
- わずか3〜30秒の参照音声から話者の声質をゼロショットで再現し、9言語の多言語音声クローニングに対応
- 意味的音声トークンの自己回帰生成とFlow Matchingによる音響生成を組み合わせた独自のハイブリッドアーキテクチャを採用
- ElevenLabs Flash v2.5に対してネイティブスピーカー評価で68.4%の勝率を達成し、CC BY-NCライセンスで公開済み
研究の背景と課題
テキスト音声変換(TTS: Text-to-Speech)技術は、ナレーション生成や音声アシスタントなど幅広い用途で活用されています。近年は特定話者の声を短い音声サンプルから再現する「ゼロショット音声クローニング」への需要が高まっており、ElevenLabsやOpenAIといった企業が独自モデルを展開しています。
しかし、既存の商用モデルの多くはクローズドソースであり、研究や改良が難しい状況でした。自然性と話者類似度の両立、複数言語への対応、短い参照音声での高精度な声質再現といった課題も残っていました。
Mistral AIは2026年3月、これらの課題に取り組む多言語TTSモデル「Voxtral TTS」を発表しました。モデルウェイトをCC BY-NCライセンスで公開しており、研究・非商用目的での利用が可能です。
ハイブリッドアーキテクチャの設計
Voxtral TTSは3つのコンポーネントからなるハイブリッドアーキテクチャを採用しています。音声の「何を言っているか」を表す意味情報と、「どのような声で言っているか」を表す音響情報を分離して扱う点が特徴です。
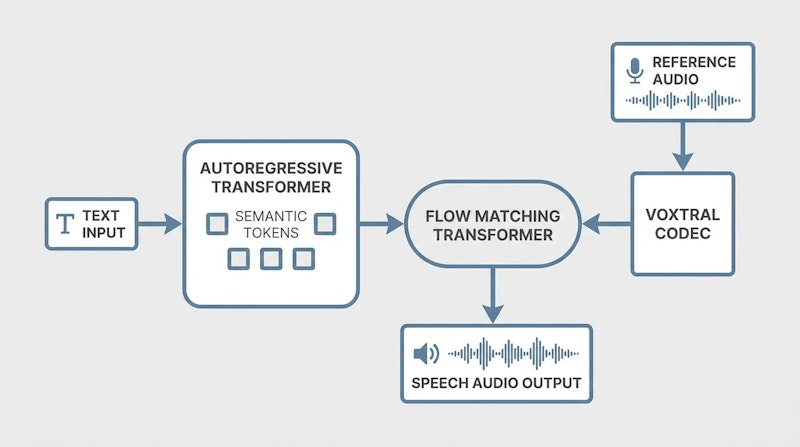
第1のコンポーネントは独自開発のVoxtral Codecです。入力された音声を37個の離散トークンに圧縮し、合計ビットレートは2.14 kbpsに抑えられています。意味トークン(語彙8192のVQ量子化)は話者に依存しない音声内容を表し、音響トークン(36個のFSQ量子化)は話者固有の声質を細かく記録します。意味トークンの学習にはWhisperからの知識蒸留を採用しています。
第2のコンポーネントは自己回帰デコーダーです。入力テキストと参照音声から得た音声トークンを条件として、意味トークンを1つずつ順次生成します。各ステップの隠れ状態はFlow-Matching Transformerへ渡されます。
第3のコンポーネントはFlow-Matching Transformerです。Flow Matching(ガウスノイズを目標分布へ変換する速度場を学習する手法)を用いて、3層の双方向Transformerが8回の数値積分で音響トークンを生成します。Classifier-Free Guidanceを適用することで、声質の再現精度を調整できます。
3秒音声クローニングの仕組み
Voxtral TTSが音声クローニングを実現する核心は、参照音声の扱い方にあります。3〜30秒の参照音声をVoxtral Codecに通すと、その話者固有の音響特性がトークン列として抽出されます。このトークン列が自己回帰デコーダーとFlow-Matching Transformerの両方に条件として与えられるため、生成音声全体を通じて参照話者の声質が維持されます。
参照音声が短い場合でも、意味トークンと音響トークンの分離設計により、音声内容(テキスト)と話者特性を独立して制御できます。このため、任意のテキストを参照話者の声で読み上げる「ゼロショットTTS」が実現します。
実験結果と性能評価
Voxtral TTSはアラビア語・ドイツ語・英語・スペイン語・フランス語・ヒンディー語・イタリア語・オランダ語・ポルトガル語の9言語に対応し、各言語のネイティブスピーカーによる評価が実施されました。
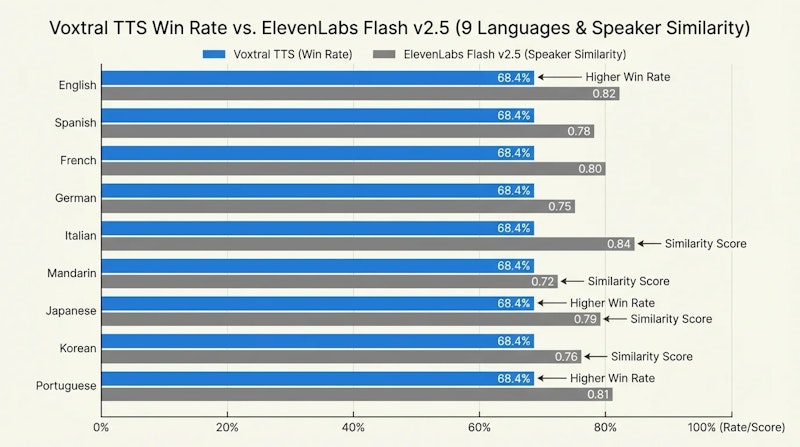
人間評価において、Voxtral TTSはElevenLabs Flash v2.5に対して68.4%の勝率を達成しました。自然性と表現力の観点でネイティブスピーカーが評価した結果です。単語誤り率(WER: Word Error Rate)は言語によって0.5〜5%の範囲に収まり、話者類似度スコアは0.72〜0.84を記録しています。
CC BY-NCで公開されたオープンモデルとして、商用モデルを上回るゼロショット音声クローニング性能を示した点は、研究コミュニティにとって大きな意義があります。一方、商用利用には別途ライセンス交渉が必要であり、学習データの詳細が十分に開示されていない点は課題として残ります。
まとめ
Voxtral TTSは、意味的音声トークンの自己回帰生成とFlow Matchingによる音響生成を組み合わせたハイブリッドアーキテクチャで、短い参照音声から高品質な多言語音声クローニングを実現しました。9言語対応と68.4%の対ElevenLabs勝率は、オープンなTTSモデルとして高水準の成果です。
今後は対応言語の拡充やリアルタイム推論への最適化が進むことで、音声インターフェースや多言語コンテンツ制作における活用範囲が広がると考えられます。







