
- OpenAIが2026年3月25日、AIの安全性に特化した「Safety Bug Bounty」プログラムをBugcrowdで公開開始した
- プロンプトインジェクションによるエージェント乗っ取りや独自情報漏洩など、生成AI固有の脆弱性が報告対象となる
- 単純なジェイルブレイクは対象外で、エージェント乗っ取りの報告には再現率50%以上の条件が設けられている
プログラム開始の背景
OpenAIは2026年3月25日、AIシステムの悪用リスクと安全性リスクを特定することを目的とした「Safety Bug Bounty」プログラムの公開を発表した。バグ報告プラットフォームのBugcrowdを通じて運営される。
AIの技術が急速に進化するなかで、悪用の手口も多様化している。OpenAIは従来のSecurity Bug Bountyとは別に、サイバーセキュリティの脆弱性には分類されないものの実害を伴うAI固有のリスクを受け付ける専門プログラムが必要と判断し、今回の立ち上げに至った。
対象となる3つのリスク領域
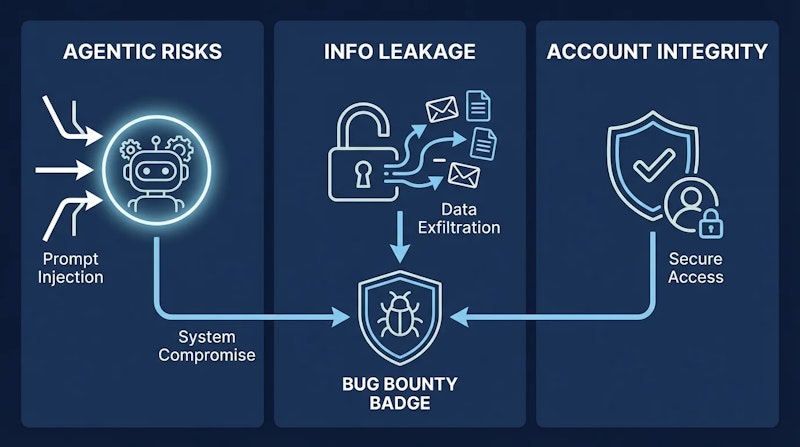
プログラムが対象とするのは、主に3つのカテゴリに整理されている。
1つ目は「エージェントリスク(MCP含む)」だ。攻撃者が埋め込んだテキストによってChatGPT AgentやBrowserなどのエージェント製品が乗っ取られ、有害な操作の実行やユーザーの機密情報を窃取するケースが該当する。報告が受理されるためには再現率が50%以上であることが条件となる。また、エージェントがOpenAIのウェブサイト上で大規模に禁止行為を実行する場合や、その他の有害な操作全般も含まれる。
2つ目は「OpenAIの独自情報」に関するリスクだ。モデルの推論処理に関わる独自情報が生成物に混入するケースや、その他の機密情報が漏洩する脆弱性が対象となる。
3つ目は「アカウントおよびプラットフォームの整合性」だ。自動化対策の回避、アカウント信頼シグナルの操作、アカウント制限や停止・BAN処分の回避といった問題が含まれる。
既存プログラムとの棲み分け
今回のSafety Bug Bountyは、既存のSecurity Bug Bountyとは役割を明確に分けている。権限外のデータへのアクセスや認証回避といった問題は従来のSecurity Bug Bountyが担当し、新プログラムはAI特有の悪用シナリオを受け付ける。送信された報告はOpenAIの安全・セキュリティの両チームがトリアージし、内容に応じて適切なプログラムへ振り分けられる仕組みだ。
単純なジェイルブレイクや汎用的なコンテンツポリシー回避はスコープ外となる。「モデルに失礼な言葉を言わせる」「検索エンジンで容易に見つかる情報を出力させる」といった報告は受理されないことが明示されている。OpenAIはBiorisk(生物リスク)コンテンツの問題など特定の害悪分野については、ChatGPT AgentやGPT-5向けに定期的に非公開バグバウンティを実施しており、研究者への参加を案内している。
AI安全研究コミュニティへの意義
従来のバグバウンティはシステム侵入や権限昇格といった古典的なセキュリティ問題を対象にしてきた。しかし生成AIが実世界のエージェントとして動作するようになった今、LLMのガードレールをファインチューニングで無効化する攻撃手法のような新種の脆弱性が次々と登場している。プロンプトインジェクションやエージェントの制御奪取は、従来の脆弱性定義には収まらないが実害は深刻だ。
OpenAIの取り組みは、そうした「AIネイティブな脆弱性」を正式な報告・報酬のフレームワークに組み込んだ点に意義がある。安全研究者が責任ある開示の手順を踏みながらAI固有のリスクを報告できる経路を整備することで、業界全体の安全基準の底上げにつながることが期待される。参加希望者はBugcrowdのSafety Bug Bountyページから申請できる。







