
- 7BパラメータのPLTモデルが2ループ動作でSWE-bench Verifiedスコアを43.0点から64.4点へ大幅に改善。ループ3回以上では27.6点まで逆に低下する非単調効果を実証した
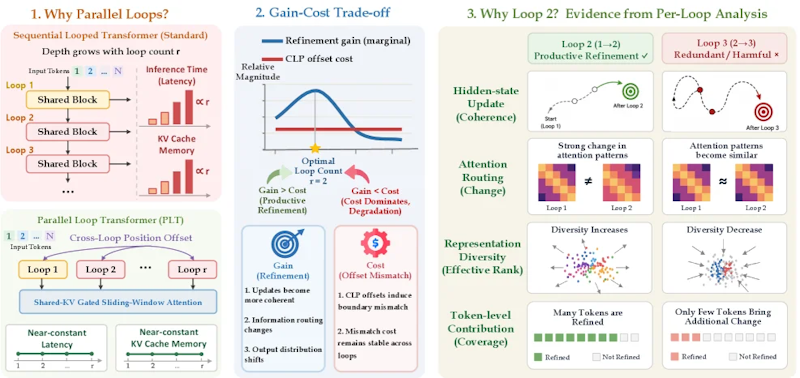
- Cross-Loop Position Offset(CLP)と共有KVゲート付きSliding Window Attentionにより、ループ追加時の遅延とメモリ増加をほぼ一定に抑える効率的な設計を実現
- 有効ランク・角度変化・固定点ギャップなど4つの診断指標が「洗練効果はループ2に集中し、3以降は冗長になる」ことを定量的に明らかに
研究の背景
大規模言語モデル(LLM)の性能向上に、推論の段階で計算量を増やす「推論時スケーリング」というアプローチへの関心が高まっています。モデルのパラメータを増やすのではなく、同じモデルに繰り返し処理を重ねることで精度を引き上げようとする考え方です。
ループ型Transformer(Parallel Loop Transformer、以下PLT)は、同じモデルのレイヤーを複数回通過させることで内部表現を段階的に洗練させる手法です。しかし「ループを増やすほど性能が上がるのか」という根本的な問いには、明確な答えが得られていませんでした。本研究「LoopCoder-v2」はこの問いに理論と実証の両面から踏み込み、7Bパラメータという比較的小さなモデルでコード生成ベンチマークの高水準を達成しました。
PLTのアーキテクチャ
PLTには2つの中核的な仕組みが組み込まれています。一つ目はCross-Loop Position Offset(CLP)です。前のループで計算した隠れ状態を右にシフトしてから現在の埋め込みに加算することで、ループ間の逐次依存をなくし、複数ループを効率的に並列処理できます。
二つ目は共有KVゲート付きSliding Window Attention(G-SWA)です。ループ1で生成したKV(Key-Value)キャッシュを64トークンのウィンドウと学習可能なゲートで融合します。通常はループを重ねるたびにKVキャッシュが膨らみますが、この設計によってメモリ使用量と処理遅延をほぼ一定に保てます。
LoopCoder-v2はこのPLTアーキテクチャを採用した7Bパラメータモデルで、18兆トークンで事前学習後に命令チューニングを施したシリーズです。ループ回数の異なるPLT2・PLT3・PLT4の3種類が用意され、それぞれの性能が比較されています。
ループ2回が最適な理由
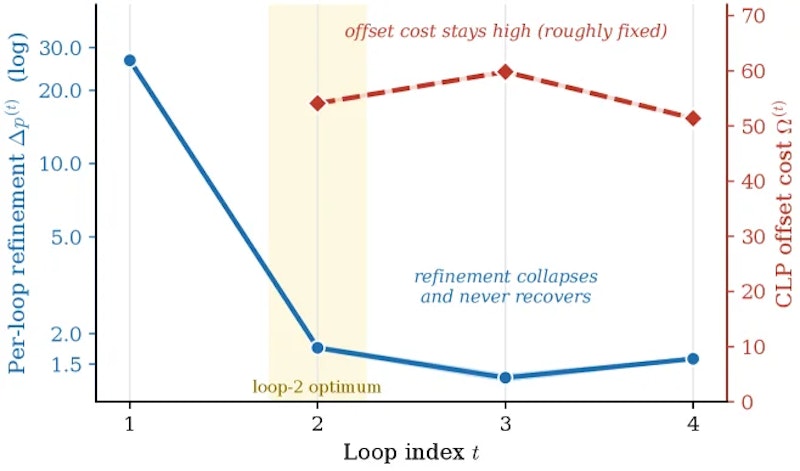
本研究の核心となる発見が「利得とコストの交差(gain–cost scissors)」と呼ばれる現象です。ループを追加するたびに得られる洗練効果(出力分布のKL距離で定量化)はループ2以降に急落します。一方でCLPが生む位置オフセットコストΩ(r)は各ループでほぼ一定のままです。
この結果、ループ3以降ではオフセットコストが洗練効果を30〜45倍以上上回ります。この傾向は複数の診断指標でも確認されており、有効ランクはループ2でピークに達した後、3以降は一貫して下降しました。注意機構のルーティングも2ループ完了後は変化が乏しく、更新が凍りついた状態に近い。
論文では以下4種類の指標を組み合わせてこのメカニズムを解析しています。
- ステップサイズ(δ⁽ʳ⁾): 連続する隠れ状態間のユークリッド距離で、更新の大きさを測る
- 角度変化(cosθ⁽ʳ⁾): 更新方向の一致度。負値は方向反転(振動)を示す
- 有効ランク(erank): 表現の多様性をエントロピーで測定する指標。ループ2でピークを迎える
- 固定点ギャップ(ΔFP⁽ʳ⁾): 残存する洗練余地を直接測定する指標
実験結果
コード生成の主要ベンチマークで、PLT2(ループ2回)はSWE-bench Verifiedで64.4点を達成しました。非ループのベースライン43.0点から21点超の改善です。複数のリポジトリにまたがる修正課題を評価するMulti-SWEでも、14.0点から31.0点へ向上しています。
一方でPLT3(ループ3回)のスコアは27.6点にとどまり、ベースラインを下回るケースも確認されました。ループを増やすほど精度が上がるという直観を覆す数字であり、論文タイトルが「Only Loop Once(1回だけループせよ)」と強調する根拠となっています。
推論時の計算割り当てを動的に制御するという観点では、PoLar(レイヤーの動的スキップ・反復制御)も類似した問題意識を持つ手法として参考になります。
まとめと今後の展望
LoopCoder-v2は「コンパクトなモデルを巧く繰り返す」という戦略の有効性を示しながら、繰り返しに伴うコストを初めて定量的に解明した研究です。7Bパラメータで64.4点という結果は、大規模モデルを使わずにコード生成性能を引き上げたい開発者にとって実践的な設計指針になります。
CLPによるオフセットコストが性能の上限を規定するという発見は、今後のループ型アーキテクチャ設計にも明確な示唆を与えます。オフセットコストを抑えながら洗練効果を維持する改良手法や、問題の複雑さに応じてループ回数をアダプティブに切り替える機構が次の研究課題として浮かび上がります。ループ追加の効果が問題の種類によって変わるかどうかも、今後の検証が待たれる論点です。







