
- 分子とタンパク質の配列・3D構造・自然言語を外部エンコーダなしで処理する初のマルチモーダル生物学基盤モデル
- 304億トークンで事前学習し、80の下流タスク中77でSOTAまたは競合性能を達成
- Qwen3ベースの1.7B/4Bパラメータモデルをオープンソースで公開、創薬・タンパク質設計への応用が期待される
研究の背景と課題
生命科学の分野では近年、タンパク質構造予測モデルのAlphaFold、タンパク質配列モデルのESMシリーズ、分子生成モデルなど、特定の用途に特化した専用モデルが目覚ましい成果を上げてきました。しかし創薬や分子設計の現場では、分子の化学構造・3次元的な立体形状・文献やデータベースに記されたテキスト情報を横断して理解することが求められます。
こうした複合的な情報処理に対して、既存のモデルはおおよそ2つの限界を抱えていました。1つは、分子かタンパク質のどちらか一方しか扱えないこと、もう1つは、複数のモダリティ(情報形式)を扱う場合に外部エンコーダやアダプターを組み合わせる設計を採っており、各モダリティを統合的に理解する能力が不十分だったことです。分子の配列表現・3D構造・自然言語テキストを一貫したフレームワークで処理できるモデルはこれまで存在しませんでした。
タンパク質理解とAI研究の融合は急速に進んでおり、AlphaFold開発者のジャンパー氏がAnthropicへ移籍したことも、この分野への注目の高さを示しています。BioMatrixはこうした潮流のなかで、分子・タンパク質・言語の3軸を統合する包括的な基盤モデルとして提案されました。
BioMatrixの提案手法
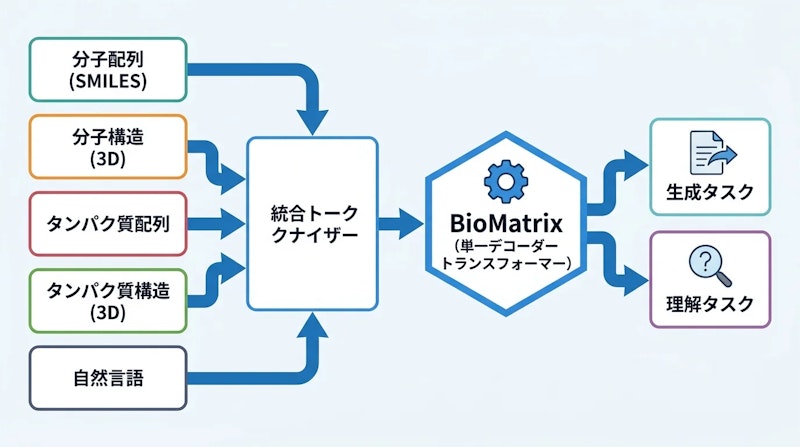
BioMatrixの核心は、異なるモダリティのデータをすべて共通の離散トークン空間に変換する「統一トークン化スキーム」にあります。扱うモダリティは5種類で、分子配列(SMILES・SELFIES記法)、分子3D構造、タンパク質配列、タンパク質3D構造、そして自然言語テキストです。これらのデータは性質がまったく異なりますが、専用のトークン化処理を通じてすべてを同一の語彙空間に変換します。
この統一トークン空間を採用したことで、モデルは外部エンコーダやモダリティ間の変換を担うアダプターモジュールを一切必要としません。学習目的は「次のトークンを予測する」という自己回帰型の予測に統一されており、大規模言語モデルと同じ原理で全モダリティを処理できます。異なる情報形式の関係をモデルが自然に学習できるという点で、この設計はシンプルながら強力です。
ベースモデルにはQwen3の1.7Bパラメータ版と4Bパラメータ版を採用しています。事前学習には総計304億トークン規模のデータセットを使用しており、内訳は一般的な自然言語テキスト、科学論文・データベースなどのドメイン固有テキスト、分子・タンパク質の配列と3D構造データ、さらに分子とタンパク質の相互作用データです。この多様なデータ構成が、モダリティをまたぐ理解能力の基盤となっています。
実験結果
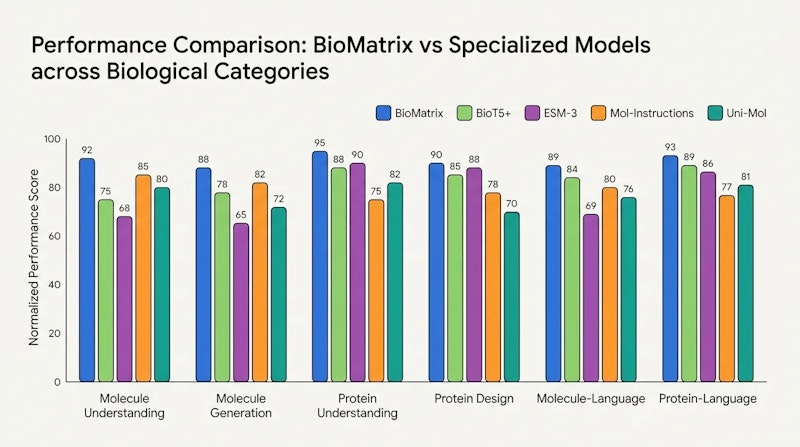
BioMatrixの性能は、分子理解・分子生成・タンパク質理解・タンパク質設計・分子言語・タンパク質言語という6カテゴリにまたがる計80の下流タスクで検証されました。結果として77タスクでSOTA(最先端の性能)またはそれに匹敵する水準を達成しています。
比較対象には各分野を代表する専用モデルが選ばれています。分子言語タスクではMol-InstructionsやMolCA、タンパク質配列モデルではMetaのESM-2・ESM-3、マルチタスク対応の生物学言語モデルとしてはBioT5+、分子3D構造の理解ではUni-Molが主要な比較相手となっています。これらはそれぞれのドメインで高い実績を持つ専門モデルですが、単一モデルで全領域を横断的にカバーすることはできません。
特に顕著な性能向上が見られたのは分子言語タスクとタンパク質言語タスクの2カテゴリです。テキストで与えられた説明から対応する分子構造を生成する「テキスト→分子生成」タスクや、分子の特性をテキストで記述する「分子キャプション生成」タスクは、複数のモダリティをまたぐ処理が必要です。こうしたクロスモーダルなタスクでは、外部エンコーダを利用する従来手法と比べてBioMatrixが安定した優位性を示しました。タンパク質側でも、機能アノテーションのテキスト生成やテキスト記述からの構造誘導タスクで同様の傾向が確認されています。
一方、モデル規模は最大でも4Bパラメータとコンパクトです。Qwen3の事前学習された言語理解能力を土台にしつつ、生物学専用のトークン化と追加事前学習によって専門性を付加することで、大規模化せずに高い性能を引き出す設計思想が反映されています。3D構造を伴う複雑な相互作用予測など、一部のタスクでは改善の余地が残っており、これらは今後の課題として明示されています。
まとめと今後の展望
BioMatrixは「生物学的な情報は本来マルチモーダルである」という前提に立ち、配列・構造・言語のすべてを外部モジュールに頼らず単一モデルで処理するアプローチを実証しました。80タスク中77でSOTAまたは競合性能を達成した成果は、統一トークン化と自己回帰型学習という組み合わせが生物学基盤モデルとして有効であることを示しています。
応用面では創薬や分子設計への貢献が期待されます。標的タンパク質の構造情報と関連文献を同時に参照しながら候補分子を生成するといった、これまで複数の専用ツールを組み合わせなければ実現できなかったワークフローを、BioMatrix単体で扱える可能性があります。生物学的な概念を自然言語で問い合わせると構造データで応答するような対話的な分析も視野に入ります。
今後の課題としては、より大規模なパラメータへのスケールアップ、ゲノム配列やRNA構造など新たなモダリティへの拡張、そして複雑な相互作用予測タスクでの性能改善が挙げられます。モデルの重みとコードはGitHubおよびHugging Face上でオープンソースとして公開されており、研究コミュニティによるさらなる発展が期待される研究です。







