
- Flex TierはStandard APIの50%引きで提供(Googleの公式発表値)。遅延を許容できるバックグラウンド処理やエージェントワークフローに最適化されている
- Priority TierはTier 2/3有料プロジェクト向け。ピーク時でも最高信頼性を確保し、制限超過時はStandardに自動フォールバックする
- どちらも
service_tierパラメータ1つで切り替え可能。非同期Batch APIの複雑なファイル管理やポーリングが不要になる
2つの新Tierで何が変わるか
Googleは2026年4月2日、Gemini APIに新たな推論Tier(Inference Tier)として「Flex」と「Priority」を追加しました。これまでAI開発者がコスト最適化と低遅延を両立しようとすると、標準の同期APIと非同期のBatch APIを別々に管理する必要がありました。今回の追加により、単一の同期エンドポイントを使いながらTierを切り替えるだけで、コスト削減と信頼性確保の両方を実現できます。
背景には、AIがシンプルなチャットから複雑な自律エージェントへと進化しているという文脈があります。アプリケーション内には「即座の返答が不要なバックグラウンド処理」と「ユーザー向けリアルタイム機能」が共存します。これら2種類の処理を1つのAPIで最適に扱う仕組みが今回のTier分けです。
Flex Tier — 50%割引のコスト優先設定
Flex Tierは、Standard APIと比較して料金が50%引きになるコスト最適化Tierです(Googleが公式発表した数値)。リクエストの優先度を下げる代わりにコストを削減する設計で、応答には若干の遅延が生じます。2026年4月時点で全ての有料Tierのユーザーを対象に提供されており、GenerateContent APIとInteractions APIのリクエストに対応しています。
従来の非同期Batch APIとの大きな違いは、Flexが同期インターフェースである点です。入力/出力ファイルの管理やジョブ完了のポーリングが不要で、既存のコードにservice_tierパラメータを追加するだけで利用を開始できます。主なユースケースとしては、CRMのバックグラウンド更新、大規模なリサーチシミュレーション、そしてモデルがバックグラウンドで検索・推論を行うエージェントワークフローが挙げられます。
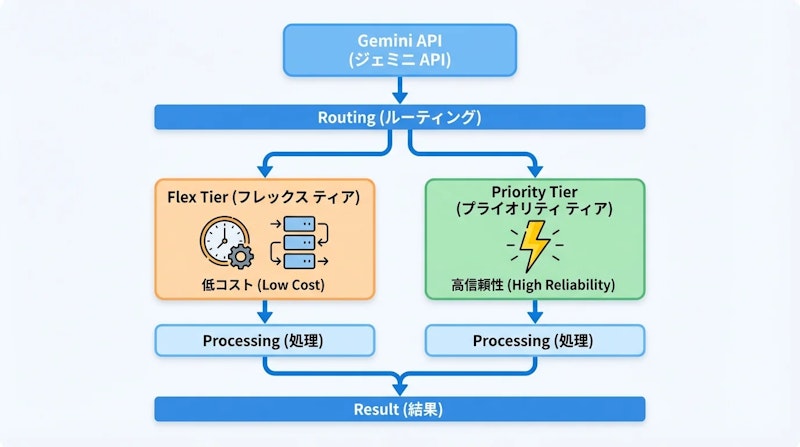
Priority Tier — ピーク時も信頼性を確保
Priority Tierは、プレミアム価格で最高レベルの信頼性を提供するTierです。Priorityリクエストは高い優先度で処理され、ピーク時の負荷が高い状況でもプリエンプト(割り込み)されません。加えて、トラフィックがPriority制限を超えた場合でも、リクエストが失敗するのではなくStandard Tierに自動でフォールバックする「グレースフルダウングレード」機能を備えています。APIレスポンスには実際にどのTierで処理されたかが明示されるため、パフォーマンスと請求内容を透明に把握できます。
Priority Tierは、Tier 2またはTier 3の有料プロジェクトを対象として提供されています。GenerateContent APIとInteractions APIエンドポイントで利用可能です。リアルタイムのカスタマーサポートボット、ライブのコンテンツモデレーションパイプライン、時間的制約の厳しいリクエスト処理に適しています。Priority Tierの具体的な料金倍率はモデルやTierによって異なるため、Gemini API公式ドキュメントの料金ページでの確認が必要です。
APIの使い方と実装例
FlexとPriorityのどちらも、APIリクエスト時にservice_tierパラメータを指定するだけで利用できます。既存のアーキテクチャを大きく変更する必要はなく、パラメータ1つで切り替えが完了します。コード例は公式のGemini cookbookで公開されており、実装の参考になります。
他のAIプロバイダーでも同様の動きはあり、OpenAIが2024年4月に提供を開始したBatch APIなどがコスト削減手段として知られています。ただしBatch APIは非同期処理であり、入出力ファイルの管理やポーリングが必要でした。GeminiのFlex Tierは同期エンドポイントを保ちながらコストを半減できる点で、開発工数も合わせて削減できます。
開発者への実践的な影響
AIエージェントが複数のAPIを連続して呼び出す構成では、ユーザーへの応答に直接影響する呼び出しにはPriorityを、内部的な情報収集や推論ステップにはFlexを割り当てることで、コストと品質の両方を最適化できます。例えば、ユーザーが待機しないバックグラウンドでのデータ加工や分類処理はFlexに、ユーザーが結果を待つリアルタイム回答はPriorityまたはStandardに振り分けるという設計が現実的な選択肢になります。
Googleは同日、エージェント対応を強化したオープンモデル「Gemma 4」も発表しており、これらを組み合わせた活用が今後のAIアプリ開発の選択肢として広がりそうです。単一の統合インターフェースでコストと信頼性を柔軟に管理できるというアプローチは、本番環境での運用コスト削減に直接つながります。





