
- MoEのルーター設計に初めて数学的根拠を与え、各ルーターベクトルをエキスパート行列の主特異方向に整合させる「Manifold Power Iteration(MPI)」を提案した論文
- Power IterationとRouter Retractionを組み合わせた「Power-then-Retract」は既存オプティマイザと互換性があり、スループット低下は0.2%にとどまる軽量な実装
- 1B〜11B規模の事前学習で損失を一貫して改善。3BモデルではARC-Cが+3.05pt、平均精度が+2.33ptと下流タスク性能も向上
MoEルーターの設計課題
Mixture-of-Experts(MoE)は、入力ごとに複数の「エキスパート」と呼ばれるサブネットワークのうち一部だけを選んで処理を行う仕組みです。モデル全体のパラメータ数を増やしながら1回あたりの計算コストを抑えられるため、DeepSeekやMixtralなど主要な大規模言語モデル(LLM)で広く採用されています。
MoEの中核をなす「ルーター」は、入力トークンをどのエキスパートに割り当てるかを決定する小さな行列です。ところが、このルーター設計の原則はこれまで経験則に頼っている部分が多く、「ルーターベクトルがどの方向を向くべきか」という理論的根拠は示されていませんでした。本論文はこの問いに正面から取り組み、数学的に裏付けられた設計原則を初めて提示しています。
主特異方向への整合
論文が導き出した設計原則はシンプルです。「各ルーターベクトルは、担当するエキスパート行列の主特異方向(principal singular direction)に整合していなければならない」というものです。
特異方向とは、行列が最も強く反応する入力の向きを指します。エキスパートの重み行列を特異値分解(SVD)すると、情報量の大きな「軸」が得られます。ルーターベクトルをこの軸に沿わせることで、そのエキスパートが最も得意とする特徴を持つトークンが適切に割り当てられ、各エキスパートの専門性が有効活用されます。
この整合度はRayleigh商(行列と入力の組み合わせで定まるスカラー値)という指標で定量化できます。論文ではMPI適用後に投影度λが0.37から0.67前後まで上昇することが実験で確認されており、ルーターとエキスパートの方向が実際に揃うことが示されています。
MPIの仕組み
原則を実装する手法が「Manifold Power Iteration(MPI)」です。処理は2ステップで構成された「Power-then-Retract」というパラダイムを採用しています。
最初の「Power Iteration(累乗反復)」では、ルーター行Rとエキスパート重み行列Wgを用いて次の演算を行います。
- 更新式: R̂[i] = R[i] · Wgi · (Wgi)⊤
- エキスパート行列とその転置行列の積を掛けることで、ルーター行を主特異方向へ近づける
続く「Router Retraction(ルーター収縮)」では、更新後のルーター行をL2正規化してノルムを一定値Cに制約します。
- 正規化式: R'[i] = C · R̂[i] / ‖R̂[i]‖₂
- この制約を省くと、AdamWとMuonを使う設定で学習崩壊が発生することが実験で確認されている
MPIは既存のオプティマイザに上乗せする形で導入でき、スループット低下は0.2%以内です。MoEアーキテクチャを採用したマルチモーダルモデルなど、MoEを用いる多様なアーキテクチャに応用できる可能性があります。
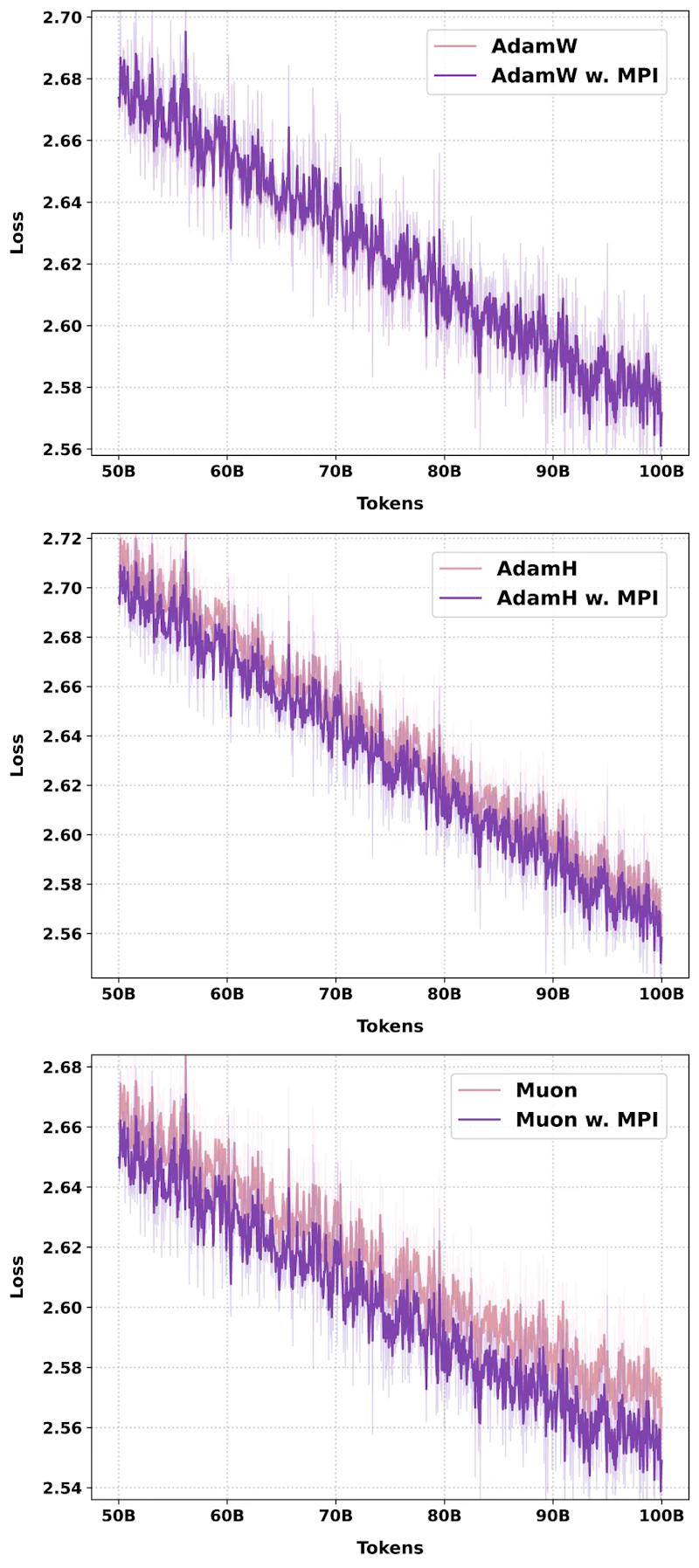
1Bから11Bでの実験結果
研究チームは1B、3B、11Bの3スケールでMoEモデルを事前学習し、MPIの効果を検証しました。1Bモデルでは、AdamW・AdamH・Muonの3つのオプティマイザすべてで損失の改善が確認されています。11Bモデルでの損失低下は0.013でした。
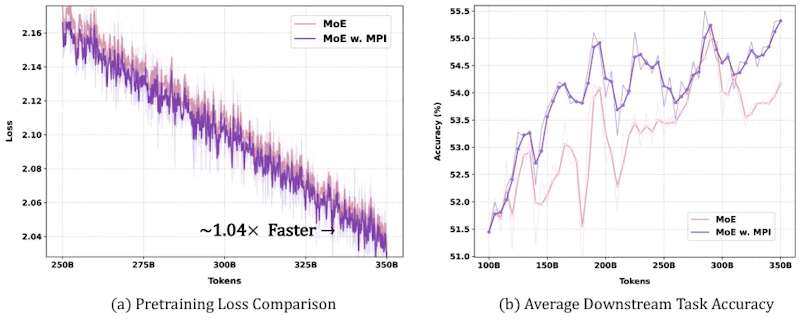
下流タスクの性能も向上しており、3Bモデルでは次の結果が得られています。
- ARC-C(常識推論): 55.91 → 58.96(+3.05ポイント)
- MMLU(知識評価): 47.01 → 48.83(+1.82ポイント)
- 平均精度: 36.37% → 38.70%(+2.33ポイント)
11Bモデルでも同様に、ARC-Cが61.54から62.24、MMLUが50.00から50.93へと改善しています。また負荷分散の指標であるMaxVioも改善しており、バッチ単位での負荷偏りが1.133から1.024へ、全体の偏りが0.964から0.711へと低下しています。
ルーター収縮の重要性
アブレーション実験(要素を個別に除いて効果を測る検証)では、Router Retractionが欠かせない要素であることが明確に示されています。
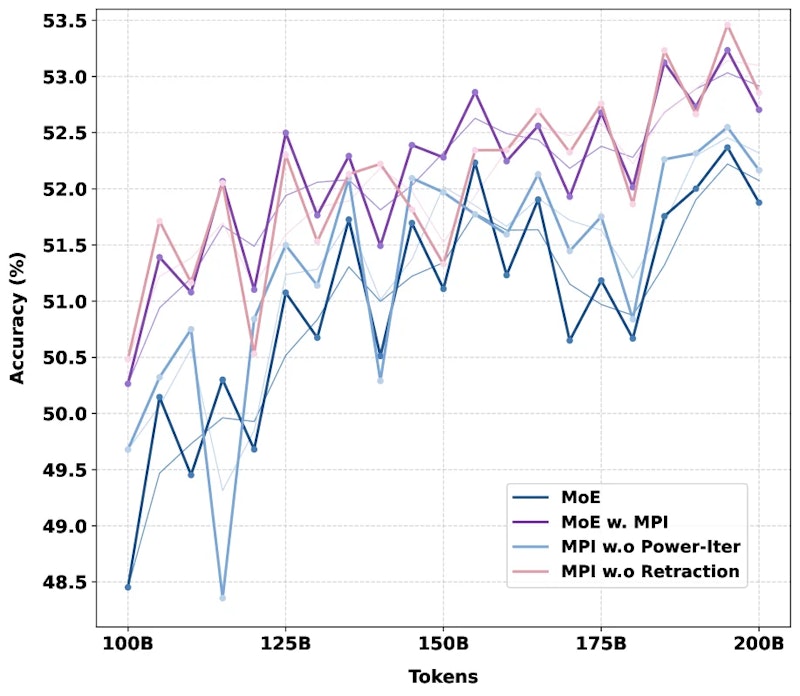
Router Retractionを外すと、AdamWとMuonを使う設定では学習崩壊が発生しました。Power Iterationによってルーター行のノルムが無制限に拡大し、数値的な不安定性が生じるためです。一方でMuonHは重み制約を内部に持つため、Router Retractionがなくても崩壊を回避できています。この非対称な結果は、「ノルム制約を持たないオプティマイザにはRouter Retractionが必須」という設計の論理的一貫性を裏付けています。
まとめ
MPIはMoEのルーター設計に初めて明確な数学的原則を与えた研究です。「エキスパートの主特異方向への整合」という原則は直感的に理解しやすく、実装も軽量です。
DeepSeekやMixtralなどMoEベースのLLMが普及する中で、ルーターの品質がモデル全体のエキスパート活用効率を左右することへの関心が高まっています。MPIが提示する整合原則は、今後のMoEアーキテクチャ設計において参照される指針となる可能性があります。







