
- 弱点診断・標的データ生成・強化学習のスパイラルループでLMMを自律的に改善するDPEフレームワークを提案し、固定データ依存の従来訓練手法に代わる新パラダイムを示した
- Qwen3-VL-8BとQwen2.5-VL-7Bで11のベンチマーク全てに継続的な性能改善を確認し、わずか1,000サンプルで既存手法の8,000サンプルを上回る効率を実現した
- コード・モデル・データをGitHubで全公開しており、再現性の高いオープンソース実装として研究コミュニティに広く提供されている
研究の背景
Large Multimodal Model(LMM、大規模マルチモーダルモデル)は、画像とテキストを統合的に理解・推論できるAIシステムとして急速に普及しています。しかし、その訓練プロセスには見過ごされがちな根本的な問題があります。現在の主流な手法は固定された静的データセットに依存しており、モデルがどの能力領域で弱点を持つかを特定したうえでデータを整備する仕組みが欠けていました。
たとえば、あるモデルが幾何学的推論や医療画像の理解に苦手な部分を持っていても、汎用的なデータセットではその領域のサンプルが十分に含まれているとは限りません。研究チームは「繰り返し練習より診断に基づくフィードバックのほうが効率的である」という教育学の知見に着目し、これをLMM訓練へ応用するフレームワークの開発に取り組みました。
提案手法
本論文が提案するDiagnostic-driven Progressive Evolution(DPE)は、診断・標的データ生成・強化学習という3段階の処理を螺旋的に繰り返すフレームワークです。1回の反復で得た改善結果を次の反復の出発点にすることで、モデルは継続的に自分の弱点を克服していきます。
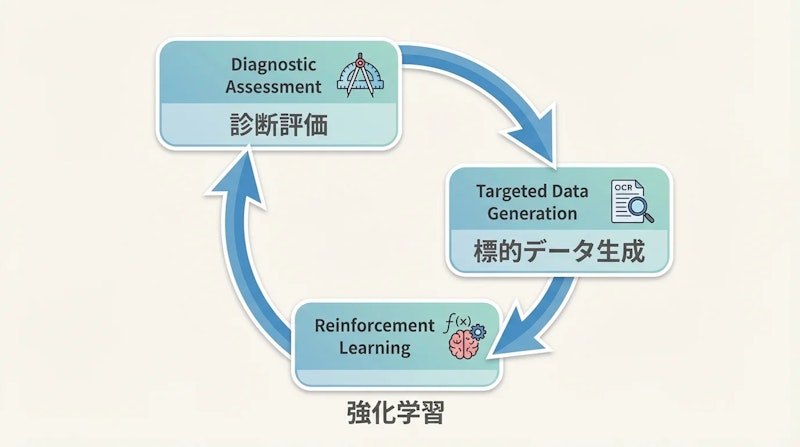
最初の診断フェーズでは、200件のサンプルを用いてモデルの回答精度を段階的に評価し、幾何学的推論・医療画像・統計グラフ・OCRなど12次元の能力空間で弱点領域を特定します。この診断結果をもとに、次フェーズで生成すべきデータの種類と分量が動的に決まります。弱点が特定されるほど、そこに集中したデータが自動的に補充される仕組みです。
マルチエージェントによるデータ生成
DPEの新規性の中心は、マルチエージェントシステムによる弱点特化型データの自動生成にあります。4つの専門エージェントが協調して、ラベルなしの多様なマルチモーダルデータから訓練サンプルを自律的に生成します。
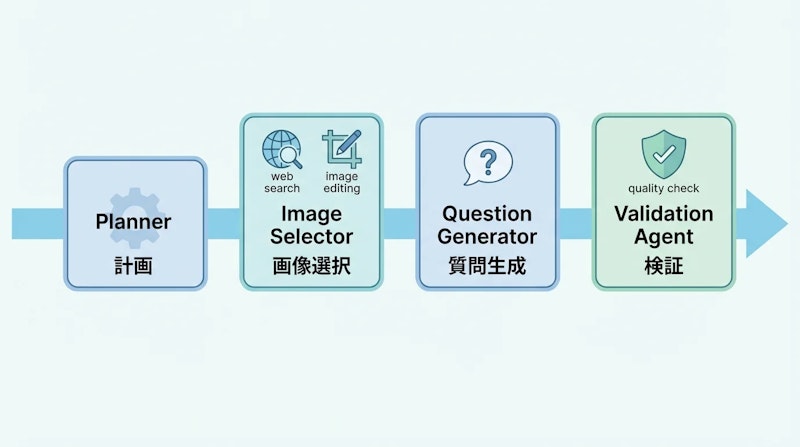
プランナーエージェントが能力カテゴリと質問要件を決定し、画像選択エージェントが外部プール検索・画像編集・合成によって適切な画像を調達します。質問生成エージェントが画像に基づく質問と解答を作成し、最後に検証エージェントがカテゴリ一貫性・回答可能性・検証可能性・形式遵守の4基準でゲーティングを行います。生成されたデータは強化学習フェーズに渡され、モデルは検証可能な報酬シグナルをもとに弱点領域での推論能力を高めます。
実験結果
DPEはQwen3-VL-8BとQwen2.5-VL-7Bの2モデルで評価され、11のベンチマーク全てで継続的な性能改善が確認されました。主要な結果を以下に示します。
ベンチマーク | カテゴリ | 改善幅(Iter3) |
|---|---|---|
CharXivRQ | OCR・グラフ | +4.11 |
MathVista | 数学的推論 | +4.00 |
HallusionBench | 幻覚抑制 | +3.99 |
MMMU | STEM総合 | +3.33 |
MMStar | マルチモーダル推論 | +2.33 |
MathVerse | 数学視覚推論 | +2.08 |
RealWorldQA | 実世界理解 | +1.83 |
DPEはわずか1,000サンプルの弱点特化型データで、8,000サンプルを用いる既存の比較手法を上回る性能を達成しています。8BモデルがMathVisionで72Bクラスのモデルを凌駕するという結果は、Mobile-Oのような軽量マルチモーダルモデルの研究とあわせて、パラメータ規模に頼らない能力向上の可能性を示すものです。
まとめと今後の展望
DPEは、固定データセットへの依存を脱却し、モデル自身の弱点を起点にした反復的な自律改善を可能にするフレームワークです。モデルサイズや対象タスクを問わず安定した改善効果が得られており、LMM訓練の新たなアプローチとして注目されます。
一方で課題も残ります。診断に使うサンプルプールが固定されているため初期バイアスが引き継がれるリスクがあり、エージェントの稼働にOpenAI o3やClaude Sonnet等の高性能モデルが必要で、オープンソース環境での完全な再現性は未検証です。反復回数を増やした際の計算コストや収束条件の詳細も今後の検討課題として挙げられています。コード・モデル・データはGitHub上で公開されており、コミュニティによる検証と発展が期待されます。






