- Wikimedia Foundationが3月20日にコンテンツガイドラインを更新し、LLMによる記事生成・書き換えを原則禁止。ChatGPT・Gemini・DeepSeekなどが対象となります
- 例外は「人間レビューを経た校正支援」と「LLM支援翻訳ガイドライン準拠の翻訳」の2ケースに限定。LLMが主体的にコンテンツを決定する行為と、人間がAIを補助的に活用する行為は明確に区別されています
- LLM生成の判定基準は明示されておらず、文体だけでなく編集履歴やポリシー準拠状況を総合的に判断する運用となっています
方針の概要と禁止対象
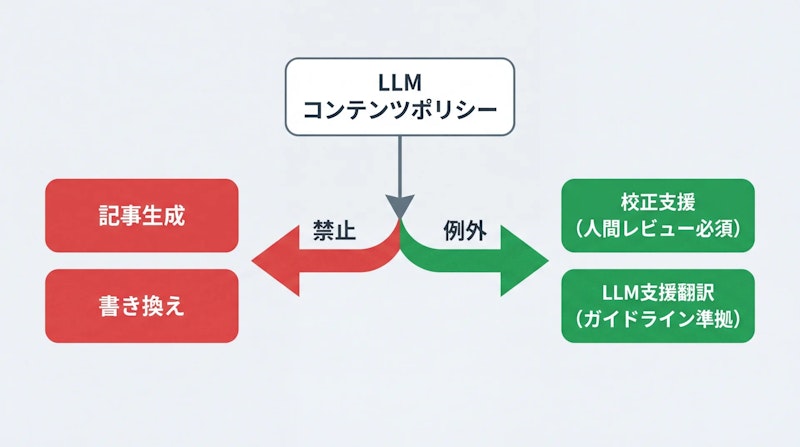
Wikipediaを運営する非営利団体Wikimedia Foundationは、2026年3月20日(UTC)にコンテンツガイドラインを更新しました。ChatGPT、Gemini、DeepSeekなどの大規模言語モデル(Large Language Model、LLM)によって生成されたテキストは「Wikipediaのコアコンテンツポリシーのいくつかに違反することがよくある」とし、記事コンテンツの生成または書き換えへのLLM利用を2つの例外を除いて禁止すると明記しました。
Wikipediaは「検証可能性」「独自研究の禁止」「中立的な観点」の3つをコアポリシーとして掲げています。LLM生成テキストがこれらに抵触しやすいことが方針変更の根拠となっています。英語版だけで670万本以上の記事を擁する世界最大の百科事典が、AI生成コンテンツに明確な禁止規定を設けたことは、コンテンツガバナンス全体に波及する意義を持ちます。
2つの例外規定の詳細
禁止の対象外となるケースは2つに限られます。第1は、編集者がLLMを使って自身の文章に基本的な校正を提案させ、人間のレビューを経た上で一部を組み込む場合です。第2は、他言語版WikipediaのコンテンツをLLMで英語版に翻訳する場合で、「Wikipedia:LLM支援翻訳」に定めるガイドラインへの準拠が条件となります。
禁止されるのは、LLMが実質的にコンテンツを生成・決定するケースです。人間の編集者が主体となり、AIを参照・補助的に活用することとは根本的に区別されています。たとえばLLMが生成した翻訳文をそのまま投稿することは禁止されますが、翻訳の出発点として利用しながら人間が実質的な編集・検証を行う場合は、ガイドラインの範囲内として扱われます。
判定基準の曖昧さと課題
方針では、LLM生成テキストの具体的な判定基準を明示していません。ガイドラインは「編集者の中には、LLMと似たような文体を持つ人もいるかもしれない」と認めており、文体や言語上の特徴だけで制裁を正当化することを戒めています。実際の判断では、テキストがコアコンテンツポリシーに準拠しているかどうか、および当該編集者の最近の編集履歴を総合的に考慮することが推奨されています。
この曖昧さはWikipediaコミュニティへの負荷を高める懸念があります。LLMに近い文体を持つ執筆者が誤検知されるリスクを避けながら、実際のLLM生成コンテンツを排除するという難題を、ボランティアの編集者が担うことになるためです。
禁止の背景にある不公正な循環
今回の方針変更は、AIとWikipediaをめぐる緊張関係が高まる中で打ち出されました。2024年11月にプリンストン大学の研究チームが発表した調査では、同年8月に作成された英語版Wikipediaの新規記事のうち、約5%がAI生成である可能性が示されています。高品質な人間の知識を学習データとして吸収したLLMが、精度の低いコンテンツを百科事典に還流させる構図は、知識の信頼性を侵食するリスクをはらんでいます。
LLMが抱えるハルシネーション(Hallucination、事実に反する情報を確信を持って生成する現象)も、禁止の根拠として挙げられます。AIが誤情報を自信を持って提示する傾向は人間によるレビューでも見逃されやすいことがスタンフォード大学とCMUの共同研究でも示されており、「検証可能性」を核心に置くWikipediaの編集原則とは根本的に相容れません。
Wikimedia Foundationはこれに先立ち、2025年11月にAI企業に対してAPIを通じたWikipediaデータの使用料支払いを要求しました。2026年1月にはAmazon・Meta・Microsoftなど5社が有償パートナーとなっています。今回のコンテンツ方針はこうした一連の動きと連動しており、LLMとオープンな知識コモンズのあり方をめぐる議論は続く見通しです。
コンテンツ産業・開発者への影響
AIを活用した記事生成や翻訳を手がける事業者にとって、今回の方針は直接的な制約となります。Wikipediaへの直接投稿を業務に含めている場合はプロセスの見直しが求められます。一方、社内ナレッジベースや企業ブログなどWikipedia以外の媒体には効力が及ばないため、自社の利用用途を精査した上で対応を判断することが重要です。
開発者にとっては、Wikidataや他のWikimediaプロジェクトが今後のデータ調達に与える影響も注視が必要です。Wikimedia Foundationが学習用データセットの提供条件を厳格化する可能性もあり、AI企業のデータ戦略に影響を与えうる局面が続きます。