
- スパース注意機構とdocument-wise RoPEにより、16Kから1億トークンへの拡張でも性能劣化9%未満を達成
- 長文脈4ベンチマーク平均で同一バックボーンのRAGを16%上回り、MS MARCOではRAGの3.011点に対してMSAは4.141点(0〜5スケール)を記録
- 2枚のA800 GPUで1億トークン規模の推論を実現し、大規模コーパス要約やエージェント長期記憶への応用が広がる
研究の背景
大規模言語モデル(LLM)が実用化されるにつれて、長い文脈を扱う能力は欠かせない要件となっています。医療記録の一括分析、大規模ソフトウェアリポジトリの理解、エージェントによる長期タスクの遂行など、現実のユースケースでは数十万から数百万トークンに及ぶ情報を処理する必要があります。
しかし、Transformerの自己注意機構(Self-Attention)はシーケンス長の2乗に比例する計算量を持つため、長文脈処理には莫大なメモリと計算リソースが必要です。これまでの研究でも128Kから1Mトークン程度まで拡張する試みはありましたが、1億トークンを超えるスケールをend-to-endで訓練可能な形で実現したモデルは存在しませんでした。
長文脈処理の代替手法として広く使われているRetrieval-Augmented Generation(RAG、検索拡張生成)は、事前に関連文書を検索してから回答を生成するアプローチです。ただし、RAGは検索精度に依存するため、文書をまたぐ多段階推論や複雑な関係の把握には限界があります。本論文が提案するMSAは、この課題をモデルが直接長文脈を保持・参照することで解決しようとしています。
MSAの提案手法
Memory Sparse Attention(MSA)は、大規模なメモリコーパスを線形複雑度で処理できるend-to-endのフレームワークです。主要な構成要素は、スケーラブルなスパース注意機構、document-wise RoPE、KVキャッシュ圧縮、Memory Parallelの4つです。
スパース注意機構は、全トークン間の注意計算を避け、重要なチャンクのみを選択して計算します。長いコーパスを固定長のチャンクに分割し、各チャンクを代表するルーティングキーを用いて上位k件を取得する仕組みです。これにより計算量がシーケンス長に対して線形(O(L))に抑えられます。
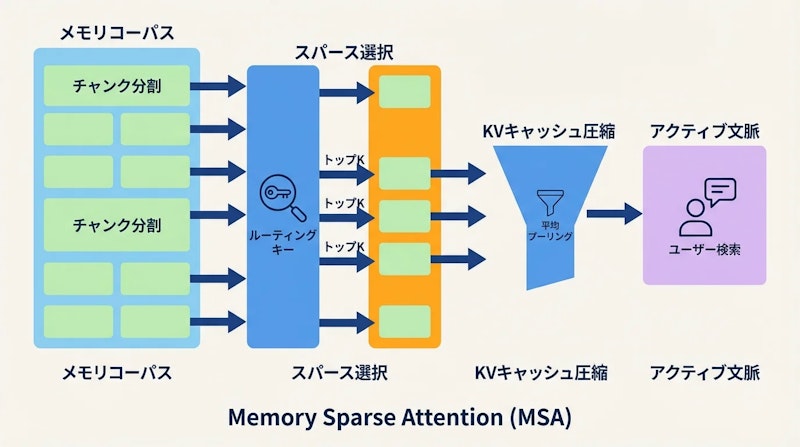
位置エンコーディングにはdocument-wise RoPEという独自の戦略を採用しています。通常のRoPE(位置情報を回転行列で表現する手法)は全トークンに連続した位置IDを割り当てますが、訓練時と推論時で文脈長が大きく異なると外挿精度が低下します。MSAでは各文書に独立した位置ID(0から開始する「並列RoPE」)と、アクティブな文脈に適用する「グローバルRoPE」を組み合わせることで、64Kトークンで訓練しながら1億トークンへの外挿を可能にしています。
1億トークン規模の推論を現実のハードウェアで実現するために、Memory Parallelというメモリ管理手法も導入しています。ルーティングキーのみを複数のGPUのVRAMに分散配置し、コンテンツとなるKVキャッシュはCPUのメインメモリにオフロードすることで、2枚のA800 GPU(合計160GB容量)での動作を可能にしました。さらに、固定長チャンクの平均プーリングによるKVキャッシュ圧縮が、メモリ使用量を大幅に削減しています。
多段階推論が必要なタスクへの対応として、Memory Interleavingという反復検索生成の仕組みも備えています。モデルが生成した文書IDをもとに元テキストを取得し、次のイテレーションのクエリに追加することで、複数ホップの推論を段階的に実行します。
実験結果
評価にはNeedle-In-A-Haystack(NIAH)ベンチマーク(長文の中から特定情報を見つけ出すテスト)と、4つの長文脈QAデータセット(Natural Questions・DuReader・TriviaQA・MS MARCO)が用いられました。
NIAHベンチマークでは、32Kから100万トークンの範囲でわずか3.93ポイントの低下にとどまり、94.84%の精度を維持しました。ベースモデルのQwen3-4Bは256Kトークン時点で48.16%まで急落しており、MSAの長文脈維持能力の高さが際立ちます。文脈長を16Kから1億トークンまで拡張した場合の性能劣化は9%未満で、スケールに対する安定性が確認されています。
QAタスクでは、同一バックボーン(Qwen3-4B)を用いたRAGとの比較において、Natural Questions・DuReader・TriviaQA・MS MARCOの4ベンチマーク平均でRAGを16%上回りました。データセット別に見ると、MS MARCOではRAGの3.011点に対してMSAは4.141点、DuReaderではRAGの3.579点に対して4.155点を記録しています。Natural QuestionsではRAGの3.374点に対して3.545点、TriviaQAではRAGの4.414点に対して4.621点となっており、幅広いQAタスクで一貫した改善を示しています。
より強力なRAGシステムであるKaLMv2とQwen3-235B(2,350億パラメータ)を組み合わせた最先端構成との比較でも、MSAは評価した9データセットのうち4つで最高性能を達成し、平均スコアで7.2%の相対的改善を示しました。Qwen3-4BというはるかにモデルサイズのMSAが、235Bパラメータ規模の最先端RAGを超えた結果は実用上の意義が大きいといえます。
多段階推論が求められるHotpotQAベンチマークでは、Memory Interleavingにより単一ステップ検索と比べて19.2%の性能向上が確認されています。ablation study(構成要素の寄与を検証する実験)では、継続事前学習を除去すると31.3%の性能低下、元文書テキストの統合を除去すると37.1%の低下が生じており、各構成要素の重要性が示されています。
まとめと今後の展望
MSAは、スパース注意機構とdocument-wise RoPEの組み合わせにより、1億トークンという前例のないスケールのメモリ処理を線形複雑度で実現しました。大規模コーパスの一括要約、デジタルツイン(現実世界のデジタル複製)、エージェントの長期記憶など、従来のLLMでは難しかった応用領域への展開が期待されます。
一方で、論文内でも指摘されているように、複数文書間に強く結合した依存関係が存在するタスクでは課題が残ります。証拠が分散し密接に相互関連しているシナリオでは、構造的整合性の維持が難しいとされています。また、オフラインの前処理(コーパスのチャンク化とルーティングキーの事前計算)が必要な点は、リアルタイムの動的な文書追加には向かないケースがあります。
GitHubでのスター数が2,200件を超える高い注目度が示すように、長文脈処理はLLM研究の重要な方向性の一つとして位置づけられています。MSAが示した「訓練文脈長の1,500倍以上への外挿」という知見は、次世代の長文脈モデル設計に大きな示唆を与えるものです。






