では、LLMが初期フレームから推定した3D空間上の位置を起点に物理的に整合のとれた軌跡を計画し、その軌跡に基づいたバウンディングボックス列が動画生成モデルへ渡されます。意味的な判断(誰がどこへ向かうか)と視覚的な生成(その動きをどう描くか)が分離されているため、LLMの推論能力を最大限に活かせます。
実験結果
WorldDirectorはHyDRAとInfinite-Worldを主要なベースラインとして比較評価されました。定量評価にはPSNR(高いほど画質が高い)・SSIM(高いほど構造的類似性が高い)・LPIPS(低いほど知覚的品質が高い)という画像品質の標準的な指標が用いられています。
手法 | PSNR ↑ | LPIPS ↓ | DSC_DINO ↑ |
|---|---|---|---|
WorldDirector | 18.127 | 0.359 | 0.769 |
HyDRA | 13.421 | 0.439 | 0.632 |
Infinite-World | 14.574 | 0.406 | 0.773 |

PSNRでは18.1対13.4と約35%の差をつけ、LPIPSでも0.359対0.439と知覚品質で上回りました。オブジェクトの同一性を測るDSC_DINOはInfinite-Worldとほぼ同等ながら、他の画質指標では大きく上回る結果となっています。
アブレーション実験では、外観条件を取り除いた場合にDSC_DINOが0.769から0.693まで低下することが確認されました。背景が動的オブジェクトより広い面積を占める映像では、モデルが動的領域の一貫性を暗黙的に学習するのは難しく、外観条件の明示的な入力が欠かせないと分析されています。またストリーミング動画生成の推論効率も実用化に向けた重要な指標であり、今後の研究との組み合わせが期待されます。
まとめと今後の展望
WorldDirectorはLLMによる3D軌跡計画と永続的動的オブジェクトメモリを組み合わせることで、制御性と長期的一貫性という二つの課題を同時に解決しました。意味的な動き制御と視覚生成を分離した設計は、ゲームNPC制御・自律走行シミュレーション・ロボット学習環境への応用に向けた強固な基盤を提供しています。
一方で論文では、訓練データに含まれない極端なカメラ動作への対応や、非常に長時間のシーンにおける記憶の忠実性については今後の課題として挙げられています。プロジェクトページでは生成動画のサンプルも公開されており、実際の動作を確認できます。LLMと動画生成を組み合わせた制御可能な世界モデルというアプローチは、今後さらに多くの研究が取り組む方向性の一つとなりそうです。







