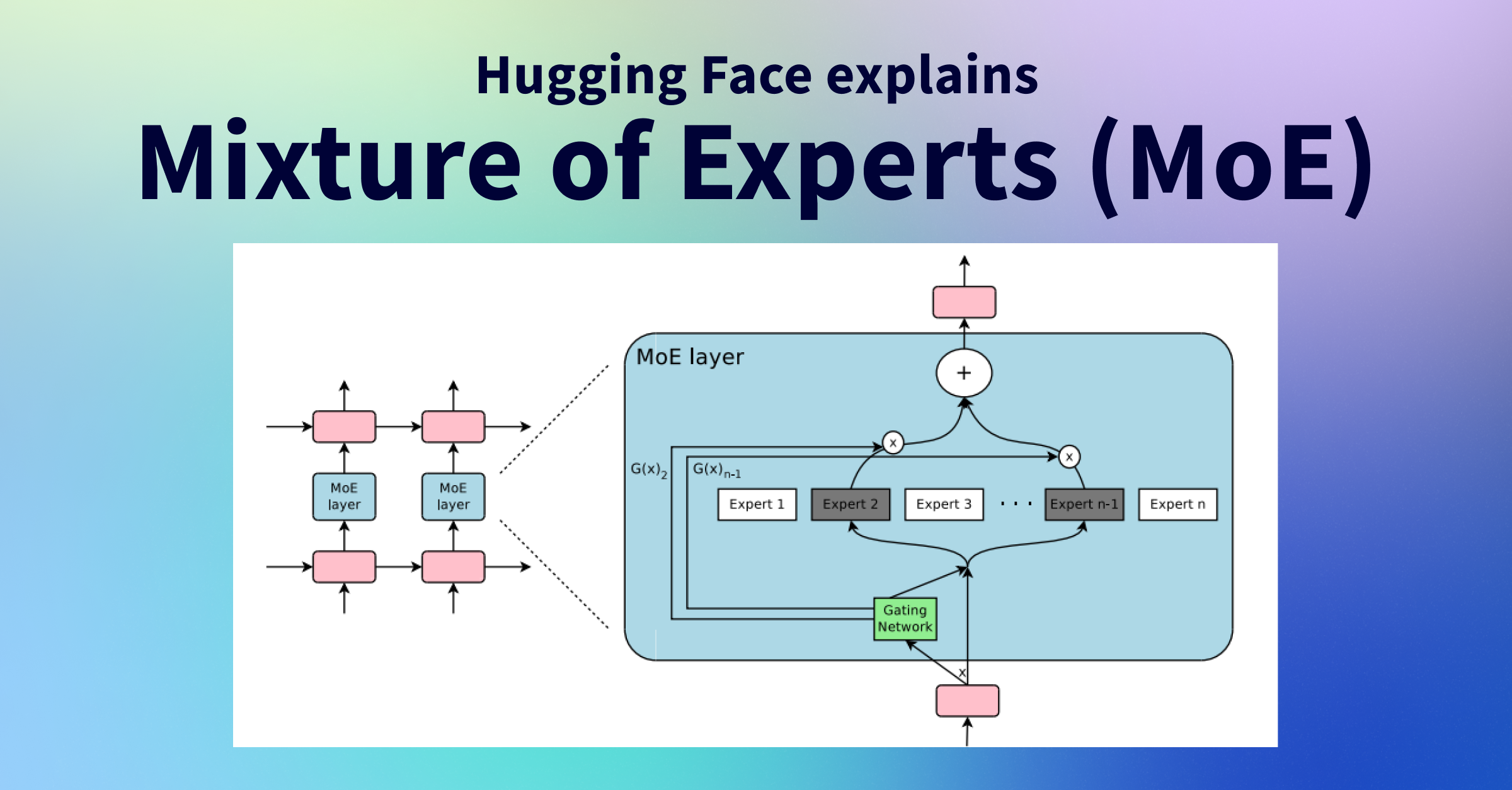
- MoEは複数のエキスパートFFNとルーターで構成され、各トークンを上位2〜3個のエキスパートにのみ送るスパース活性化で、大規模モデルの性能と計算効率を両立します
- Mixtral 8x7Bは47Bのパラメータを持ちながら1トークンあたりの計算量は約13B相当に抑えられており、Denseモデルより大幅に少ないFLOPSで推論できます
- GPT-4・DeepSeek V3・Gemma 4・Llama 4など2026年の主要フロンティアLLMがMoEを採用しており、「少ない計算で大きな知識容量」を実現するデファクトアーキテクチャになっています
MoEとは何か
MoE(Mixture of Experts: 専門家の混合)は、ニューラルネットワークにおけるアーキテクチャの設計手法です。通常の「Dense(密な)モデル」が入力トークンごとに全パラメータを使用するのに対し、MoEは複数の「エキスパート」ネットワーク群と、どのエキスパートを使うかを判断する「ルーター」で構成されます。
Transformerに適用する場合、各Transformer層のFFN(Feed-Forward Network: フィードフォワードネットワーク)をMoE層に置き換えます。このMoE層は「ゲートネットワーク(ルーター)」と「複数のエキスパートFFN」から成り立っており、ルーターは入力トークンを受け取り、スコアが上位K個(通常は2個)のエキスパートを選んでそこにトークンを送ります。選ばれなかったエキスパートは計算を行いません。これをスパース活性化と呼びます。

DenseモデルとMoEの違い
従来のDenseモデルは、各トークンの処理に全パラメータを使います。モデルが大きくなるほど表現力は上がりますが、計算コストとメモリ消費も比例して増大します。GPUの学習時間は指数的に伸び、Meta社のLlama 2(70B)のプレトレーニングには330万GPU時間(A100換算)が必要だったと報告されています。
一方MoEモデルでは、パラメータの総数(知識の器の大きさ)と、1トークンを処理するために実際に使う計算量を独立して制御できます。MistralのMixtral 8x7Bを例にとると、合計パラメータは47Bですが、1トークンを処理する際に動かすのは約13B相当にとどまります。Self-AttentionなどMoE以外の共有層を含めた全体でも、Denseの47Bモデルより大幅に少ない計算量です。

ルーターとエキスパートの仕組み
ゲーティングネットワークの動作
ルーター(ゲートネットワーク)は、各トークンをどのエキスパートに送るかを学習するネットワークです。最もシンプルな実装は、入力埋め込みと重み行列の積にSoftmax関数を適用し、各エキスパートへのスコアを算出するものです。スコア上位K個のエキスパートを選んでトークンを転送し、その出力を重み付き和として合算することで最終出力を得ます。ルーターは他のパラメータと同時に学習されます。
2017年にShazeer et al.が提案した「Noisy Top-k Gating」では、スコアに適度なノイズを加えてからTop-k選択を行います。これにより、特定のエキスパートだけが集中的に使われてしまう問題(後述の負荷の偏り)をある程度緩和できます。
エキスパートは何を専門とするのか
NVIDIAがMixtral 8x7Bを使って行った実験では、エキスパートがある程度のドメイン専門化を示すことが確認されています。たとえば抽象代数の問題では特定のエキスパートが多く使われ、法律問題では別のエキスパートが優勢になるという傾向がありました。一方でST-MoEの研究では、エンコーダーのエキスパートが句読点や固有名詞など表層的な分担を示すケースも観察されており、単純に「高度な概念を担当する」とは言えません。
MoEの歴史
MoEのアイデアは1991年のJacobs・Jordan・Nowlan・Hintonによる論文「Adaptive Mixture of Local Experts」に起源があります。入力空間の異なる領域を異なるエキスパートが担当するアンサンブル的な枠組みが提案され、エキスパートとゲートを同時に学習する仕組みが確立されました。
2013年にはEigen、Ranzato、Ilya(Sutskever)らがMoEをディープネットワークの一層として組み込む方向性を探索し、「大きくかつ効率的」なモデルの可能性を示しました。2017年にはShazeer et al.(共著者にGeoffrey HintonとJeff Deanを含む)が、スパース性を導入して137BパラメータのLSTMにMoEを適用し、大規模な言語処理への道を開きました。
Transformerへの本格統合は2020年代から始まります。2020年6月にGoogleがGShard(arXiv:2006.16668)を発表し、600Bを超えるTransformerをMoEでスケーリング。2021年1月にはSwitch Transformers(arXiv:2101.03961)が、ルーターをTop-1エキスパート選択に簡略化し、T5と同等規模のモデルと比較して大幅に高速な学習を達成しました。2021年12月にはGLaM(arXiv:2112.06905)がGPT-3相当の品質をエネルギー消費1/3で実現し、計算効率の観点でMoEの優位性を示しました。そして2023年末にMistralがMixtral 8x7Bを公開したことで、MoEはオープンソースコミュニティに一気に広まりました。
負荷分散という重要な課題
MoEの運用で最も重要な技術課題が負荷分散(Load Balancing)です。ルーターを適切に設計しないと、学習初期に人気の高いエキスパートが優先的に選ばれ、そのエキスパートがより多く学習されてさらに選ばれやすくなるという自己強化ループが生じます。結果として残りのエキスパートがほぼ使われない「エキスパートコラプス」が起き、MoEの利点が失われます。
この問題への代表的な対処として、Switch Transformersは補助損失(Auxiliary Loss)を導入しました。各エキスパートに均等にトークンが割り当てられるよう促すペナルティを学習損失に加算することで、偏りを防ぎます。またエキスパートキャパシティ(Expert Capacity)という概念も重要で、1エキスパートが処理できるトークン数の上限を設けることでオーバーフロートークンを次の層へ渡します。容量係数を高くすると品質が上がる一方でデバイス間通信コストが増えるため、設計上のトレードオフが生じます。

主要MoEモデルの比較
MoEアーキテクチャは現在、フロンティアLLMの標準的な選択肢となっています。LLM推論高速化技術(KVキャッシュ、vLLMなど)と組み合わせることで、巨大なMoEモデルを実際のプロダクション環境で運用することが現実的になっています。
モデル名 | 総パラメータ | 有効パラメータ(1トークンあたり) | エキスパート数 | 公開年 |
|---|---|---|---|---|
Mixtral 8x7B | 47B | ~13B | 8 | 2023 |
Mixtral 8x22B | 141B | ~39B | 8 | 2024 |
DeepSeek V3 | 671B | 37B | 256 | 2024 |
Llama 4 Scout | 109B | 17B | 16 | 2025 |
Llama 4 Maverick | 400B | 17B | 128 | 2025 |
Gemma 4(MoE) | 26B | 3.8B | 128 | 2025 |
MoEのメリットとデメリット
メリット
- 学習の高速化: 同じ計算コストでDenseモデルより多くのトークンを処理でき、プレトレーニング効率が大幅に向上します
- 推論FLOPSの削減: 全パラメータではなく一部のエキスパートのみを動かすため、同じパラメータ数のDenseモデルより少ない計算量で推論できます
- スケールしやすい知識容量: エキスパート数を増やすことで、計算量を抑えながらモデルの知識容量を拡大できます
デメリットと注意点
- VRAMは節約できない: 推論時に使うエキスパートは一部でも、全エキスパートのウェイトをメモリに保持する必要があります。Mixtral 8x7Bでは約47B分のVRAMが必要です
- ファインチューニングの難しさ: スパースモデルは過学習しやすく、小さいバッチサイズと高い学習率の組み合わせが有効ですが、Denseモデルのノウハウがそのまま適用できない場合があります
- 学習の複雑さ: 補助損失やエキスパートキャパシティなど追加のハイパーパラメータが増え、学習の安定化に工夫が必要です
DenseモデルとMoEの使い分け
MoEは多数のリクエストを高スループットで処理するAPIサーバーやバッチ推論のシナリオに向いています。一方、VRAMが限られたローカル環境や、精度重視のファインチューニングを行う用途では、同等の推論FLOPSを持つDenseモデルの方が扱いやすいことがあります。
2026年現在、GPT-4やGemini、DeepSeek V3など多くのフロンティアモデルがMoEを採用しており、「巨大なパラメータ数による高い知識容量」と「現実的な計算コスト」を同時に実現できるアーキテクチャとして、今後も中心的な役割を担い続けるでしょう。