
- 単視点3D生成で問題だった「見えない裏面の確率的生成」を、VLM(Qwen2.5-VL)の中間層hidden statesを注入することで意味的に制御可能な処理へ転換する手法を提案
- MMDiT第20・30・40層のhidden statesを拡散ステップt=0.25で抽出し、クロスアテンションを介してTRELLIS.2ベースの3D生成モデルへ橋渡しする2段階フレームワークを構築
- HY3D-BenchテストセットでULIP 0.2174・Uni3D 0.3518を達成し、Hunyuan3D-2.1やTRELLIS.2などのSOTA手法を両指標で上回る評価結果を報告
研究の背景と課題
3Dコンテンツ生成は、ゲームや映像制作、デジタルツイン構築など幅広い分野で需要が高まっています。特に1枚の画像から3Dアセットを生成する「単視点3D生成」は、手軽に3Dコンテンツを作れる技術として注目を集めてきました。
しかし、この技術には根本的な制約があります。カメラから見えない裏面や側面の形状は入力画像から推測できないため、既存モデルは見えない領域を確率的に生成するしかありません。テキスト指示で「持ち手を太くして」と指定しても、その意図が3D生成モデルに正確に伝わる仕組みが存在しなかったのです。
Know3Dは、この「見えない裏面の確率的生成」という課題に対し、大規模視覚言語モデル(VLM)が持つ豊かな意味理解を3D生成プロセスへ橋渡しすることで解決策を提示します。
Know3Dの2段階フレームワーク
フレームワークは2段階で構成されます。第1段階では、Qwen2.5-VLをベースとした画像編集モデルを微調整し、入力画像とテキストプロンプトから裏面(バックビュー)画像を生成します。第2段階では、この生成プロセスで得られた中間表現をTRELLIS.2ベースの3D生成モデルへ注入し、最終的な3Dアセットを出力します。
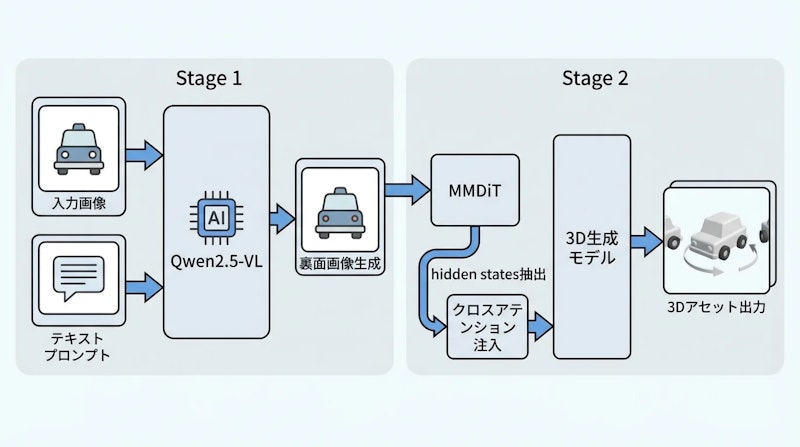
この設計で重要なのは、裏面画像そのものではなく生成中の中間表現を活用するという発想です。完成した裏面画像を3Dモデルに渡すのではなく、VLMの拡散変換器内部で形成される構造的・意味的情報を直接引き出すことで、より豊かな誘導が実現します。
MMDiT中間層特徴を使う理由
Know3Dの核心的な貢献は、どの特徴表現を3D生成への橋渡しに使うかという選択にあります。研究チームはMMDiT(Multimodal Diffusion Transformer)の中間層hidden states、DINOv3の視覚特徴、VAEエンコーダ出力の3種類を比較し、MMDiT hidden statesが最も優れた手がかりになることを発見しました。
VAEエンコーダはピクセルレベルの再構成に特化した設計のため、高レベルな意味・構造情報が失われてしまいます。DINOv3は視覚的特徴として優秀ですが、テキスト指示との連携が弱い点が課題です。一方でMMDiT hidden statesは空間的・構造的情報と意味的情報の両方を豊富に含んでおり、アブレーション実験でもその優位性が明確になりました。
特徴表現 | IoU(高いほど良) | CD(低いほど良) |
|---|---|---|
MMDiT hidden states(本手法) | 0.352 | 2.262 |
DINOv3 | 0.342 | 2.385 |
VAEエンコーダ | 0.308 | 2.803 |
具体的には、MMDiTの第20・30・40番目ブロックからhidden statesを抽出し、チャネル方向に結合してから線形投影と層正規化を経て、3D生成モデルのクロスアテンション層のキーと値として供給します。
特徴抽出タイミングの工夫
特徴を取り出すタイミングにも重要な工夫があります。拡散過程のステップt=0.25の時点でhidden statesを抽出するのが最良という結果が得られました。このステップではMMDiTがすでに生成画像の大まかな形状と意味的構成を確定しており、細部のノイズ除去は未完了という状態です。言い換えると、高レベルな構造情報が最も凝縮されたタイミングで特徴を引き出せるため、3D生成への誘導効果が高まります。
t=0(拡散の最終状態)と比較するとt=0.25の優位性が数値にも現れています。t=0ではIoU 0.343・CD 2.376にとどまるのに対し、t=0.25ではIoU 0.352・CD 2.262と明確な差が確認されました。
HY3D-Benchでの性能比較
Know3DはHY3D-Benchという3D生成の包括的なベンチマークで評価されました。テキストと3D形状の意味的整合性を測るULIPスコアと、詳細な3D理解を測るUni3Dスコアの2指標で既存手法と比較しています。
手法 | ULIP (Test) | Uni3D (Test) | ULIP (Val) | Uni3D (Val) |
|---|---|---|---|---|
Know3D(本手法) | 0.2174 | 0.3518 | 0.2127 | 0.3512 |
Hunyuan3D-2.1 | 0.2140 | 0.3434 | — | — |
動画生成モデルの3D知識をMLLMへ活用するVEGA-3Dなど、マルチモーダル情報を3D生成へ応用する研究が活発化している中、Know3DはテストセットでULIP 0.2174・Uni3D 0.3518を達成し、Hunyuan3D-2.1をいずれの指標でも上回りました。
まとめと今後の展望
Know3Dは、単視点3D生成における「見えない裏面の確率的生成」という根本課題に対し、VLMのMMDiT中間層hidden statesを活用することで意味的に制御可能な解を提示しました。テキスト指示だけで3Dアセットの裏面構造を誘導できるという実用性は、3Dコンテンツ制作の効率化に直結します。
現段階での制約として、生成される裏面画像の品質が低い場合でも一定の結果は得られるものの、複雑なテキスト指示では制御精度が落ちる可能性があります。また2段階構成による計算コストも改善の余地があります。VLMの内部表現を「橋渡し」として活用するというKnow3Dのアプローチは、今後の3D生成研究において参照される基盤的な方向性となるでしょう。






