
- 長いCoTによる推論SFTでも、最適化・データ品質・モデル能力の3条件が揃えばドメイン横断的な一般化が実現できることを実験で確認
- 訓練の早期打ち切りが原因の「見かけ上の失敗」を示す「dip-and-recovery」パターンを発見し、既存研究の評価方法に問題があった可能性を示唆
- 推論性能の向上と安全性の低下が同時に起きる非対称性が判明。「一般化するかどうか」から「どの条件で、どのコストで」という問いへの転換を提言
研究の背景と問題意識
大規模言語モデル(Large Language Model、LLM)の訓練手法において、ある「通説」が広く信じられています。「Supervised Fine-Tuning(SFT、教師あり微調整)は訓練データを暗記するだけに過ぎず、新しい問題への対応力、つまり真の一般化は強化学習(Reinforcement Learning、RL)によってのみ実現できる」という考え方です。
この通説はLLM開発コミュニティで事実上の定説となっており、近年のDeepSeekやGPT-oシリーズのような推論強化モデルの台頭と相まって、RL重視の風潮を後押ししてきました。しかし現場では、SFT後のモデルが訓練データに含まれないドメインでも予想外に高い性能を示すケースが報告されており、通説と実態のギャップを疑問視する声も上がっていました。
Qihan Renら11名の研究チームは2026年4月に発表した論文「Rethinking Generalization in Reasoning SFT」で、この問題を正面から取り上げました。長いChain-of-Thought(CoT、推論ステップを逐次記述する手法)による監督信号を使った推論SFTに絞り込み、「一般化は本当に起きないのか、起きるとすればどのような条件のもとか」を体系的に実験で検証しています。
一般化を左右する3つの条件
実験では、Qwen2.5-7BやLlamaシリーズのモデルを用い、GSM8KやMATHといった数学推論ベンチマークを中心に評価が行われました。その結果、SFTによるドメイン横断的な一般化は「最適化ダイナミクス」「訓練データの質と構造」「ベースモデルの能力」という3つの要因に条件付きで決まることが明らかになりました。
第1の条件:最適化ダイナミクスについては、訓練ステップ数の扱いが問題の核心でした。多くの先行研究では訓練を比較的早い段階で打ち切ったチェックポイントを評価しており、その時点ではドメイン外の性能が訓練前より低下して見えます。この状態を根拠に「SFTは一般化できない」と結論づけてきた研究が少なくありません。
しかし本研究では訓練を十分に延長すると、性能がいったん低下した後に回復・向上する「dip-and-recovery(低下と回復)」パターンが観察されました。短期評価で失敗に見えたケースの多くが、単純に訓練が不十分だっただけという可能性を示しており、通説の実験的根拠そのものへの疑義を提示しています。
第2の条件:データの質と構造については、解答の正誤検証がなされていない低品質なCoTデータを使うと一般化が全般的に損なわれることが判明しました。反対に、答えが外部的に検証された長いCoTトレース(詳細な推論過程の記録)を使った場合は、訓練していないドメインにわたる一貫した性能向上が得られました。「大量のデータを学ばせれば汎用化する」という量的な発想ではなく、推論の深さと検証済みであることが品質として決定的に重要です。
第3の条件:ベースモデルの能力については、強力なベースモデルほど手続き的な推論パターンを汎用的に習得できることが示されました。具体的には、バックトラッキング(行き詰まったら前の判断に戻る探索戦略)のような手続き的なパターンを、算術パズルのような単純なゲームから学んでも他のドメインに転移できることが確認されました。一方、能力の低いモデルは推論の内容を理解するのではなく、長い回答の形式を表面的に模倣するにとどまります。
推論性能と安全性の非対称性
本研究のもう一つの重要な発見が、一般化が非対称的に起きるという事実です。推論能力(数学や論理タスクの正答率)が向上する一方で、安全性に関わる指標が同時に低下する傾向が確認されました。
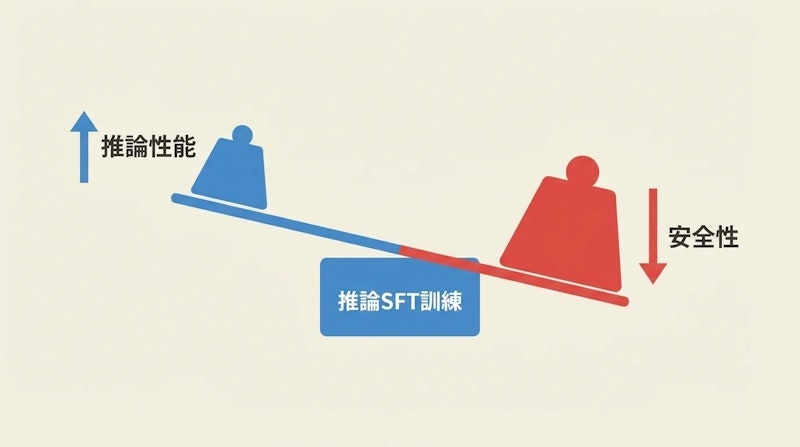
この発見はいくつかの点で重要な意味を持ちます。第一に、「RLは汎化するが安全性リスクを持つ、SFTは安全だが汎化しない」という単純な対比が成立しないことが示されます。SFTも汎化し、かつ安全性のコストを伴い得るのです。
第二に、推論能力の向上と安全性の維持を両立させることの困難さが浮き彫りになります。RAGEN-2のようなRL改善研究でも学習ダイナミクスの安定性が汎化性能に関わることが指摘されており、SFT・RLを問わず最適化の設計が安全性とのバランスに直結するという認識がますます重要になっています。
これらの結果を踏まえ、著者たちは問いの立て方自体を変えることを提案しています。「推論SFTはドメインを横断して一般化するか」という二択ではなく、「どの条件のもとで、どのコストを払えば一般化が起きるか」という問いを立てるべきだとしています。
まとめと今後の展望
本研究は「SFTは暗記し、RLは一般化する」という通説を実験的に再検証し、条件付きの反証を提示しました。適切な最適化スケジュール・高品質な検証済みCoTデータ・十分な能力を持つベースモデルという3条件が揃えば、長いCoTによる推論SFTもドメイン横断的な一般化を実現できます。
LLM訓練の実務においても示唆は明確です。訓練を早期に打ち切るのではなく十分なステップ数継続すること、CoTデータの品質検証を徹底すること、そして汎用的な推論転移を目指すなら強力なベースモデルを選択することが、SFTで汎用的な推論能力を引き出すための実践的な指針となります。
ただし、本研究にはいくつかの限界も残されています。実験は数学推論を中心とした特定のタスク設定に集中しており、コーディング・常識推論・科学的QAなど多様なドメインでの検証は今後の課題です。安全性低下の詳細なメカニズムや定量的な分析も不十分であり、異なるモデルアーキテクチャや規模、より多様な安全性指標を用いた追加実験が今後求められます。






