
- LLMエージェントのRL訓練における探索ボトルネックを、自己生成メモリ「Tips」の活用で解消する新フレームワーク
- オンポリシー更新とオフポリシー蒸留を確率的に切り替えるハイブリッド最適化で、ScienceWorldでGRPO比128.6%の改善を達成
- 新タスクへの適応時はパラメータ更新なしでメモリのみを追加するだけで平均136%の改善を実現し、高い汎化性を示す
LLMエージェントの探索問題
強化学習(RL)によってLLM(大規模言語モデル)エージェントを訓練する際、最大の壁となるのが「探索(exploration)」です。エージェントが未知の環境で適切な行動を学ぶためには、試行錯誤を繰り返して報酬を得られる行動パターンを発見する必要があります。しかし現実の複雑なタスク環境では、有益な報酬シグナルを得られる状態に到達すること自体が非常に難しく、学習が停滞しやすいという問題があります。
既存のRL手法、特にGRPO(Group Relative Policy Optimization)では、エージェントは過去の経験を有効活用できず、同じ失敗を繰り返す傾向があります。また、メモリを活用して探索を補助するアプローチも、テスト時にメモリが使えない場合に性能が低下するという課題を抱えていました。
EMPO²の全体設計
ICLR 2026に採択された本論文が提案するEMPO²(Exploratory Memory-augmented LLM Agent via hybrid On- and Off-policy optimization)は、メモリ拡張とハイブリッドRL更新を組み合わせた新しい訓練フレームワークです。
EMPO²の核心は、エージェントが軌跡を振り返り自己生成した「Tips」(探索ヒント)をメモリバッファに蓄積する仕組みにあります。たとえば「赤い電球が見つからず、タスクを完了できなかった」「緑の端子にバッテリーを接続すると電球に電力が供給される」といった具体的な教訓がTipsとして記録されます。以降の試行では、現在の状況に類似したTipsをメモリから検索し、エージェントのプロンプトに付加することで探索を効果的に誘導します。
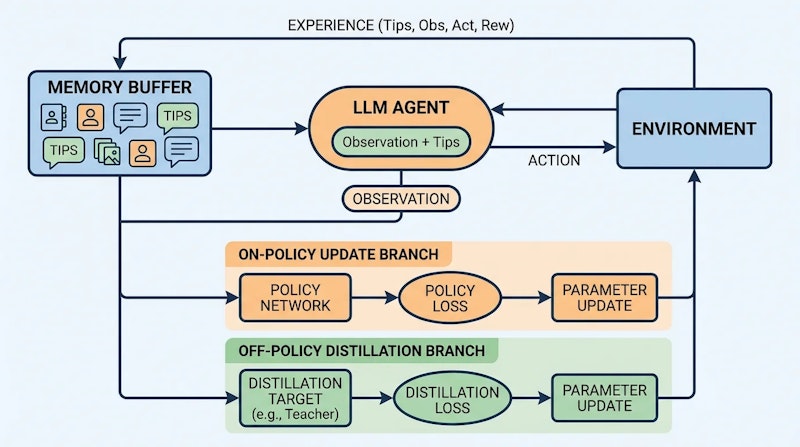
ハイブリッド更新の仕組み
EMPO²のユニークな点は、ロールアウト(試行)と更新を確率的に切り替えるハイブリッド設計にあります。ロールアウト時には確率pでTipsをプロンプトに付加し、残りは通常の観測のみで行動させます。
更新フェーズでは2つの戦略を組み合わせます。オンポリシー更新では、Tipsを付加したまま同じプロンプトで方策を更新します。一方、オフポリシー蒸留では、Tipsなし版の行動確率に置き換えて勾配を計算します。これにより、Tipsに頼って得た報酬付き経験から「メモリなしでも同じ行動を選べる方策」への知識蒸留が実現します。テスト時にメモリが使えない状況でも、学習済みの知識が方策パラメータに内在化されているため性能が維持されます。
学習の安定化のために、確率が非常に低いトークンに対しては勾配のマスキングを適用し、勾配爆発を防いでいます。探索促進のための内在的報酬として、過去に類似した状態が少ないほど高い報酬を与える仕組みも導入されています。
LLMの強化学習では方策の陳腐化(staleness)も課題の一つです。VESPOはこの問題を変分定式化で解決するアプローチを提案していますが、EMPO²はメモリによる探索強化という別の切り口で根本的な課題に対処しています。
実験結果
ベースモデルにQwen2.5-7B-Instructを使用し、2つのベンチマークで評価しています。
ScienceWorldベンチマーク(19種の科学実験タスク)では、比較手法のGRPOがスコア33.2を達成したのに対し、EMPO²は75.9を記録し、128.6%の改善を達成しました。Naive(訓練なし)のスコアが-61.3であることを踏まえると、タスクの難易度の高さが窺えます。
WebShopベンチマーク(オンラインショッピングタスク)では、GRPOのスコア84.4・成功率72.8%に対し、EMPO²はスコア88.3・成功率76.9%を記録しました。
手法 | ScienceWorld | WebShop スコア | WebShop 成功率 |
|---|---|---|---|
Naive | -61.3 | - | - |
GRPO | 33.2 | 84.4 | 72.8% |
EMPO² | 75.9 | 88.3 | 76.9% |
分布外適応実験では、未知のタスクに対してパラメータ更新なしでメモリのみを追加する設定で10ステップのインタラクションを行い、平均136%の改善を達成しています。これはEMPO²が未見タスクへの適応においても高い汎化性を持つことを示す結果です。
まとめ
EMPO²は、自己生成Tipsによるメモリ拡張とハイブリッドRL更新の組み合わせにより、LLMエージェントの探索能力を大幅に向上させました。オフポリシー蒸留によってメモリへの依存を解消し、テスト時の汎化性を確保している点は実用上の利点です。
課題としては、Tipsの品質がメモリバッファの内容に依存するため、初期段階では有益なTipsが少なく探索効率が低下する可能性があります。また、本研究はQwen2.5-7Bでの検証にとどまっており、より大規模なモデルでの有効性は今後の検証が待たれます。







