
- RAGは外部データベースを動的に参照して最新情報を活用し、ファインチューニングはモデルの重みを更新してドメイン知識を内在化するという根本的な設計思想の違いがある
- コスト面ではRAGが約10分の1の費用で済むケースが多いが、ドメイン固有の文体・専門語彙の精度や推論速度ではファインチューニングが優位になる場面もある
- RAFTやAgentic RAGなど両者を組み合わせるハイブリッドアプローチが実務で主流化しつつあり、RAGで素早く検証しPEFTで精度を補う段階的戦略が現実的な選択肢となっている
なぜこの選択が重要か
LLMを業務システムに組み込む際、開発者が最初に直面する問いが「RAGとファインチューニング、どちらを選ぶべきか」です。両者はいずれもLLMの精度を高めるための手法ですが、アーキテクチャ、コスト、実装難易度、そして適切なユースケースがまったく異なります。
「とりあえずRAGで始める」「ファインチューニングすれば何でも解決する」——こうした思い込みが、実装後の失敗につながるケースは少なくありません。本記事では、コスト・精度・実装難易度の3軸に加え、PEFT(Parameter-Efficient Fine-Tuning)やAgentic RAGなど最新手法も交えながら、実務エンジニアが最適な手法を選ぶための判断基準を解説します。
RAGとは何か
RAG(Retrieval-Augmented Generation: 検索拡張生成)は、2020年にMeta AIが発表した論文「Retrieval-Augmented Generation for Knowledge-Intensive Tasks」で提唱されたアーキテクチャです。LLMの外部に知識ベースを置き、ユーザーのクエリに応じてリアルタイムで情報を取得・活用します。
RAGの4ステップ処理フロー
RAGは以下の4段階で動作します。
- クエリ受付: ユーザーの質問をシステムが受け取る
- 情報検索: ベクトルDBを使ってセマンティック検索を実行し、関連文書を取得
- コンテキスト統合: 取得した情報をクエリと結合してLLMへのプロンプトを構成
- 回答生成: LLMが自身の学習知識と取得情報を組み合わせて回答を生成
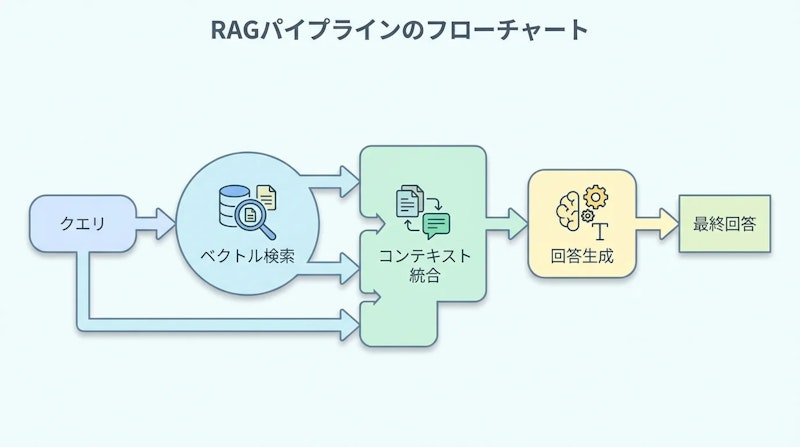
ベクトルDBはテキストを数値ベクトル(埋め込み)に変換して保存し、意味的な類似度で検索を行います。これにより、キーワードの完全一致ではなく「意図」で関連文書を見つけられます。「社内規程が改定された」「新製品の仕様が変わった」といった場合でも、知識ベースを更新するだけでLLMが最新情報を回答に反映できる点が最大の強みです。
一方でデメリットもあります。検索品質がシステム全体の精度を左右するため、データのチャンキング(分割方法)やインデックス構造の設計が重要です。また、検索から生成までの処理が増えることでレイテンシが高まる傾向があり、ミリ秒単位の応答が求められるシステムには不向きな場合があります。
ファインチューニングとは何か
ファインチューニング(Fine-Tuning)は、事前学習済みのLLMに追加のドメイン固有データを使って再学習を行い、モデルの重み(パラメータ)そのものを更新する手法です。RAGが「外部から情報を持ち込む」のに対し、ファインチューニングは「知識をモデル内部に焼き込む」アプローチです。
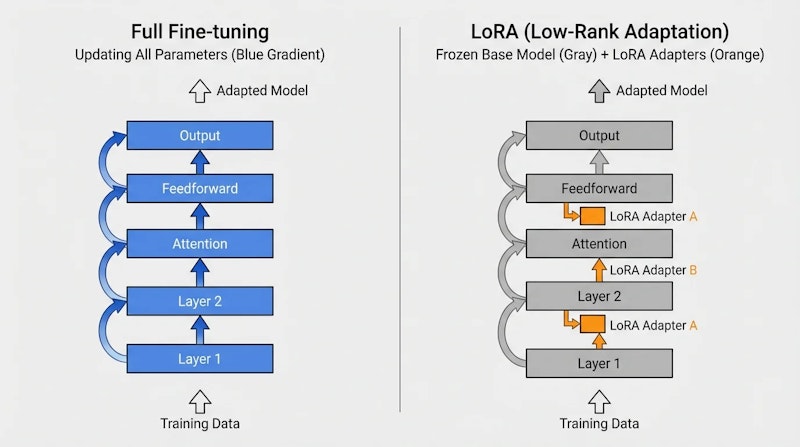
フルファインチューニングとPEFT
従来のフルファインチューニングはすべてのパラメータを更新するため、大規模なGPU計算資源とメモリが必要です。GPT-4クラスのモデルをフルファインチューニングするには数千万円規模のコストがかかることもあります。
この課題を解決したのがPEFT(Parameter-Efficient Fine-Tuning)です。代表的な手法として以下があります。
- LoRA(Low-Rank Adaptation): 元のモデル重みを凍結し、低ランク行列のみを追加学習。学習パラメータ数を大幅削減できる
- QLoRA: LoRAを量子化技術と組み合わせ、さらにメモリ効率を向上。コンシューマGPUでも大規模モデルの学習が可能
- Adapter: Transformerの各層に小さなニューラルネットワーク(アダプター)を挿入して学習
QLoRAを使えば、7Bクラスのオープンソースモデル(LLaMAやMistralなど)をA100 GPU 1枚で数時間から数日以内に学習できます。クラウドGPUを使っても数万円程度で完了するケースがあり、ファインチューニングのコストハードルは急速に下がっています。
DPOとRLHFによる高精度化
ファインチューニングの上位手法として、人間のフィードバックを活用する技術も実用化されています。RLHF(Reinforcement Learning from Human Feedback: 人間フィードバックによる強化学習)は、人間が好む回答を強化学習で最適化します。より実装が簡便なDPO(Direct Preference Optimization: 直接選好最適化)は、RLHFと同等の効果を強化学習なしで実現する手法で、主要な商用LLMの品質向上にも活用されています。
RAG vs ファインチューニング:徹底比較
比較軸 | RAG | ファインチューニング |
|---|---|---|
初期コスト | 低〜中(数万〜数十万円) | 高(数十万〜数千万円) |
運用コスト | ベクトルDB + 検索API費用 | 推論コストのみ(再学習なしなら安価) |
情報の鮮度 | ◎ リアルタイム更新可能 | △ 再学習が必要 |
ドメイン特化精度 | △ 文体・形式の習得は困難 | ◎ 専門語彙・文体を深く習得 |
推論レイテンシ | △ 検索処理分だけ増加 | ◎ 追加処理なし |
実装難易度 | 中(インフラ設計が重要) | 高(GPU・データ準備が必須) |
ハルシネーション対策 | ◎ ソース引用で根拠を示せる | △ 学習データの質に依存 |
プライバシー対応 | ◎ データをモデル外で管理 | △ 学習データとして取り込む |
必要データ量 | 少量でも機能する | 数百〜数千件以上のラベル付きデータが必要 |
最新ハイブリッド手法
RAFT:両者の融合アプローチ
2024年に発表されたRAFT(Retrieval-Augmented Fine-Tuning)は、RAGとファインチューニングを統合する手法です。ファインチューニング時に意図的に「関係ないドキュメント(ノイズ)」を混在させ、モデルが正しい文書を見分ける能力を同時に学習させます。推論時のRAGシステムが、より精度の高い回答を生成できるようになります。
Agentic RAG:自律的な情報探索
Agentic RAG(エージェント型RAG)は、単純な1回検索ではなく、エージェントが複数回検索・推論を繰り返しながら最終回答を組み立てるアーキテクチャです。複雑な質問や多段階の推論が必要なタスクで効果を発揮します。プロンプトエンジニアリングのChain-of-Thought推論やReActフレームワークとの組み合わせで、エージェントの推論品質をさらに高めることができます。
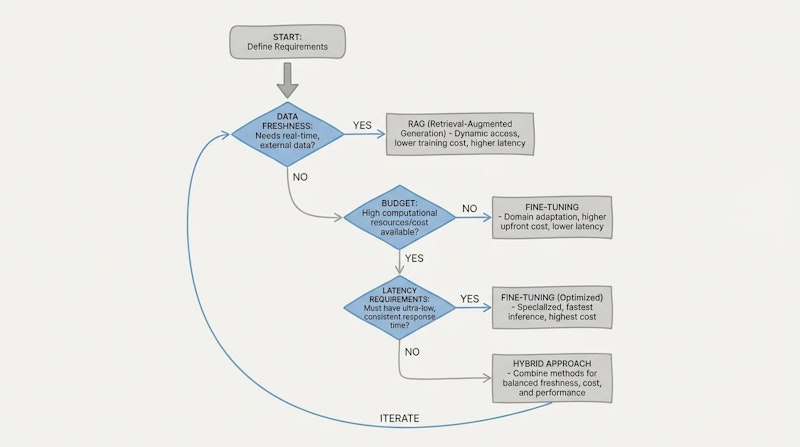
どちらを選ぶか:判断基準
実務では「どちらか一方を選ぶ」ではなく、「どの段階から始めて、どこまで進化させるか」という視点が重要です。
RAGが適しているケース
- 社内FAQ・社内規程・製品マニュアルなど頻繁に更新される情報を扱う
- 回答の根拠(ソース)を明示する必要がある(法務・医療・金融領域など)
- プロトタイプを素早く構築してビジネス価値を検証したい
- データプライバシーの観点で情報をモデルに学習させたくない
ファインチューニングが適しているケース
- 特定の文体・形式・専門語彙を高精度で再現する必要がある(法律文書・医療記録など)
- 低レイテンシが求められ、検索処理を挟む余裕がない
- 感情分析・コード生成・文書分類など特定タスクに特化したモデルを作りたい
- 十分なラベル付き学習データと計算資源がある
ハイブリッドアプローチが最善のケース
多くの本番システムでは、両者を組み合わせることが最も高い性能をもたらします。たとえば、LoRAでドメイン語彙・文体を習得させつつ、最新の製品情報はRAGで動的に取得するという構成です。まずRAGで素早く価値を検証し、精度改善が必要な部分にのみPEFTを適用するという段階的アプローチが、コストと精度のバランスを最適化します。
実装コストの現実的な目安
実際のプロジェクトでの費用感を整理します。RAGシステムの初期構築は数万円から数十万円(ベクトルDB構築・埋め込みAPI費用)が目安で、フルファインチューニングは数百万円から数千万円規模になることもあります。
一方でQLoRAなどのPEFT手法を使えば、A100 GPU 1〜2枚で数日以内に学習が完了するケースも増えています。オープンソースLLMの活用で、クラウドGPUを使った場合でも数万円程度でドメイン特化モデルを構築できるようになりました。ただしコストはLLMのサイズや学習データ量に大きく依存するため、小規模な概念検証(PoC)から始めて規模を拡大していくアプローチが現実的です。
まとめ
RAGとファインチューニングは優劣の二択ではなく、目的・データ・予算・スピード要件に応じて使い分けるものです。多くの場合、RAGから始めて価値を検証し、精度やパフォーマンスの課題が明確になった段階でPEFTを適用するという段階的な戦略が、最もリスクが低くコスト効率も高い選択です。さらに高度な要件には、RAFTやAgentic RAGといったハイブリッドアーキテクチャへと進化させることで、実用システムとしての完成度を高められます。





