
- アジェンティックRLでGPUカーネルを自動生成・最適化し、KernelBench全体で幾何平均2.11倍(torch.compileより111%高速化)のスピードアップを達成
- Claude Opus 4.5やGemini 3 Proを高速化率で30ポイント以上上回り、最高難易度タスクでもフロンティアLLMを凌駕する性能を実証
- スケーラブルなデータ合成・スキル強化開発環境・安定RL学習の三本柱でCUDA最適化という高難度タスクを完全自動化
研究の背景
深層学習モデルの高速化において、GPUカーネルの最適化は中心的な役割を担っています。CUDAは、NVIDIAが提供するGPUプログラミングプラットフォームですが、高性能なカーネルを書くにはメモリアクセスパターン・スレッド並列化・カーネルフュージョン(複数演算の統合)など多くの専門知識が必要とされています。
従来の自動化手法がこの分野で成果を上げにくかった理由は主に二つあります。GPUカーネルのコード生成には試行錯誤が不可欠であり、単発の生成では品質が安定しないこと、またエラーの自動検出や実行速度の測定が難しく、学習シグナルを得るのが困難なことです。既存の自動化アプローチは特定のパターンへの対応に限られており、汎用的な性能向上には至っていません。このため、AIが自律的にGPUカーネルを設計・最適化するアプローチへの需要が高まっていました。
ByteDance Seedの研究チームは、強化学習(Reinforcement Learning、RL)ならこの問題を解決できるという着眼点でCUDA Agentを開発しました。エージェントが実際にコードを実行し、速度改善という明確なフィードバックを受け取ることで繰り返し学習できるからです。
CUDA Agentの3つの柱
CUDA Agentは、データ合成・開発環境・学習アルゴリズムの三本柱で構成されています。
1. スケーラブルなデータ合成パイプラインまず、PyTorchとTransformerライブラリから演算子を収集してシードとします。次に、LLMが最大5種類の演算子をランダムに組み合わせて合成演算子を生成します。最後に、実行可能性・再現性・処理時間(1〜100ミリ秒)の条件を満たすものだけを選択します。この工程を通じて、6,000件の学習用サンプルセット「CUDA-Agent-Ops-6K」が構築されます。
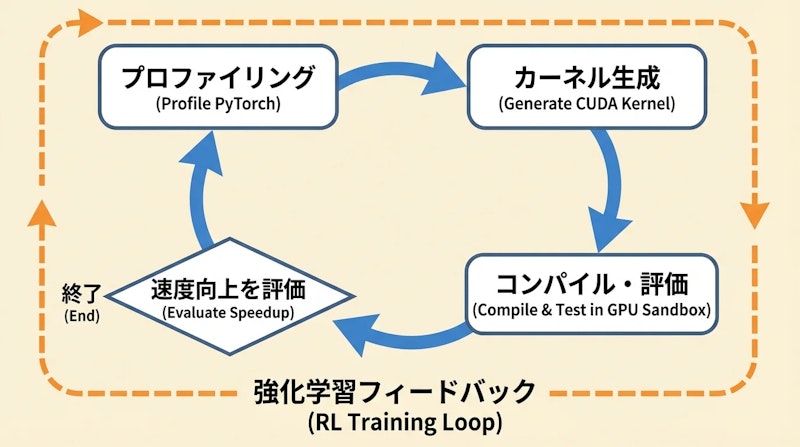
2. スキル強化CUDA開発環境エージェントは定められたループに従って動作します。まずネイティブのPyTorchコードをプロファイリングしてボトルネックを特定し、カスタムCUDA演算子を実装したコードを生成して、GPUサンドボックス環境でコンパイルと実行を繰り返します。5%以上の速度改善が確認されるまでこのサイクルを継続するため、一発生成にとどまらない反復的な最適化が実現されます。報酬ハッキングを防ぐため、ファイルアクセス制限や実行時間制約も設けられています。
3. 安定したRLアルゴリズム学習の安定化には三段階の工夫が施されています。最初に、ベースモデルをPPO(Proximal Policy Optimization)で初期チューニングする「シングルターンウォームアップ」を実施します。続いて、高品質なロールアウトのみを使った「拒絶ファインチューニング(RFT)」でアクターを初期化し、GAE(Generalized Advantage Estimation)を用いたバリュープリトレーニングでクリティックを初期化します。この三段階によって、当初17ステップで崩壊していた学習が、200ステップにわたって安定して継続できるようになっています。
KernelBenchでの実験結果
評価にはGPUカーネル最適化の標準ベンチマーク「KernelBench」を使用しました。このベンチマークは、単一演算子(Level-1)・複合演算子(Level-2)・モデルレベル(Level-3)の3段階で構成されており、難易度が上がるほど最適化が困難になります。
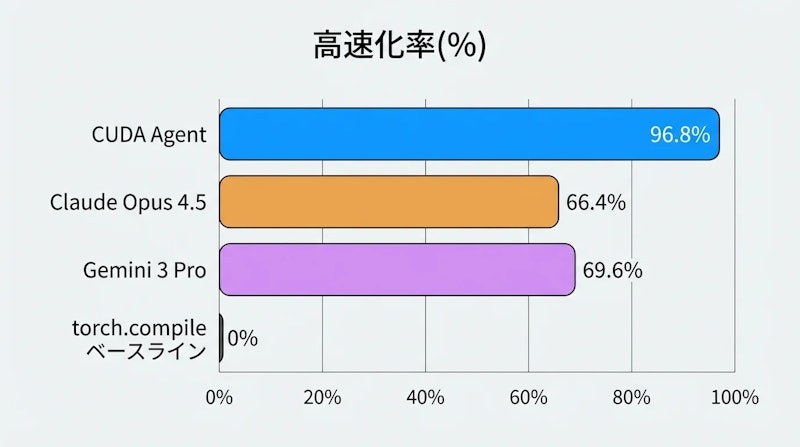
CUDA Agentは全体の通過率98.8%を達成し、96.8%のケースでtorch.compileを上回りました。幾何平均のスピードアップは2.11倍(torch.compileより111%高速化)に達しています。レベル別では、Level-2が最大の2.80倍スピードアップを記録し、Level-1も1.87倍を達成。最難易のLevel-3でも1.52倍のスピードアップを示しています。
指標 | Level-1 | Level-2 | Level-3 | 全体 |
|---|---|---|---|---|
通過率 | 100% | 100% | 94% | 98.8% |
高速化率(vs torch.compile) | 97% | 100% | 90% | 96.8% |
スピードアップ倍率 | 1.87倍 | 2.80倍 | 1.52倍 | 2.11倍 |
LLMエージェントへの強化学習適用は近年急速に研究が進んでいますが、CUDA Agentはカーネル生成という具体的なエンジニアリング課題でその有効性を示しました。Claude Opus 4.5(高速化率66.4%、1.46倍)やGemini 3 Pro(高速化率69.6%、1.42倍)と比べると、高速化率で30ポイント以上の差があり、スピードアップ比でも約44〜49%上回っています。
アブレーション研究ではエージェントループを取り除くと高速化率が96.8%から14.1%に激減することが確認され、反復的な最適化サイクルが性能の核心であることが裏付けられています。また、離散的な報酬(マイルストーン型)を採用した「ロバスト報酬スキーム」が、連続的なスピードアップ報酬と比べて大幅に安定した学習を実現しています。
まとめと今後の展望
CUDA Agentは、アジェンティック強化学習をGPUカーネル最適化という専門的な領域に適用し、torch.compileやフロンティアLLMを大きく超える結果を示しました。三本柱の設計がそれぞれ重要な役割を果たしており、特にエージェントループの有無が性能に決定的な差をもたらすことがアブレーション研究で示されています。
一方で、現時点ではNVIDIA H20 GPUでの評価に限られており、異なるGPUアーキテクチャへの汎用性については今後の検証が必要です。Level-3の通過率が94%と他レベルより低い点も、さらなる改善の余地を示しています。ベースモデルにはSeed1.6(230億パラメータ規模)が使用されており、より小規模なモデルへの適用可能性も今後の研究課題といえます。
AIがGPUコードを自律的に最適化する仕組みは、深層学習インフラのコスト削減や性能向上に直結します。CUDA Agentは、こうした自動最適化の実用化に向けた重要な一歩として位置づけられます。







