
- VLMで影響領域を特定し、ビデオ拡散モデルで反事実的シーンを生成
- 衝突や接触などの物理的インタラクションの因果連鎖ごと除去
- KubricとHUMOTOで生成したペアデータセットで学習
研究の背景
動画から不要な物体を削除する技術は、映像制作やVFXにおいて重要な役割を果たしています。従来の動画オブジェクト削除手法は、物体の「背後」にあるコンテンツを補完したり、影や反射といった外観レベルのアーティファクトを修正することには優れていました。
しかし、削除する物体が他の物体と衝突したり接触したりする場合、従来手法では物理的な整合性を保つことができませんでした。例えば、ボールを蹴る人物から人物だけを削除すると、ボールが宙に浮いたまま不自然に動く映像になってしまいます。このような物理的インタラクションの因果連鎖を正しく処理することが、動画編集における大きな課題でした。
VOIDの仕組み
VOIDは、物体削除を反事実的(物体が最初から存在しなかった場合の仮想的な)シーン生成として定式化することで、この課題を解決します。システムは3段階のパイプラインで動作します。
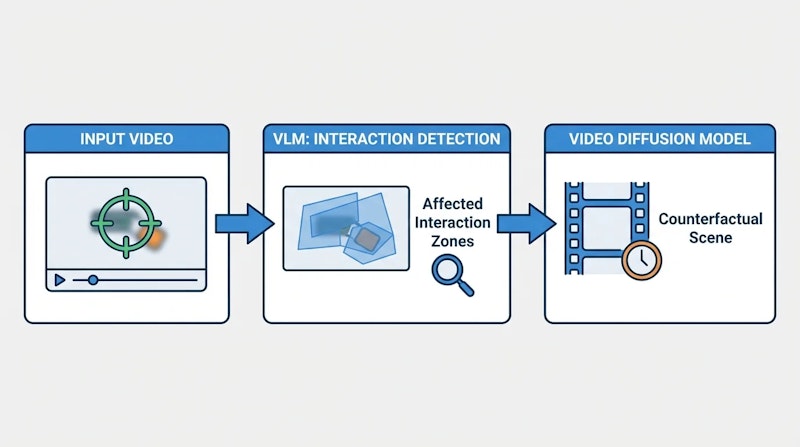
まず、Vision-Language Model(VLM)が削除対象の物体によって影響を受けるシーンの領域を分析します。衝突や接触が発生している箇所、重力や慣性の法則に基づいて変化すべき領域が特定されるのです。次に、特定された影響領域の情報が、ビデオ拡散モデルへのガイダンスとして使用されます。最終的に、拡散モデルが物理法則に沿った反事実的な映像を生成し、物体が最初から存在しなかった場合の自然なシーンが実現されます。
モデルの学習には、KubricとHUMOTOを使用して生成された新しいペアデータセットが用いられます。このデータセットでは、物体を削除すると下流の物理的インタラクションが変化する必要があるシナリオが含まれており、因果推論の能力を獲得できます。
従来手法との比較
VOIDの性能は、合成データと実データの両方で評価されました。従来の動画オブジェクト削除手法は、主に背景のインペインティングと外観アーティファクトの修正に焦点を当てていたため、物理的インタラクションが関与する複雑なケースでは不自然な結果を生成していました。
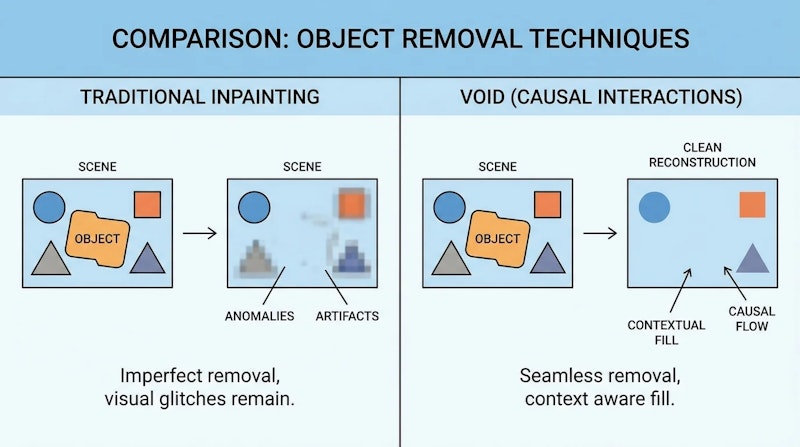
実験結果は、VOIDがオブジェクト削除後のシーンダイナミクスをより適切に保持することを示しています。特に、衝突や接触を伴うシーンにおいて、VOIDは物理的に整合した結果を生成できる一方、従来手法では物体の動きが不自然になったり、重力法則に反する現象が発生したりする問題が確認されました。著者らは、この手法が動画編集モデルを高レベルの因果推論を通じてより良い世界のシミュレーターにする可能性を示唆しています。
関連する動画生成技術として、PackForcingとは?5秒学習で2分動画を生成する24倍時間外挿フレームワークも注目されています。
まとめと今後の展望
VOIDは、動画からの物体削除を単なる背景補完ではなく、物理的インタラクションの因果連鎖を含めた反事実的シーン生成として捉え直すことで、従来手法の限界を克服しました。VLMによる影響領域の特定とビデオ拡散モデルによる反事実生成の組み合わせにより、物理法則に沿った自然な編集が可能になります。
この技術は、映像制作やVFX、コンテンツ配信における編集効率の向上に貢献する可能性があります。今後、より複雑な物理的インタラクションへの対応や、リアルタイム処理への最適化が期待されるでしょう。GitHubでコードとデモが公開されており、第三者による検証が可能です。







