
- Reference Attention機構により参照画像をトークン化してデコーダの各段階に注入。ファインチューニング不要でWan 2.1とVideoVAE+の両方に対応できる
- Inter4K・WebVidベンチマークでPSNRが最大+2.1dB向上し、VBench動画生成評価でも12次元中11次元で改善を達成
- 画像→動画生成・スタイル転送・動画編集に適用可能で、プラグイン設計により既存の動画生成パイプラインへの組み込みが容易
研究の背景と課題
近年の動画生成モデルは潜在拡散モデル(Latent Diffusion Model)を基盤としており、ノイズを除去するデノイザーにはテキストプロンプトや参照画像などの豊富な条件情報が与えられます。しかし、デノイザーが出力した潜在表現を実際の映像フレームへと変換する「デコーダ」は、こうした条件付けを一切受けていません。
この研究チームはこの非対称性を「アーキテクチャ的非対称性(architectural asymmetry)」と呼び、デコーダにも同等の条件付けが必要だと指摘しています。条件付けのないデコーダはテキストや顔・細かな模様といった高周波成分を失いやすく、フレーム間で視覚的な一貫性が崩れる問題が生じます。RefDecoderはこの課題を正面から解決しようとした研究です。
RefDecoderの設計と仕組み
RefDecoderは、動画VAEのデコーダに参照フレームのシグナルを直接注入する手法です。既存のデコーダ重みをそのまま維持しながら、新たに追加した軽量コンポーネントで参照情報を各アップサンプリング段階に流し込む構造となっています。
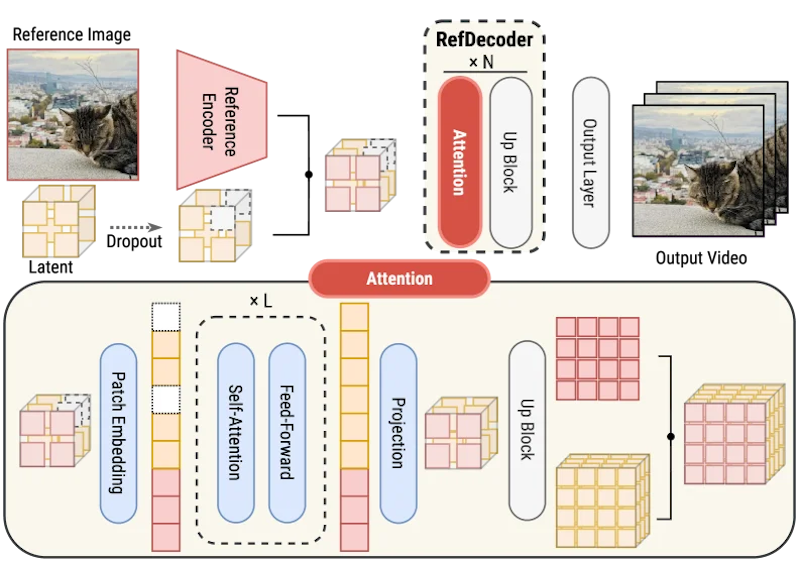
手法の核心は3つのコンポーネントで成り立っています。まず、軽量な畳み込みエンコーダが参照画像を高次元トークンに変換します。次に、デコーダの各アップサンプリング段階で参照トークンと映像の潜在トークンを時間軸方向に結合し、共有Transformerブロックで処理した後に分離して個別にアップサンプリングする仕組みです。このような設計により、既存のデコーダ重みとの互換性を維持しながら、参照情報を各段階で活用する構造となっています。
学習では、映像の潜在トークンを最大70%の確率でゼロに置き換える「ドロップアウト」を活用します。これによりデコーダが参照シグナルへの依存を強め、より高品質な再構成が可能になる仕組みです。また2段階のカリキュラム学習を採用しており、まず基礎的な再構成能力を習得させた後、高解像度・高動態シーンへと段階的に難易度を上げていきます。
実験結果と性能比較
評価にはInter4KとWebVidという2つのベンチマークを使用しています。Inter4KはUltra HD映像を含む高解像度データセット、WebVidは多様なシーンを含む大規模動画データセットです。評価指標はPSNR(ピーク信号対雑音比:値が高いほど画質が優れることを示す指標)、SSIM(構造的類似度:画像の構造的な類似性を測る指標で値が高いほど良い)、LPIPS(知覚的画質距離:人間の知覚に近い画質評価で値が低いほど良い)の3種類です。

Wan 2.1をバックボーンとしてInter4Kデータセットで評価した場合、PSNRが33.7から34.9へと+1.2dBの向上を達成しました。VideoVAE+バックボーンではWebVidデータセットで最大+2.1dBのPSNR向上が得られ、LPIPSも全ての設定でほぼ改善しています。
動画生成品質の総合ベンチマークであるVBench(被写体一貫性・背景一貫性など12の視点から動画生成品質を評価する指標)では、全12次元中11次元で改善が確認されました。総合スコアは87.9から88.2へ上昇しており、特に被写体の一貫性と背景の一貫性において顕著な改善が見られます。
アブレーション実験では、Transformerブロック数を3個から10個に増やすとInter4KのPSNRが34.3から34.9dBへ段階的に向上することも示されており、計算資源に応じてトレードオフを調整できる柔軟な設計です。
多様なタスクへの応用
RefDecoderはファインチューニング不要でプラグイン的に利用できるため、動画生成以外のタスクにも容易に適用できます。動画生成パイプラインの改善研究としては、拡散プロセス自体を効率化するAnyFlowのような手法も存在しており、RefDecoderはデコーダ側からアプローチする補完的な解決策として位置付けられます。


スタイル転送では、参照画像のスタイルを保ちながら入力映像の構造を維持した変換が可能です。動画編集タスクでは、LoRA-Editなどの手法で問題となる「非編集領域の劣化」を参照フレームから忠実に復元することで抑制できることも確認されています。画像から動画を生成するI2Vタスクにおいても参照フレームとの構造的整合性が高まり、より自然なモーションが得られます。
まとめと今後の展望
RefDecoderは、潜在拡散モデルにおける「デコーダへの条件付けの欠如」という見落とされがちな問題を指摘し、Reference Attention機構による参照フレーム注入という実用的な解決策を提示した研究です。ファインチューニング不要という設計上の工夫により、Wan 2.1やVideoVAE+をはじめとする既存の動画生成パイプラインへの導入が現実的な選択肢となっています。
現状では単一の参照フレームのみに対応しており、複数参照への拡張や参照エンコーダのさらなる強化、より長尺映像への対応などが今後の課題として挙げられています。ベースモデルが持つバイアスをそのまま引き継ぐ点は注意が必要ですが、デコーダという切り口から動画生成品質を向上させる手法として、幅広い応用が期待されます。







