
- 初期推論ステップのエラーが後続全体に連鎖する「連鎖失敗」を定量化し、初期エラー率を64.0%から13.0%に削減
- ステップ位置に比例した指数ペナルティにより、Qwen3-VL-8BがHuatuoGPT-Vision-34Bを2.79ポイント上回る高効率化を達成
- 3種のバックボーン・複数データセットで安定した改善を示し、医療以外の段階的推論タスク全般への応用も期待される
研究の背景
医療画像VQA(Visual Question Answering)は、「このX線にどのような所見がありますか」といった問いに対してAIが推論を組み立てて回答するタスクです。近年はマルチモーダルLLM(テキストと画像を同時に扱う大規模言語モデル)の発展により精度が向上してきましたが、学習パイプラインには根本的な課題が残っていました。
従来の強化学習手法は最終回答の正否のみを学習の信号(報酬)として使用します。これは「疎なクレジット割り当て(sparse credit assignment)」問題と呼ばれ、どの推論ステップが誤りを招いたかをモデルが特定できないため、改善が最終段階に偏る傾向があります。ソウル大学の研究チームはこの課題を掘り下げ、問題の本質が「推論チェーンの初期ステップのエラー」にあることを突き止めました。
連鎖失敗の実態
研究チームはまず、医療VQAにおける推論失敗のパターンを体系的に調査しました。推論チェーン全体のどの位置で最初のエラーが発生したかを示す指標として「FFP(First Failure Point: 初回失敗位置)」を定義し、ベースラインモデルの推論パスを分析しました。
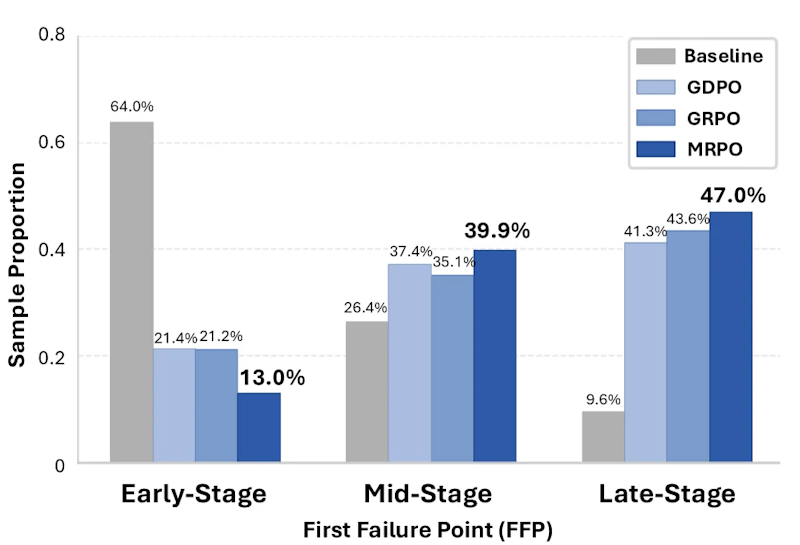
分析の結果、ベースラインモデルでは64.0%のケースで推論チェーンの初期段階(Early: 全体の前40%以内)にエラーが発生していました。初期にエラーが起きると、後続のすべてのステップがその誤りを前提として積み上がるため、修正が困難になる「連鎖失敗」が生じます。さらに「FAR(Failure Accumulation Rate: 失敗蓄積率)」という指標の分析から、初期エラーほど後段への波及が大きいことが定量的に確認されました。
MRPOの設計
この知見をもとに提案されたのが、MRPO(Medical Reasoning-aware Policy Optimization)です。GRPOというRL手法をベースに、「どのステップが失敗したか」「そのステップは推論チェーンの何番目か」という2つの情報を報酬設計に組み込んでいます。
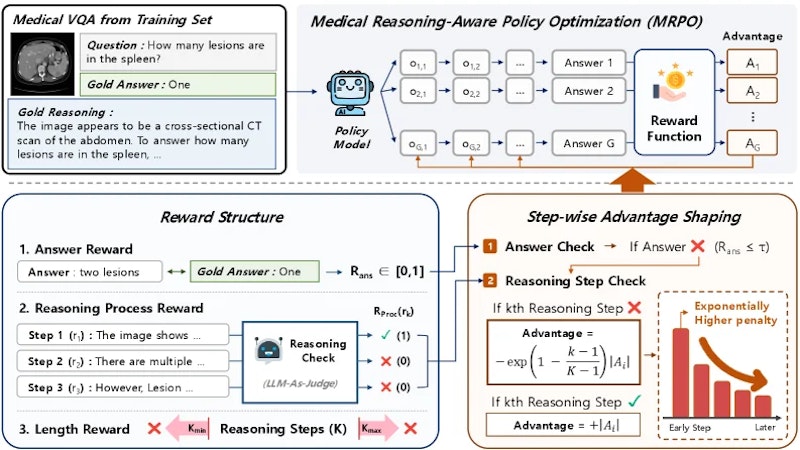
報酬は3つの要素で構成されます。回答報酬は字面一致(ROUGE-1、BLEU-1)と医療ドメイン特化のBERTScoreによる意味的類似度を組み合わせて評価します。プロセス報酬は各推論ステップが「正解の根拠と整合しているか」「正しい結論を導いているか」の2基準でバイナリ評価します。長さ報酬は推論ステップ数が4〜10の適切な範囲に収まるよう線形ペナルティを付与し、過不足のない推論を促します。
核心となるのが指数ペナルティの設計です。最終回答が誤りかつあるステップが無効と判定された場合、そのステップのトークンにはステップ位置 k と総ステップ数 K を用いた式 −exp(1 − (k−1)/(K−1)) に比例したペナルティが付与されます。推論チェーンの最初に近いステップほど大きなペナルティを受けるため、連鎖失敗の根本となる早期エラーの修正に学習が集中する仕組みです。
実験結果
Qwen2.5-VL-7B、Qwen3-VL-8B、InternVL3-8Bの3モデルに対して、医療VQAの6データセット(VQA-RAD、SLAKE、PathVQAほか)で評価を実施しました。GRPOを改善する視覚推論手法と同様の比較軸で、ベースラインのGRPOや教師ありファインチューニングを上回る精度を全バックボーンで確認しています。
Qwen3-VL-8B-InstructにMRPOを適用した場合の平均スコアは28.94で、GRPOの28.69を上回りました。さらに、パラメータ数が4倍以上大きいHuatuoGPT-Vision-34B(26.15)を2.79ポイント上回る結果も示されています。InternVL3-8BではGRPO比で1.10ポイントの改善を記録し、モデルの種類を問わず安定した向上を確認しました。
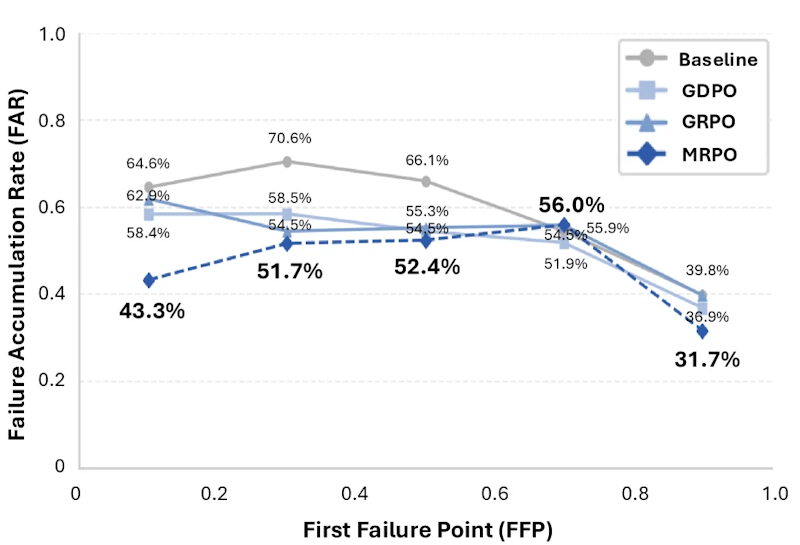
FFP分析では、初期段階(Early)のエラー率がベースラインの64.0%からMRPOでは13.0%に低下しました。一方、後段(Late-Stage)の割合は9.6%から47.0%に増加しており、エラーが連鎖する前の段階での失敗割合が下がり、問題が後段に移ったことを示しています。FARの比較でもMRPOは全FFP区間で最低値を記録し、連鎖失敗の抑制効果が定量的に確認されました。人手評価でもCohen's κ = 0.717の高い一致率が得られており、評価の信頼性も担保されています。
まとめ
MRPOは、医療VQA特有の「初期推論エラーが連鎖して全体の失敗を招く」問題に対し、ステップ位置を考慮した指数ペナルティで直接介入するRL手法です。8Bクラスのモデルで34Bモデルを上回る精度を実現した点は、計算コスト面でも実用的な意義があります。
GRPOをベースとした設計上、段階的推論が前提となるタスクであれば医療分野以外にも応用できる汎用性があります。コードはdmis-lab/MRPOでオープンソース公開されており、再現実験が行いやすい環境が整っています。







