
- MoEアーキテクチャで1兆パラメータを達成したオープンソース初の科学マルチモーダル基盤モデル
- 化学・材料科学・生命科学など100以上の専門タスクでプロプライエタリモデルを上回る性能を記録
- XTunerとLMDeployでFP8混合精度強化学習を実現し、訓練効率の低下を約20%以内に抑制
研究の背景と課題
科学研究の現場では、化学反応の予測から材料特性の解析、タンパク質構造の解読まで、多様な専門知識と複雑なマルチモーダルデータを扱う必要があります。これまでの大規模言語モデルは一般タスクでの優れた成績を示してきましたが、高度な科学専門知識が求められる領域では、ドメイン特化型モデルに及ばないケースが少なくありませんでした。
一方で、モデル規模を大きくすれば科学タスクへの対応力が高まるという仮説はあるものの、1兆パラメータ規模のオープンソース科学モデルはこれまで存在しませんでした。この空白を埋めるべく、InternLMチームがIntern-S1-Proを発表しました。
MoEアーキテクチャの設計
Intern-S1-Proは前世代モデルIntern-S1をベースにエキスパート数を拡張することで、合計1兆パラメータを達成しています。採用するMixture-of-Experts(MoE)アーキテクチャは、全パラメータを常に使うのではなく、入力に応じて必要な専門家モジュールを選択的に活性化する仕組みです。
ルーティング機構には独自の「グループドルーター」を採用しています。エキスパートをデバイスマッピングに基づいてグループ分けし、8方向のエキスパート並列処理(EP8)でデバイス間の完全な負荷分散を実現します。この設計により、前世代から4倍のパラメータ規模へ拡張しながら、訓練効率の低下を約20%以内に抑えることに成功しました。
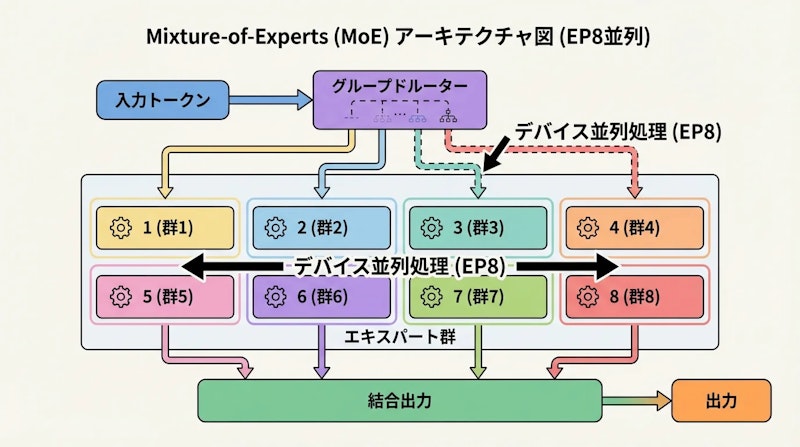
位置エンコーディングには、トークンの離散的な粒子性と連続的な波動特性を同時に捉えるFourier位置エンコーディング(FoPE)を導入しました。また、天文学・地球科学・神経科学にわたる時系列データを処理するため、10の0乗から10の6乗ステップまでのシーケンスに対応するアダプティブサブサンプリングモジュールも搭載しています。ルーターの最適化にはStraight-Through Estimator(STE)を採用し、全ルーター埋め込みに意味のある勾配が伝わる構造としました。
6兆トークンの科学訓練データ
訓練データは合計6兆トークンに及び、このうち約2700億トークンがPDF処理から生成された科学的な画像テキストキャプションです。キャプション生成にはMinerU2.5やInternVL3.5、CapRL-32Bを組み合わせた独自パイプラインを使用しており、ビジョンエンコーダは約3億枚の画像テキストペアを使ったコントラスト学習で訓練されています。
科学データと一般データを混在させる際には、3つの手法で情報衝突を解消しています。「構造化科学データ変換」「科学データ多様化」「システムプロンプト分離」がその柱です。訓練データの質と多様性がマルチモーダルモデルの性能向上に直結することは、この分野の共通認識です。
強化学習による後処理訓練
1兆パラメータ規模での強化学習(RL)には、安定した混合精度訓練が欠かせません。Intern-S1-Proでは、エキスパート層にFP8量子化、非エキスパート部分にBF16、LMヘッドにFP32を使い分けた三層構造を採用しています。この設計でメモリ使用量を大幅に抑えられます。
訓練と推論でのルーティング差異を補正するために「デュアル重要度サンプリング」とマスキング関数を組み合わせた手法も導入しました。ロールアウト時のルーター再生メカニズムが精度の一致を保証します。これらの工夫により、XTunerとLMDeployのインフラ上で、オープンソースモデルとして初めて1兆パラメータ規模の高効率RL訓練を実現しました。
ベンチマーク性能
Intern-S1-Proは一般タスクと科学タスクの両面で高い性能を示します。数学的推論の難関ベンチマークであるAIME-2025では93.1点を記録し、知識評価のMMLU-Proでも86.6点を達成しています。視覚接地タスクのRefCOCO-avg(91.9点)やUIスクリーン理解のScreenSpot V2(93.6点)も高水準です。
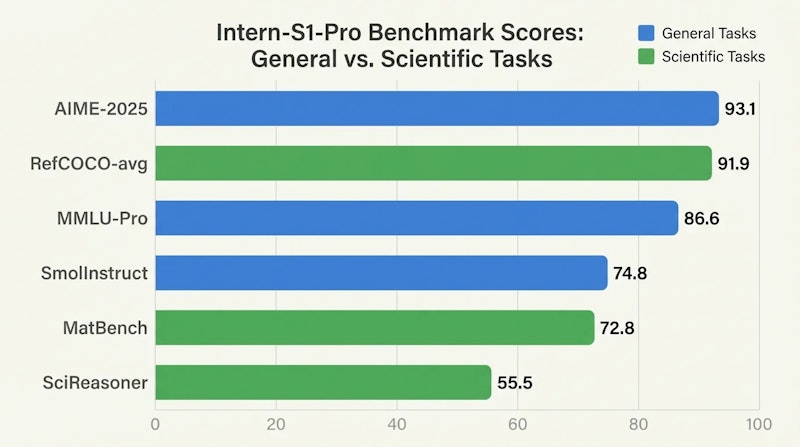
科学分野では、化学合成タスクのSmolInstruct(74.8点)、材料科学のMatBench(72.8点)、科学推論のSciReasoner(55.5点)など、複数の専門ベンチマークでプロプライエタリモデルを上回る結果を残しています。この研究が示す重要な知見は「十分に大規模な汎用モデルを科学データで共同訓練すると、特化型モデルより高い性能が得られる」という点です。ドメイン特化型アーキテクチャが優位との従来の通念を覆す発見です。
マルチモーダル推論の観点では、マルチホップデータ合成でVLMの汎化推論能力を高める研究とも同様の方向性を持ち、大規模モデルと多様なデータの組み合わせが科学AIの性能を引き上げる潮流を裏付けています。
まとめと今後の展望
Intern-S1-ProはMoEアーキテクチャによる1兆パラメータ規模の達成、6兆トークンの科学訓練データ、混合精度強化学習の三つを組み合わせることで、科学AIの新たなスケールを切り拓きました。コードはGitHubで公開されており、研究コミュニティが自由に活用できます。
今後の課題としては、さらなる科学分野のカバレッジ拡大と、より長い文脈長への対応が考えられます。1兆パラメータ規模のオープンソース化は、製薬・素材・宇宙科学など応用領域のAI研究を加速させる可能性を持ちます。特化型モデル不要という知見は、今後の科学AI開発の設計思想にも影響を与えるでしょう。






