
- 総パラメータ30B・アクティブパラメータ3BのMoE構造で、3Bクラスの計算コストを保ちながら長尺動画理解タスクで高性能を発揮
- LongVideoBenchで74.1点を達成し、7倍超のパラメータを持つQwen3-VL 235Bを3.6ポイント上回る同規模モデル最高性能を記録
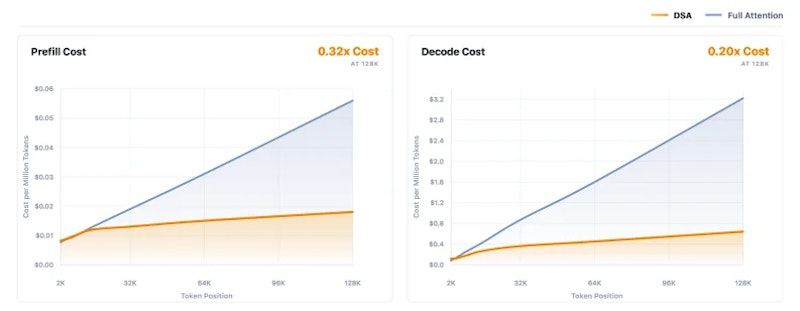
- DeepSeek Sparse Attentionで128Kコンテキスト処理時のprefillコストを3倍以上削減し、長尺動画の実用的な推論を可能にする
研究の背景
動画理解AIの分野では、短いクリップを処理するモデルは多数存在する一方、1時間を超える長尺動画を正確に理解できるモデルはごく限られていました。映画全体のストーリーを追ったり、講義動画の特定の発言を時刻と紐づけて特定したりするには、非常に長い文脈を一度に処理する能力が不可欠です。
加えて、高性能なマルチモーダルモデルは一般に膨大なパラメータを持つため推論コストが高く、実用展開の妨げになりがちです。Kuaishou(快手)の研究チームはこの2つの課題を同時に解決するモデルとして「Keye-VL-2.0-30B-A3B」を開発しました。MoE(Mixture of Experts、専門家混合)アーキテクチャと疎なAttention機構を組み合わせることで、計算効率を保ちながら256Kトークン相当のコンテキスト処理を実現しています。
MoEアーキテクチャとスパースAttention
モデルの核となる設計は、30Bのパラメータを保ちながら推論時のアクティブパラメータを3Bに抑える点にあります。MoEとは、入力ごとに全パラメータを使わず、必要な「専門家モジュール」だけを選択して計算する仕組みです。モデル全体の表現力は30B相当を維持しながら、1回の推論で使う計算量を3B相当に抑えられます。
長文脈処理にはDeepSeek Sparse Attention(DSA)を採用しています。通常のAttentionはトークン数Lの2乗に比例する計算量O(L²)を必要とするため、コンテキストが長くなるほど急速にコストが膨らみます。DSAでは「Lightning Indexer」と呼ばれる軽量モジュールが全クエリトークンから最も重要な2,048トークンを選択し、そのトークン集合のみにAttentionを計算します。計算量はO(Lk)(k=2,048)に抑えられ、128Kコンテキスト処理時のprefillコストを3倍以上、decodeコストを5倍以上削減します。
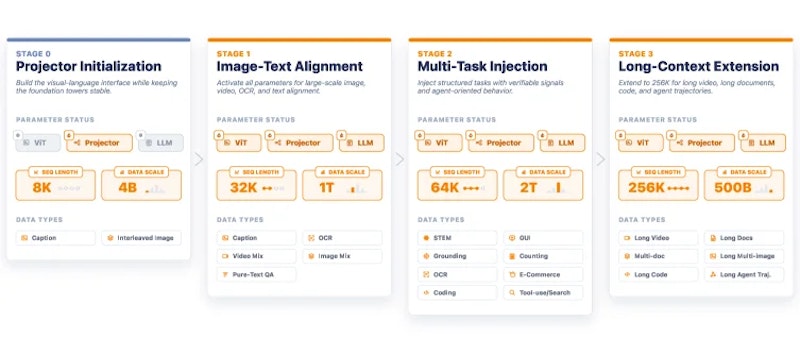
4段階の事前学習パイプライン
モデルは4つの段階を経て事前学習されます。Stage 0ではViTとLLMを固定し、プロジェクタ(視覚特徴とテキスト空間をつなぐ変換層)のみを学習させて画像とテキストの対応関係を確立します。Stage 1では最大32Kコンテキストで約1兆トークンを処理し、画像キャプション、インターリーブ(混在形式)画像テキスト、動画データを学習します。
Stage 2ではコンテキストを64Kに拡張し、約2兆トークンを追加学習します。OCR(文字認識)、数学、GUI操作、物体定位など、タスク固有の能力をこの段階で注入します。最終のStage 3で最大256Kへのコンテキスト拡張を行い、長尺動画・複数ページ文書・長距離エージェント軌跡を処理できるよう訓練します。
学習データの品質向上においては、シーン単位の密キャプション技術が重要な役割を担っています。各動画をシーンに分割し、タイムスタンプ・詳細な説明文・動画全体の概要を付与することで、モデルが動画の時間的な流れを正確に把握できる構造になっています。

後処理段階ではCross-Modal Multi-Teacher On-Policy Distillation(MOPD)と強化学習(Context-RL・Video-RL)を組み合わせています。複数の教師モデルからのトークンレベルの密なフィードバックをMoEバックボーンに蒸留することで、マルチタスク学習時に起きやすい「破滅的忘却」(以前習得した能力が上書きされる現象)を抑制しています。長尺動画の記憶と理解という観点では、MemDreamerが階層グラフメモリで類似の課題に取り組んでおり、この分野全体での研究が活発化しています。
ベンチマーク評価
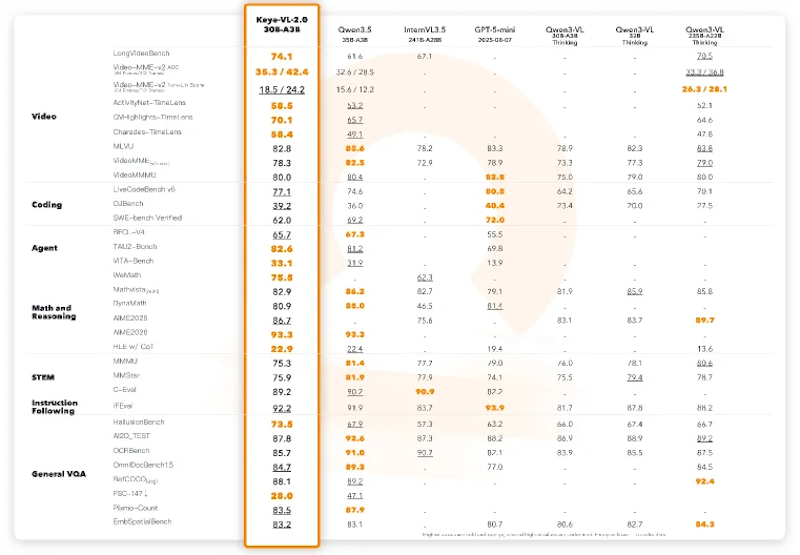
複数の動画理解ベンチマークで競合モデルと比較した結果、Keye-VL-2.0は同規模クラスで最高水準の性能を示しました。長尺動画の質問応答を評価するLongVideoBenchでは74.1点を記録し、同35BクラスのQwen3.5の61.6点を12.5ポイント上回っています。パラメータ数が7倍以上のQwen3-VL 235B(70.5点)をも3.6ポイント超える結果です。
ベンチマーク | Keye-VL-2.0 (30B) | Qwen3.5 (35B) | Qwen3-VL (235B) |
|---|---|---|---|
LongVideoBench | 74.1 | 61.6 | 70.5 |
Video-MME-v2 (512フレーム) | 42.4 | 28.5 | 36.8 |
ActivityNet-TimeLens | 58.5 | 53.2 | 52.1 |
QVHighlights-TimeLens | 70.1 | 65.7 | 64.6 |
Charades-TimeLens | 58.4 | 49.1 | 47.8 |
動画内のどの時点で何が起きたかを細かく特定するTimeLensタスクでも全カテゴリで最高スコアを達成しており、時間的なグラウンディング能力の高さが確認されています。また、Video-MME-v2では512フレームを入力した場合に42.4点を記録し、同35Bクラスの28.5点を13.9ポイント上回っています。
まとめと今後の展望
Keye-VL-2.0は、MoEによる計算効率とDSAによる長文脈処理を組み合わせ、実用的なコストで長尺動画を理解できるマルチモーダルモデルです。アクティブパラメータが3Bと少ないにもかかわらず、7倍超のパラメータを持つモデルを動画理解タスクで上回る点は、疎なアーキテクチャの可能性を示しています。
モデル重みはオープンソースとして公開予定であり、研究者や開発者が自由に利用できる環境が整う見込みです。論文では長尺動画への理解と対話的なエージェント応用への展開が課題として挙げられており、より広い実用場面への適用が期待されます。限界として、256Kコンテキストの処理には依然として高性能なGPUが必要であり、エッジ環境への展開には追加の最適化が求められる点も指摘されています。







