
- 消去ゲート(b_t)と書き込みゲート(w_t)をチャネル単位で独立させ、固定サイズメモリ行列の編集精度を大幅に改善
- 1.3B・100Bトークン学習でMamba-2・KDA・Gated DeltaNetを常識推論・言語モデリング全般で上回り、平均精度53.11%を達成
- 長文脈RULERベンチマークのシングルキー検索で93.0%、ハイブリッド設定では42.28%を達成してTransformerの38.07%を超える
研究の背景
大規模言語モデル(LLM)の推論では、過去のトークンをどのように記憶するかがモデルの能力を大きく左右します。Transformerは入力の全トークン間の注意を計算するため、シーケンス長が増えるとメモリと計算量が二乗オーダーで増加するという根本的な制約があります。長文書の処理や長時間の会話を扱う実用的なシステムでは、このコストが深刻な問題となっています。
この課題への代替として、固定サイズの圧縮状態(メモリ行列)に情報を蓄積しながら逐次処理する線形注意(Linear Attention)ベースのモデルが注目を集めています。Mamba・DeltaNet・KDA(Key-Driven Attention)といった一連の手法がここ数年で提案されており、推論時のメモリ消費と計算量をシーケンス長に対して線形以下に抑えつつ、言語モデリング性能を着実に向上させてきました。
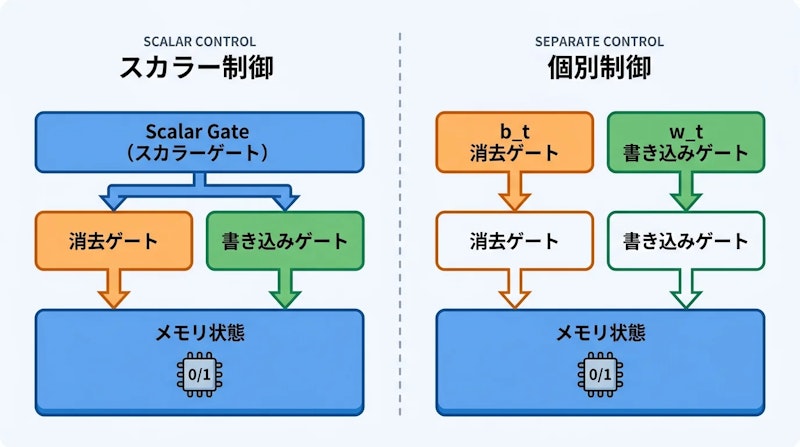
しかし、これらのモデルには共通の設計上の制約がありました。固定サイズのメモリ行列を更新する際に「古い情報を消去する」と「新しい情報を書き込む」という2つの役割を、単一のスカラー値ゲートで一括制御していたのです。スカラーゲートではすべてのチャネルに同一の制御量が適用されるため、チャネルごとに異なる記憶のパターンを学習することが難しく、メモリの活用効率に上限が生じていました。NVIDIAのNVlabs研究チームは、この「単一ゲート問題」こそが性能向上を妨げる根本原因と位置づけ、Gated DeltaNet-2を提案しました。
提案手法: ゲートの独立化
Gated DeltaNet-2の核心は、消去ゲート(b_t)と書き込みゲート(w_t)をチャネル単位で独立させる点にあります。元のDeltaNetではb_tはスカラー値であり、すべてのチャネルに同一の制御量が適用されていました。Gated DeltaNet-2ではb_tをベクトルに拡張し、各チャネルが独自の消去率を持てるようにしています。
この変更により、モデルは「どのチャネルの古い記憶をどれだけ消去するか」と「どのチャネルに新しい情報をどれだけ書き込むか」を完全に別々に学習できます。たとえば構文情報を保持するチャネルはゆっくり消去しつつ、話題の変化に敏感なチャネルは素早く上書きするといった、柔軟なメモリ管理が可能になります。アブレーション実験ではw_tをスカラーに戻すと精度が90.6%へ、b_tのスカラー化でも92.1%へと低下することが確認されており、両ゲートのベクトル化がそれぞれ独立して性能に貢献していることが実証されています。
設計の上で重要なのは、既存手法との後方互換性が保たれていることです。両ゲートが同じスカラー値に収束するとKDAと同等に、さらに減衰も一致させるとGated DeltaNetに簡約されます。Gated DeltaNet-2は既存の線形注意フレームワークの厳密な上位互換であり、設計の妥当性が理論的に裏付けられています。学習効率の面では、チャンク単位のWY(Woodbury-Yang)アルゴリズムとゲートを考慮した逆伝播を組み合わせることで並列訓練を実現しています。H100 GPUでの測定ではシーケンス長2Kから16KにかけてスループットがX 38.0から36.1 Kt/sとほぼ一定に維持されており、長いシーケンスでも計算コストが増大しない特性を確認しています。
実験結果
実験では1.3Bパラメータのモデルを100BトークンのFineWeb-Eduデータセットで学習し、Mamba-2・Gated DeltaNet・KDA・Mamba-3と比較しました。常識推論のゼロショットベンチマークでは、再帰型設定においてWinoGrande(57.85%)・ARC-Easy(72.43%)・HellaSwag(56.84%)・PIQA(72.80%)・ARC-Challenge(38.23%)を記録し、5タスクの平均精度53.11%で全比較モデルを上回りました。言語モデリングでもWikiText困惑度15.90・LAMBADA困惑度11.41と、既存モデルより優れた値を示しています。
長文脈評価のRULER(Realistic Universal Long-Context Evaluation)ベンチマークでは特に顕著な差が現れました。シングルキー検索タスク(S-NIAH)の4K文脈でGated DeltaNet-2は93.0%の精度を達成し、KDA(89.0%)・Gated DeltaNet(87.2%)を大幅に上回っています。複数の干渉キーが含まれるマルチキー検索タスク(MK-NIAH)では37.8%を記録しました。ハイブリッド設定(一部の層をスライディングウィンドウ注意に置き換えた構成)では実世界検索タスクで42.28%に達し、同設定のTransformerの38.07%を超える結果となっています。
また、KVキャッシュ量子化でメモリ効率を高めるOScaRのような推論最適化手法とGated DeltaNet-2を組み合わせることで、メモリ圧縮と記憶精度の両面から効率的なLLM推論を実現できる可能性もあります。
まとめと今後の展望
Gated DeltaNet-2は、線形注意モデルの性能向上を妨げていた単一ゲート問題を、チャネル単位のゲート分離という明快な設計変更で解決しました。変更箇所が限定的であるため既存の学習パイプラインへ組み込みやすく、GitHubでコードが公開されていることで再現性と応用のしやすさも確保されています。
今後の展望として、今回検証された1.3Bパラメータ以外のサイズ帯への拡張が自然な次のステップです。3Bや7Bといった大型モデルでは、チャネル数の増加に伴い独立ゲートの効果が一層発揮されると考えられます。ゲート分離によってチャネルごとの記憶制御が細かくなるほど、モデルが扱える情報の多様性が高まるためです。パラメータ規模が大きくなるほど、消去と書き込みの非対称な制御が学習全体にどう影響するかを検証することは、線形注意アーキテクチャの設計論として重要な知見をもたらすでしょう。
Gated DeltaNet-2のブロックをTransformerの自己注意層と交互に配置するハイブリッドアーキテクチャへの組み込みも有望な方向です。今回の実験でもハイブリッド設定がすべての評価指標で再帰型単独を上回っており、線形注意層の効率的なメモリ圧縮能力と自己注意層の精密な文脈参照を組み合わせることで、長文書処理・対話システム・文書検索など幅広い用途への応用が見込まれます。ゲートの独立化という比較的シンプルな変更が、線形注意ベースのLLMアーキテクチャ全般に応用できる設計改善として注目されています。





