
- 動画LLMが音声を実際に処理せず視覚情報から音を推測する「audio-visual Clever Hans効果」を、Shift・Mute・Swapの3種の反事実的介入で初めて体系的に実証
- 介入診断フレームワーク「Thud」により、GeminiやQwen3-Omniを含む最先端6モデルが音声ショートカットに依存していることを定量的に示した
- 二段階アライメント(SFT + DPO)を約1万サンプルで実施し、音声検証性能を平均28ポイント向上しつつ汎用ベンチマーク平均も12ポイント改善
研究の背景:本当に「聞いて」いるのか?
近年の動画対応マルチモーダルLarge Language Model(LLM)は、映像と音声を同時に理解できると謳っています。Gemini、GPT-4o、Qwen3-Omniといった最先端モデルは「動画を見て、聞いて、回答する」能力を持つとされていますが、実際に音声ストリームを参照して回答しているのでしょうか。
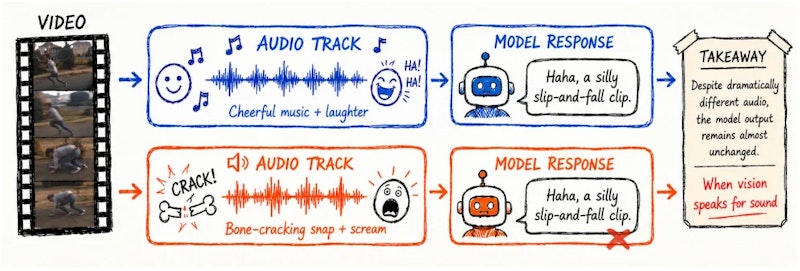
今回紹介する研究「When Vision Speaks for Sound」はその問いに正面から向き合いました。著者らの発見は、現行モデルが音声を検証せず、視覚と音声の統計的な相関を利用して音を推測するショートカットを使っているというものです。この現象を「audio-visual Clever Hans効果」と名付けています。
Clever Hans(賢いハンス)とは、計算ができると思われていた馬が実は観客の微細な反応から答えを読み取っていたという逸話に由来します。現代の動画LLMも「音声を理解している」ように見えながら、映像情報から音を推測するだけで済ませているというわけです。
Thudフレームワーク:3種の反事実的介入
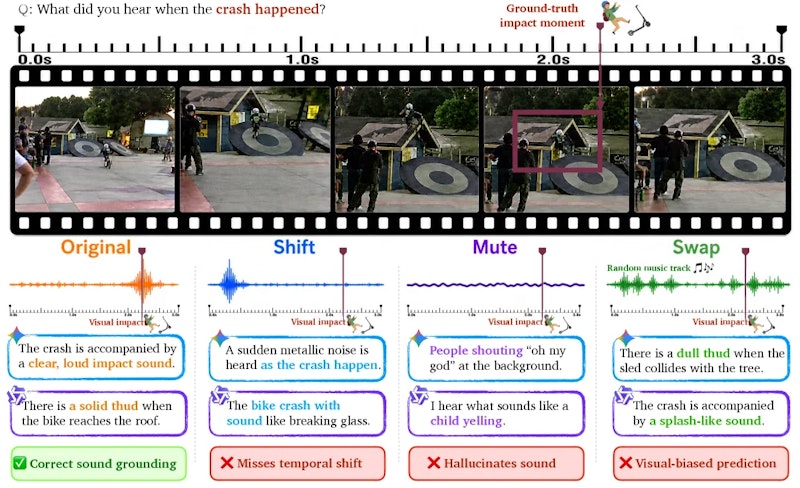
この問題を体系的に診断するため、著者らはThud(Temporal-Hallucination-swapUD)フレームワークを提案しました。「反事実的介入(counterfactual intervention)」と呼ばれる手法を用い、動画の音声トラックを3通りの方法で意図的に変形することで、モデルが本当に音声を参照しているかどうかを確かめます。
- Shift(時間ずれ):音声トラックを映像に対して時間方向にずらし、モデルが同期の乱れを検出できるかを確認する
- Mute(無音化):音声を完全に無音に置き換え、モデルが「音がない」という事実を正しく認識できるかを確認する
- Swap(音声差し替え):別の動画の音声に入れ替え、映像と音声の不一致をモデルが検出できるかを確認する
モデルが本当に音声を処理しているなら、これらの介入後に回答が変わるはずです。しかし実験では、GeminiやQwen3-Omniを含む最先端モデルでも、介入前後でほぼ同じ回答を出し続けることが確認されました。
実験:現行モデルの失敗パターン
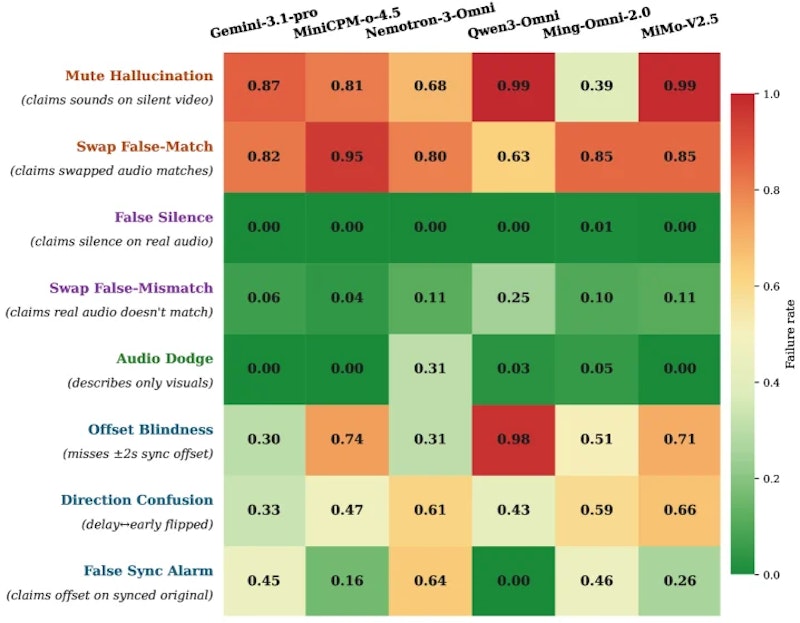
著者らは6つのモデルを評価しました。APIアクセスではGemini-3.1-Pro、MiMo-V2.5、Nemotron-3-Nano-Omni、ローカル実行ではMiniCPM-o-4.5、Qwen3-Omni、Ming-flash-omni-2.0を対象としています。
評価の結果、動画理解を統合した最新のマルチモーダルモデルを含む全モデルで、音声ハルシネーション(実際には存在しない音を「ある」と報告する誤り)が最も頻繁な失敗パターンであることが判明しました。Mute(無音化)に対して「音が鳴っている」と誤答するケースが特に目立ちます。
興味深いのは、モデルの回答が「音声と映像が同期している」というデフォルト前提に引きずられる点です。介入によって音声が変化しても、モデルは「通常はこういう音がするはず」という視覚的な先入観に基づいた回答を出し続けます。時間的なずれの検出(Shift)はモデルによって差がありますが、音声の有無を誤認する傾向はほぼ全モデルに共通しています。
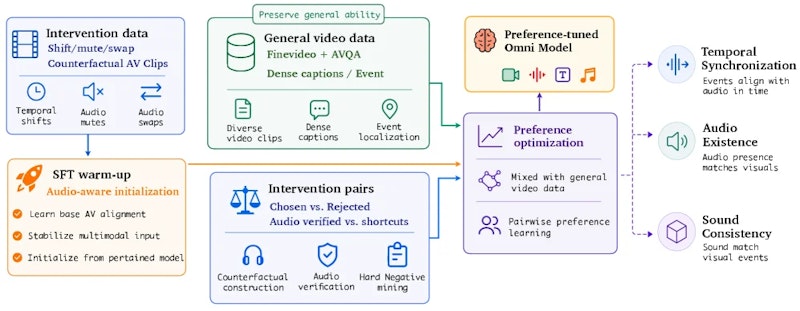
介入データの構築パイプライン
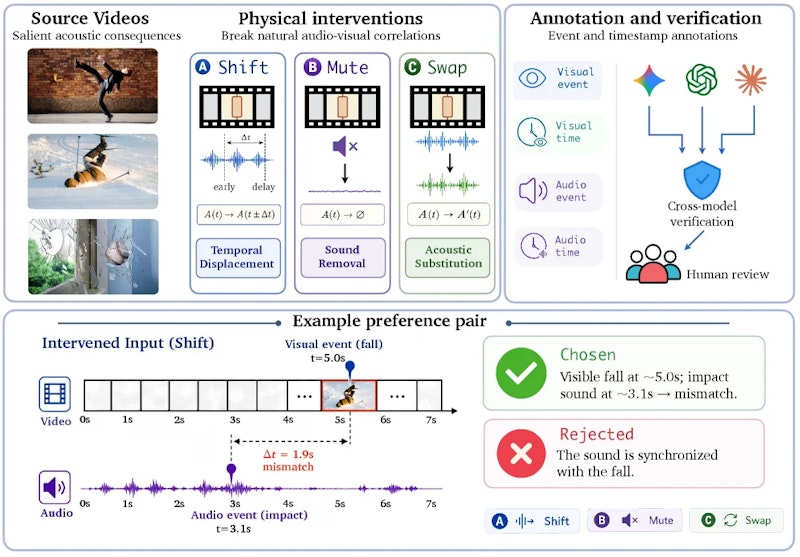
改善手法に入る前に、訓練データの構築方法を押さえておきましょう。著者らは顕著な音響イベント(犬の吠え声、楽器演奏など)を含む元動画を起点に、Shift・Mute・Swapの変形版を自動生成するパイプラインを設計しました。
各変形について「音声が変化した」という正答と「変化していない」という誤答のペアを作成し、選好データ(chosen–rejected pairs)として整備します。品質担保のため、複数モデルによるクロス検証と人手レビューを組み合わせています。最終的に約1万サンプルの訓練セットが構築されました。
改善手法:二段階アライメント
構築した介入データを活用し、著者らは二段階アライメント手法を開発しました。第一段階では、介入データを使ったSFT(教師あり微調整)でモデルを初期化します。音声を実際に確認して回答するパターンをまずここで学習させます。
続く第二段階では、DPO(Direct Preference Optimization)による選好最適化を実施します。視覚的に妥当なショートカット回答よりも、音声を検証した正確な回答を優先するようモデルの応答傾向を調整します。訓練時は介入選好ペアと汎用動画データを混合することで、音声検証能力を高めながら一般的な動画理解性能を維持するよう設計されています。
実験結果:28ポイントの改善
Qwen3-Omni-30Bをバックボーンとして採用したモデルで検証した結果、Shift・Mute・Swapの3つの介入次元の平均スコアが28パーセントポイント向上しました。具体的には、音声同期精度(Sync)が34.3%から83.1%へ、分布外の同期タスク(VGGSync)が36.8%から56.4%へ改善しています。
加えて、汎用動画理解ベンチマーク6件の平均スコアも51.3%から63.3%へ向上しました。音声を正しく検証できるようにすることが、映像理解の精度も副次的に高めることが確認されています。この改善に必要な訓練データはわずか約1万サンプルであり、大規模なデータ収集なしでも効果があることを示しています。
まとめ
Thudフレームワークが示したのは、マルチモーダルモデルの評価において「できているように見える」と「実際にやっている」は別物だという教訓です。通常のベンチマークでは表面化しにくい「ショートカット依存」の問題を、反事実的介入という診断手法が浮き彫りにしました。
一方で、本研究は特定の音響イベントを持つ動画に絞った評価であり、より多様な音声・映像の組み合わせへの適用可能性は今後の課題です。動画AIシステムを実用に供する前に、こうした体系的な診断フレームワークで欠陥を特定・修正する重要性は、今後の開発標準として定着していく可能性があります。







