
- DiTの全層で使われる残差接続に「前向き量の膨張・後向き勾配の減衰・ブロック間冗長性」という3つの根本的な欠陥を実証的に特定した
- タイムステップに応じて過去の層出力を選択的に重み付けする「DAR(Diffusion-Adaptive Routing)」を提案し、FIDスコアを9.67から7.56に改善
- 同品質への到達に要する学習ステップを8.75分の1に短縮。REPA併用で学習初期には2倍の加速も確認
研究の背景
画像生成モデルの主流となっている拡散モデルには、近年「Diffusion Transformer(DiT)」と呼ばれるアーキテクチャが広く採用されています。Stable Diffusion 3やFLUXなど、現在の代表的なテキスト・画像生成モデルもこの設計を基盤としています。
DiTでは、Transformerの各ブロックを積み重ねて画像のノイズ除去を行います。ブロック間の情報伝達には「残差接続(residual connection)」という仕組みが使われており、各ブロックの出力に前のブロックの出力をそのまま足し合わせる方式が一般的です。この設計はTransformerの黎明期から受け継がれてきたものですが、本研究はその基本設計に潜む3つの問題を初めて体系的に明らかにしました。
残差接続の3つの問題
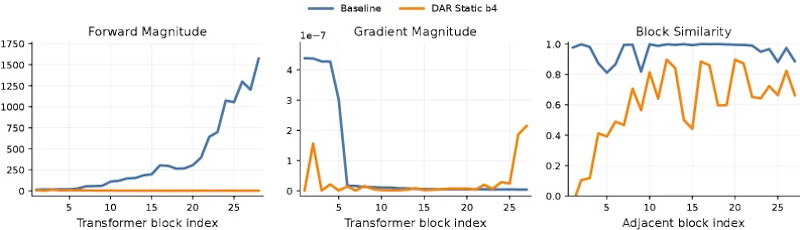
著者らは、標準的な残差接続がDiT内でどのように機能しているかを分析しました。深さ方向に沿って計測した結果、次の3つの問題が確認されました。
- 前向き量の単調膨張: 層を重ねるたびに特徴量の大きさが増大し続け、後段の層が支配されやすくなる
- 後向き勾配の急減衰: 逆伝播の際、前段の層に届く勾配が極端に小さくなり、浅い層が学習に貢献しにくくなる
- ブロック間の冗長性: 隣接するブロックの出力が互いに酷似しており、多くのブロックが実質的に同じ処理を繰り返している
これらは独立した問題ではなく、「残差を均等な重みで足し続ける」という設計の必然的な帰結です。どの層の出力を、どれだけの割合で組み合わせるかを動的に制御する仕組みが欠けていることが根本原因として示されました。
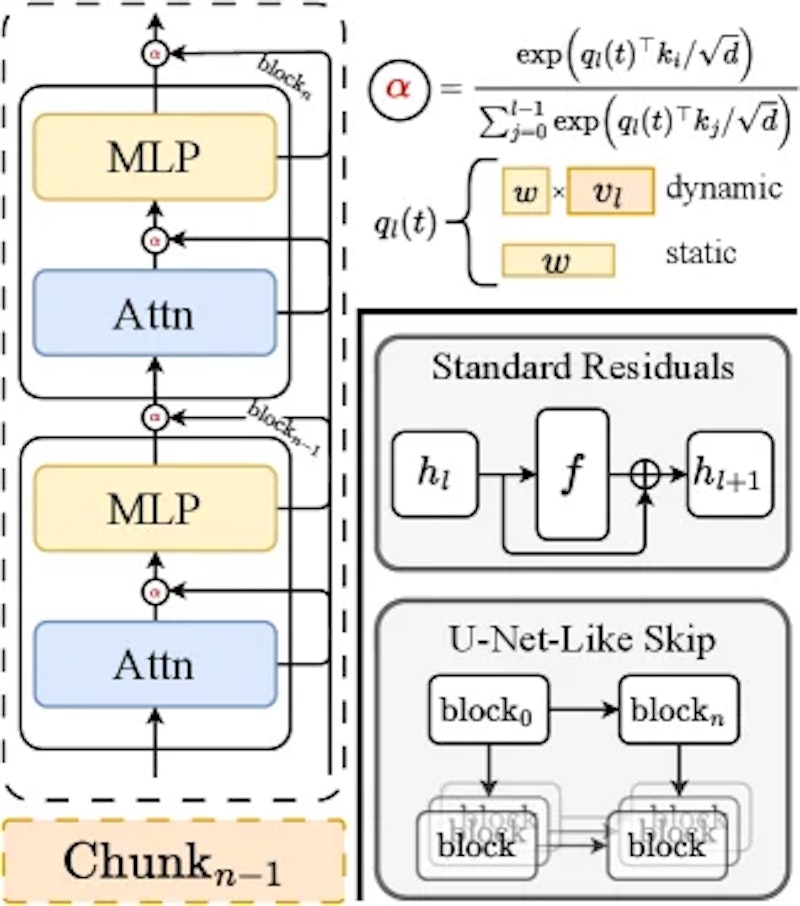
DARの仕組み
提案手法のDAR(Diffusion-Adaptive Routing)は、従来の「単純な足し算」による残差接続を、学習可能な重み付きの選択的集約に置き換えます。各層が過去のすべての層の出力の中から「どの情報をどれだけ使うか」をソフトマックス関数で決定し、その重みはタイムステップ(ノイズ除去の進行度)に応じて変化します。ノイズが多い初期段階と仕上げの段階で異なる情報経路を使うことで、各フェーズに最適な情報伝達が実現されます。
DARには2つの変種があります。Static DARは各層が固定のベクトルから重みを生成します。実装がシンプルで計算コストも低く、すでにFIDスコアの大幅改善が見込めます。一方のDynamic DARは前の層の出力そのものから重みを動的に計算するため、よりきめ細かい適応が可能で性能はStaticを上回ります。
またメモリ効率のため、全層を小さな「チャンク」に分割して情報を集約する設計も取り入れています。これにより、メモリ使用量をモデルの深さに比例した量から一定の範囲に抑えられます。最適なチャンクサイズは理論的にも導出されており、SiT-XL/2ではS=4が最適であることが確認されています。
実験結果
ImageNet 256×256を対象に、SiT-XL/2モデルで評価が行われました。標準的な残差接続を使ったベースラインが175万学習ステップでFIDスコア9.67を達成するのに対し、DARは同等の品質に達するために必要なステップ数を8.75分の1に短縮しました。さらに同じ175万ステップで比較した場合、FIDスコアは9.67から7.56へと改善されています。
DARを既存の学習改善手法「REPA」と組み合わせた実験では、学習の初期段階において2倍の加速が確認されました。DARとREPAは設計思想が異なる独立した改善であり、組み合わせることで相乗効果が得られています。DiTのアーキテクチャ改善に取り組む関連研究として、SEGAによる学習不要の高解像度化手法も参照してみてください。
計算コストの面では、Triton言語で最適化された実装によってレイテンシと活性化メモリを大幅に削減できることも確認されています。DARを組み込んでも学習・推論全体への影響は限定的であり、実用的な範囲に収まります。
まとめと今後の展望
DARは、Diffusion Transformerの核心的な設計である残差接続を、学習可能なタイムステップ適応型のルーティングに置き換えることで、学習速度と生成品質を同時に改善します。特定のアーキテクチャに依存しない汎用的な手法であり、論文ではFLUX・Stable Diffusion 3などのMM-DiTベースモデルや動画生成DiTへの適用可能性が今後の課題として挙げられています。
長年見直されてこなかった残差接続という設計要素を根本から改善するこの方向性は、今後の拡散モデル研究に新たな可能性を開きます。学習コストの削減は実用面での恩恵が大きく、大規模なDiTモデルの事前学習において特に価値を発揮するでしょう。







