
- 事前学習済みモデルの重み近傍に、タスク固有の専門家解が高密度に存在する「Neural Thicket」現象をMIT研究が発見
- N個のランダムパラメータ摂動からトップKを選んで多数決するだけで、PPO・GRPO・ESと同等の性能を達成
- Qwen2.5-3BのGSM8K精度を79.8%から87.1%に向上。コード(RandOpt)はGitHubで公開済み
研究の背景
大規模言語モデル(LLM)のポスト学習(Post-training)では、PPO(Proximal Policy Optimization)やGRPO(Group Relative Policy Optimization)といった強化学習手法が広く使われています。これらは効果的である一方、実装の複雑さや計算コストの高さが実用上の課題となっています。
MIT(マサチューセッツ工科大学)のPhillip Isola研究室が2026年3月に発表した論文「Neural Thickets」は、こうした複雑な最適化を一切使わずとも、事前学習済みモデルの重みの近傍に、タスク固有の専門家解が高密度に存在するという新たな発見を報告しています。この発見は、LLMポスト学習の前提を根本から問い直すものです。
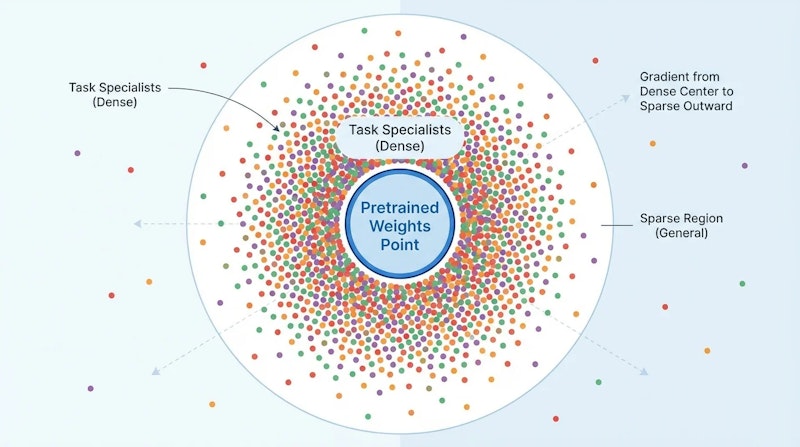
Neural Thicket現象とは
著者らはまず、「解の密度(Solution Density)」という指標を定義しました。これは、事前学習済み重みにランダムな摂動(わずかなノイズ)を加えたとき、その摂動がベースモデルの性能を向上させる確率を表します。具体的には、標準偏差σ=0.005のガウスノイズを重みに加えてサンプリングし、各摂動の性能改善を測定しました。
実験では0.5Bから32Bパラメータまでの様々な規模のモデルを対象に測定を行った結果、モデルの規模が大きくなるにつれて解の密度が単調に増加することが確認されました。例えばGSM8K(数学推論ベンチマーク)において、小規模モデルでは密度が0%だったのに対し、32Bモデルでは64%に達しています。
さらに「Spectral Discordance(スペクトル不一致度)」という指標で各摂動の専門性を測定すると、大規模モデルほどタスク固有のスペシャリストが多く存在することも確認されました。著者らはこの現象を「Neural Thicket(神経の茂み)」と呼んでいます。事前学習済みモデルを単一の開始点ではなく、専門家を内在させた分布として捉える新しい視点です。
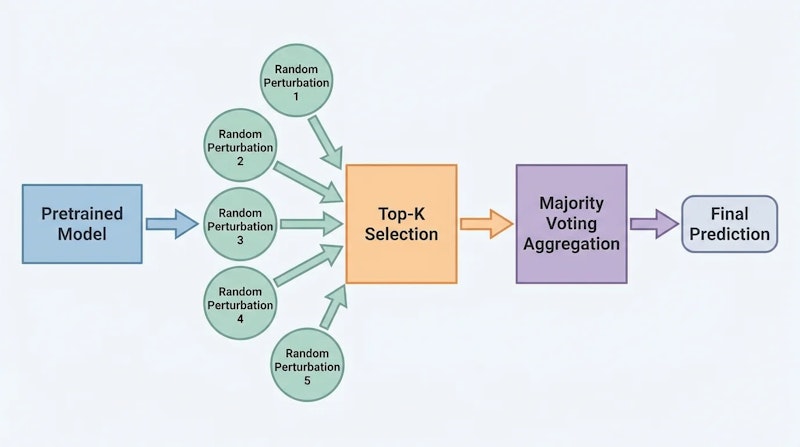
RandOptの仕組み
この発見に基づき、著者らは「RandOpt」と呼ばれるシンプルなアルゴリズムを提案しています。処理は2段階で構成されます。まず「選択フェーズ」では、事前学習済み重みθにN個のランダムなガウス摂動を加えてN個の候補モデルを生成し、それぞれを訓練データで評価して上位K個を選択します。次に「推論フェーズ」では、選ばれたK個のモデルが予測を生成し、多数決によって最終的な回答を決定します。
この手法は完全に並列化可能であり、勾配計算を一切必要としません。LoRAをはじめとする既存のパラメータ効率的なファインチューニング手法とは異なり、モデルの重みを直接更新しない点が大きな特徴です。各摂動の評価は独立して行えるため、並列実行による高速化も容易に実現できます。
実験結果
論文ではQwen2.5-3Bモデルを用いたGSM8Kベンチマークで、RandOpt(K=50)がベースモデルの79.8%から87.1%へと性能を向上させることを示しています。この結果はPPO、GRPO、進化戦略(ES)といった標準的なポスト学習手法と競争力のある性能であり、勾配不要なアプローチの有効性を実証しています。
一方で、この手法の有効性はモデル規模に依存します。おおむね1.5Bパラメータ以下のモデルでは効果が限定的であり、十分な事前学習が前提条件となります。また、多数決による集約は離散的な生成タスクに適しており、K回の推論パスが必要になるため推論コストが増加するという制約もあります。著者らはモデルの蒸留によってこのオーバーヘッドを軽減できることも示しています。
まとめと今後の展望
Neural Thicketsの研究は、「十分に事前学習されたモデルは、すでに多様なタスク専門家を重みの近傍に内在させている」という視点を示しています。強化学習ポスト学習の代替として、よりシンプルで解釈可能なアプローチへの道を開く研究です。
課題として、推論時のK回の前向き計算コスト、大規模モデルへの依存性、連続値出力タスクへの拡張などが残ります。コード(RandOpt)はGitHubで公開されており、研究コミュニティでの検証や応用が期待される発見です。







