
- LRM(大規模推論モデル)をガイドとして活用する「LRM-as-a-Guide」機構で、追加学習なしにOLLMの推論能力を強化
- Jensen-Shannon発散による自動重み調整「Stepwise Contrastive Scaling」が知覚と推論のバランスを動的に最適化
- MathVistaで70.2、MMAUで75.5を達成し、任意のOLLMに適用可能な汎用フレームワークとしてICLR 2026に採択
研究の背景と課題
音声・画像・テキストを同時に処理できるオムニモーダル大言語モデル(Omni-modal Large Language Model:OLLM)は、近年めざましい進化を遂げています。しかし、多様なデータを知覚する能力に優れる一方で、複雑な数学的推論や多段階の論理的思考を要するタスクでは、テキスト専用モデルに劣る場面が少なくありません。
一方、テキストを専門とする大規模推論モデル(Large Reasoning Model:LRM)は、思考の連鎖(Chain-of-Thought)などの手法によって複雑な推論を得意としています。OLLMにこの推論能力を組み込もうとすると、通常は大規模な追加学習や専用データの収集が必要です。計算コストと準備のハードルが高く、実用上の障壁となっていました。
本論文が提案する「ThinkOmni」は、訓練もデータ収集も必要とせずにOLLMの推論能力を引き上げることを目指したフレームワークです。ICLR 2026に採択されており、その有効性が研究コミュニティに認められています。
ThinkOmniの全体像
ThinkOmniの核となるアイデアは、OLLMがトークンを生成する際に既存のLRMを「ガイド」として並走させる点にあります。このアプローチは「LRM-as-a-Guide」と呼ばれており、推論信号の統合モジュールと動的な重み調整モジュールの2つで構成されています。
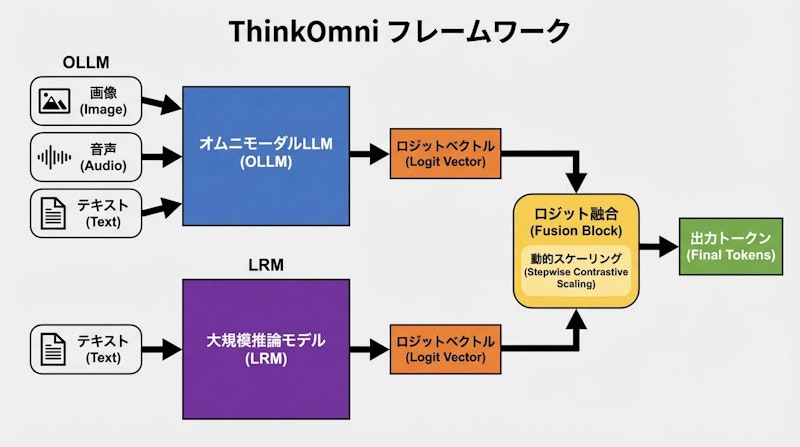
LRM-as-a-Guide機構
OLLMは通常、モデル内部の確率分布(ロジット)に基づいて次のトークンを選択します。ThinkOmniでは、この過程にLRMが同じテキスト入力から生成した推論ロジットを加算します。数式的には ẑ = z_base + α·(z+ - z-) で表され、LRMの推論パターンをOLLMのデコーディングに直接注入する仕組みです。
ここでz_baseはOLLMの通常の出力ロジット、z+はLRMが生成した推論信号、αはスケーリング係数です。この操作によりOLLMは、マルチモーダル入力を知覚しながらLRMの推論能力も参照できます。既存のOLLMとLRMを組み合わせるだけで利用できるため、新たなモデル学習は一切不要です。
段階的対照スケーリング
推論信号を単純に加算するだけでは、場面によって知覚と推論のバランスが崩れる可能性があります。ThinkOmniでは各デコードステップで、Jensen-Shannon(JS)発散を用いて知覚信号と推論信号の相違度を測定します。相違度が大きいほど推論信号の重みを高め、小さいほど知覚信号を優先するという動的な調整が行われます。
この仕組みにより、スケーリング係数αをステップごとに自動で決定できます。手動でのハイパーパラメータ探索が不要となり、異なるモデルや異なるタスクでも安定した性能が得られます。大規模マルチモーダルモデルの改善フレームワークであるDPEのような学習ベースの手法と比較すると、ThinkOmniはモデルの重みを一切変更しない点が大きな特徴です。
実験結果
ThinkOmniはQwen2.5-Omni-7Bをベースモデルとし、6つのマルチモーダル推論ベンチマークで評価されました。主要な結果を以下に示します。
ベンチマーク | ベースライン | ThinkOmni | 改善幅 |
|---|---|---|---|
MathVista | 66.8 | 70.2 | +3.4 |
MathVision | 25.0 | 32.9 | +7.9 |
MMAU | 71.5 | 75.5 | +4.0 |
特にMathVisionでは+7.9ポイントの改善が見られ、視覚情報を伴う数学的推論において効果が顕著でした。訓練済みの手法であるOmni-R1やHumanOmniV2と同等以上の性能を、学習なしで達成しています。
平均ロジット融合やCaption-then-Answerといったシンプルな統合手法と比較しても、動的な重み調整の効果が数値に表れており、Stepwise Contrastive Scalingの設計が性能に直結していることが確認されました。
限界と今後の課題
ThinkOmniには現時点で2つの制約があります。1つ目は、OLLMとLRMが語彙(ボキャブラリー)を共有している必要がある点です。語彙が異なるモデルの組み合わせには適用できません。
2つ目は推論コストです。LRMの追加フォワードパスが必要なため、生成時間がベースラインの約2.88倍になります。リアルタイム応用での利用には制約となり、今後の効率化が課題として残ります。
まとめ
ThinkOmniは、LRM-as-a-Guide機構とStepwise Contrastive Scalingを組み合わせることで、追加学習なしにOLLMの推論能力を高めます。既存のモデルをそのまま活用できる汎用性の高さと、任意のOLLMに適用可能な設計が強みです。
マルチモーダル推論の改善に取り組む研究者や実務者にとって、学習コストをかけずに推論能力を底上げできる実践的な選択肢をもたらす研究といえます。語彙共有の制約や推論速度の課題が解決されれば、活用範囲がさらに広がるでしょう。






