
- エントロピーが安定していてもモデルが固定パターンに依存する「テンプレート崩壊」を新しい失敗モードとして定義し、既存指標の盲点を明らかにした
- バッチ内交差スコアリングによる相互情報量(MI)プロキシが、テンプレート崩壊を正確に検出し最終性能と+0.39の相関を示した
- SNR-Awareフィルタリングにより、プランニング・数学推論・Webナビゲーション・コード実行の4領域で平均6.9%の性能向上を実現
研究の背景
大規模言語モデル(LLM)のエージェント能力を高める手段として、強化学習(Reinforcement Learning、RL)による訓練が広く研究されています。エージェントが自律的にタスクを解決できるよう、試行錯誤を通じて推論パターンを学習させる手法です。
この訓練の健全性を評価する指標として、従来はエントロピー(応答の多様性)が用いられてきました。エントロピーが高ければ、モデルが多様な推論を生成できている証拠とみなされていたのです。しかし、Stanford大学・ワシントン大学・Microsoftなどの研究者が集結したRAGEN-2プロジェクトは、この前提に根本的な問題があることを発見しました。
テンプレート崩壊とは
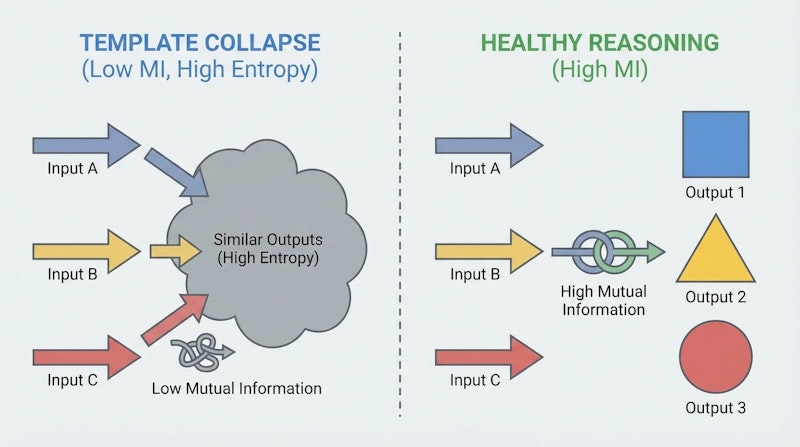
RAGEN-2が定義する「テンプレート崩壊(Template Collapse)」は、エントロピーの数値が安定しているにもかかわらず、モデルが入力の内容に関係なく固定的な思考パターンを繰り返す現象です。
具体例を挙げると、数学問題に対して「まず問題を分析し、次に条件を整理し、最後に解を求める」という形式で答えているように見えても、実際にはどんな問題に対しても同じ表面的な構造が使われている状態です。多様性があるように見えて、実は入力の違いを推論に反映できていないのです。
論文ではこの状態を、条件付きエントロピー H(Z|X) は高い(同じ入力内での応答は多様)が、相互情報量 I(X;Z) は低い(異なる入力間で推論が区別できない)状態として形式化しています。
相互情報量プロキシによる診断
テンプレート崩壊を検出するために、RAGEN-2はバッチ内交差スコアリングという手法で相互情報量の代理指標(MIプロキシ)を計算します。P個の入力とそれぞれG個の推論サンプルから、あらゆる(推論、入力)の組み合わせに対して対数尤度を計算し、「自分の入力に対応した推論スコア」と「他の入力に対応した推論スコア」の差を指標化します。
評価指標として「Retrieval-Acc」が提案されています。これは「ある推論が最も高いスコアを示す入力が、その推論を実際に生成した入力と一致しているか」を測定するものです。テンプレート崩壊が起きているモデルでは、この精度がランダム(バッチサイズ64なら約1.56%)付近まで低下することが確認されました。
相関分析の結果、MIプロキシは最終的なタスク性能と+0.39の正の相関を示しました。一方、従来のエントロピー指標は-0.11から-0.14の負の相関を示しており、エントロピーを高めようとする施策が実際には性能低下をもたらす可能性があることが示唆されています。また、連続値の推定にはz-score正規化と指数移動平均を組み合わせた「MI-ZScore-EMA」も提案されています。
SNR-Awareフィルタリング
テンプレート崩壊の発生メカニズムとして、論文は信号対雑音比(SNR)の問題を指摘します。RL訓練において、入力ごとの報酬の分散が低い場合、入力の違いを区別する勾配信号が弱くなります。その結果、入力に依存しない正則化項が支配的になり、モデルが入力を無視した固定パターンに収束してしまうのです。
これを解決するSNR-Awareフィルタリングは、各イテレーションで報酬の分散を計算し、分散が大きい(つまり入力の難易度差が明確な)プロンプトのみを選んでパラメータ更新に使用します。分散の小さいプロンプトを除外することで、常に十分な勾配信号を持つデータでモデルを訓練できます。
この手法の計算コストは軽微で、報酬分散の計算で追加コストは0.1%未満です。フィルタリングによって勾配計算が不要なプロンプトを除外するため、むしろ1イテレーションあたりの計算コストが26〜41%削減されるという副次的な効果もあります。エージェント型RL訓練のさらなる発展については、CORALとは?自律マルチエージェント進化で探索問題の改善率を最大10倍に高める新フレームワークも参考になります。
実験結果
RAGEN-2は、Sokoban・FrozenLake(プランニング)、MetaMathQA・Countdown(数学推論)、WebArena(Webナビゲーション)、SWE-bench(コード実行)などを含む7つの環境で評価されました。SNR-Awareフィルタリングを適用した結果、7環境の平均で6.9%の性能向上が確認されました。
タスク別の結果を見ると、Sokobanでは基準値12.9%から16.0ポイント改善、FrozenLakeでは67.0%から10.9ポイント改善と、プランニング系タスクで顕著な効果が見られます。MetaMathQAのような数学推論でも0.6ポイントの改善があり、すでに高い性能水準でもさらなる向上の余地があることを示しています。
また、MIプロキシを訓練中の監視指標として用いることで、テンプレート崩壊の発生を早期に検知できることも示されました。Retrieval-Accが訓練中に急低下するタイミングと、最終性能が頭打ちになるタイミングが一致することが観察されています。
まとめと今後の展望
RAGEN-2は、エージェントRL訓練の品質評価において、エントロピーという広く使われてきた指標に重大な盲点があることを示しました。テンプレート崩壊は既存の監視では見過ごされてきた問題であり、その検出と修正に有効な手法が提示されています。
MIプロキシとSNR-Awareフィルタリングはどちらも軽量な手法であり、既存のRL訓練パイプラインへの組み込みも容易です。GitHubで公開されているコードが2.6kのスターを集めているという事実も、実践的な有用性の高さを示しています。
今後の課題としては、MIプロキシの計算が現状バッチ内の比較に依存しているため、バッチサイズが小さい場合の推定精度の問題が残ります。より大規模なモデルや長いコンテキストを持つタスクへの適用についても、引き続き検証が必要です。LLMエージェントの訓練に取り組む開発者にとって、テンプレート崩壊という概念は今後の標準的な検査項目になる可能性があります。







