
- Mixture-of-Transformers(MoT)により視覚・言語トークンに独立パラメータを割り当てるロボット専用VLMを提案
- 22ベンチマーク中16項目で最優秀を達成。32Bモデルはスコア67.0%でGemini 3.0 Pro(63.6%)を3.4ポイント上回る
- 実ロボット操作のマグ吊り下げで75%の成功率を記録し、先行モデルπ0(45%)を30ポイント上回ることを実証
研究の背景
ロボットが現実世界で自律的に動作するためには、カメラ映像から状況を理解し、適切な動作を選択する能力が必要です。汎用の視覚言語モデル(VLM: Visual Language Model)はこの用途の有力候補ですが、静止画の認識や文章の読み取りを得意とする汎用モデルと、3次元空間の把握や物体操作の判断を求められるロボット制御では、要求される能力に大きな隔たりがありました。
Tencentのロボティクス部門であるTencent Robotics XとHY Vision Teamは、この課題に正面から向き合い、ロボット(具体化エージェント)専用の基盤モデル「HY-Embodied-0.5」を2026年4月に発表しました。2Bパラメータのエッジデプロイ向けモデルと、32Bパラメータの高性能モデルの2バリアントを提供し、コードとモデル重みをGitHubで公開しています。
MoTアーキテクチャの仕組み
HY-Embodied-0.5の核心はMixture-of-Transformers(MoT)と呼ばれるアーキテクチャです。従来のVLMでは視覚トークンと言語トークンが同一の変換器ブロックを共有していましたが、MoTは視覚モダリティ専用の独立したQKV(クエリ・キー・バリュー)行列とFFN(フィードフォワードネットワーク)層を設けることで、モダリティごとに最適化された処理を実現します。
具体的には、視覚トークンには双方向注意(画像全体を相互参照できる仕組み)を適用し、言語トークンには従来どおりの単方向の因果注意を維持します。これにより、画像の空間的な関係性を捉える能力と、文章の文脈依存的な生成能力を両立させています。さらに、ロボットの知覚表現を高めるために潜在トークン(latent tokens)を組み込んでいます。これは画像から抽出した視覚情報を圧縮・抽象化した中間表現で、3次元空間の把握や物体の姿勢推定に有効に機能します。
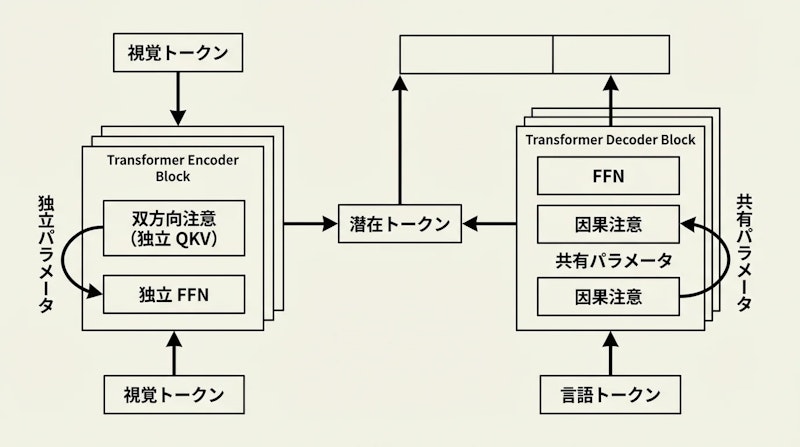
事前学習と後処理の設計
HY-Embodied-0.5の訓練は600Bトークン以上の大規模コーパスで実施されました。内訳は一般理解データ389Bトークンと、ロボット・空間認識・物体操作に特化した具体化データ236Bトークンです。一般的な視覚言語能力と、ロボット特有の知覚能力をバランスよく獲得させる設計になっています。
事前学習後の精度向上には「反復的自己進化型の後処理パラダイム」を採用しています。モデルが自ら生成した回答を評価・選択することで段階的に推論品質を高める手法です。また、32Bモデルの知識を2Bモデルへ転送する方策内蒸留(policy distillation)を活用することで、エッジデプロイ向けの小型モデルでも高い精度を実現しています。
ベンチマーク評価
HY-Embodied-0.5は22種のベンチマークで評価されました。2Bモデル(MoT-2B)は同規模の先行モデルを上回り、22項目中16項目で最優秀を記録しています。総合スコアは58.0%で、同クラスのQwen3-VL-4Bを10.2ポイント上回る成績です。
32Bパラメータのモデル(内部呼称:MoE-A32B)は総合スコア67.0%に達しました。このモデル名には「MoE(Mixture-of-Experts)」という表記が含まれますが、アーキテクチャの核心はMoTであり、MoE的な混合構造をMoTの実装内部で活用していることに由来します。Googleが誇るGemini 3.0 Proの63.6%を3.4ポイント上回ったことは、ロボット知能に特化した専用モデルが汎用最先端モデルを凌駕できることを示しています。マルチモーダル基盤モデルの大規模化と専門化という観点では、Intern-S1-Proの解説も参考になります。
実ロボット操作の検証
ベンチマーク上の数値だけでなく、HY-Embodied-0.5はVLMを応用した視覚言語アクション(VLA: Vision-Language-Action)モデルに変換され、実際のロボットアームを使った物理タスクで検証されました。評価タスクと成功率は以下のとおりです。
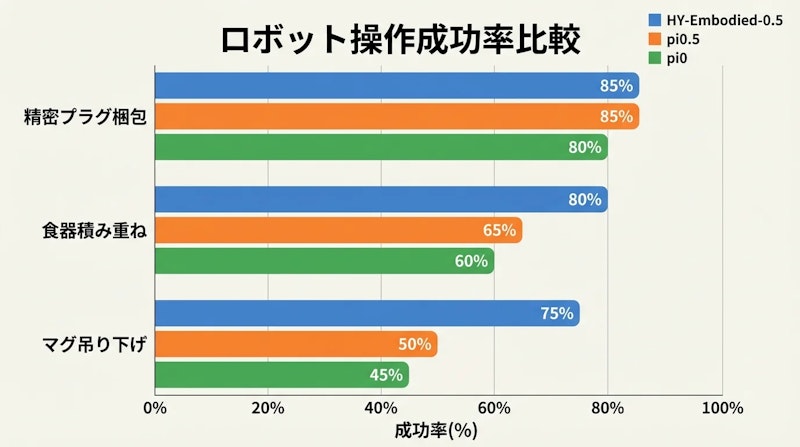
- 精密プラグ梱包: 85%の成功率(π0.5と同等)
- 食器積み重ね: 80%の成功率(π0の60%を上回る)
- マグ吊り下げ: 75%の成功率(π0の45%を30ポイント上回る)
特にマグ吊り下げは、細い取っ手を正確に把持・移動させる高難度タスクです。HY-Embodied-0.5が75%の成功率を記録し、先行モデルπ0(45%)を30ポイント上回ったことは、MoTに由来する高精度な空間認識能力が実操作の精度に直接反映されたことを示しています。
まとめと今後の展望
HY-Embodied-0.5は、汎用VLMをロボット向けに転用するのではなく、最初から具体化エージェントに必要な能力を設計に組み込んだ点が従来研究と大きく異なります。MoTアーキテクチャによる視覚・言語の独立パラメータ化、600B以上の大規模事前学習、反復的後処理の組み合わせが、ベンチマークと実機の両面で高い成果につながりました。
コードとモデル重みが公開されている点も、産業・研究両分野への普及を後押しします。家庭用ロボットから製造ラインの自動化まで、具体化AI(embodied AI)の実用化が加速するなかで、HY-Embodied-0.5は有力な基盤の一つとなるでしょう。一方で、学習データの多様性や未知環境への汎化性能については、引き続き検証が必要です。






