
- 拡散言語モデルは理論上は並列デコードが可能だが、実際には左から右へ自己回帰的に収束する傾向があることをARness指標で初めて定量化した
- 根本原因は訓練データの逐次的な構造にあり、DLMの目的関数との不一致がARnessスコアを高めていた
- 提案手法NAPは独立した推論軌跡でデータを構成し直すことで、GSM8Kの256ステップ評価で60.9%を達成(標準CoT比+14.4ポイント)
研究の背景
大規模言語モデル(LLM)の推論効率を高める手法として、拡散言語モデル(Diffusion Language Model、DLM)が近年注目を集めています。Transformerが1トークンずつ逐次生成するのに対し、DLMはノイズ除去プロセスを通じて複数トークンを同時に生成できると期待されてきました。LLaDAやDreamといったモデルが登場し、並列デコードによる高速化の可能性が示されていました。
しかし現実には、DLMを数学推論などの複雑なタスクに適用すると、デコードステップ数を減らすにつれて性能が急落するという問題が観察されていました。「並列生成できるはずなのに、なぜ性能が落ちるのか」という疑問に対して、本論文は体系的な因果分析を通じて初めて明確な答えを提示しています。
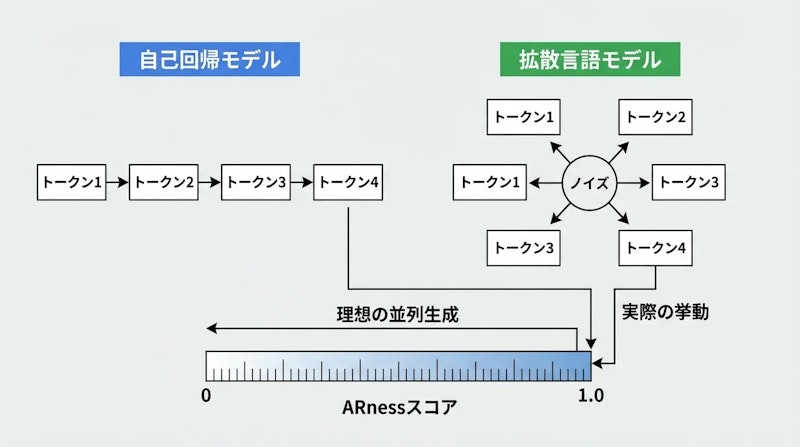
ARnessで測る自己回帰性
研究チームはまず、DLMが実際にどの程度「自己回帰的」に振る舞っているかを定量化する指標「ARness(Global-ARness@1)」を導入しました。この指標は、モデルが左から右へ向かって厳密に生成を行っている度合いを0から1のスコアで表します。スコアが1.0に近いほど完全に自己回帰的な挙動を示します。
計測の結果、LLaDA-8BのARnessは0.73、Dream-7Bはさらに高い0.92を示しました。本来なら均等に分散した並列生成が期待されるところ、実際にはほぼ左から右への処理が行われていたのです。また、Fast-dLLMのような既存の高速化手法は、この自己回帰的パターンを解消するのではなく、むしろ強化してしまうことも明らかになりました。
根本原因はデータの逐次的構造
なぜDLMはこれほど自己回帰的に振る舞うのでしょうか。研究チームはSeqDep(Sequential Dependence、逐次依存性)分析を用いて、訓練データそのものに強い順序依存性があることを実証しました。OpenR1-Mathのような数学推論データセットでは、後続のステップが必ず前のステップの文脈に依存する形で記述されています。
DLMの目的関数は本来、任意の位置のトークンを独立してノイズ除去できるよう設計されています。しかし訓練データが「ステップ1→ステップ2→…」という直線的な論理構造を持つ以上、モデルはデータから逐次的なパターンを学習してしまいます。この「DLMの目的関数と訓練データの構造的ミスマッチ」こそが、並列デコード失敗の根本原因として特定されました。長CoT(Chain-of-Thought)データで追加学習すると、LLaDAのARnessは0.73から0.81にさらに上昇することも確認されており、一般的なファインチューニングが問題を悪化させる可能性が示されています。
NAP手法の設計
この診断に基づき、研究チームが提案したのがNAP(Non-Autoregressive Parallel)手法です。NAPはモデルアーキテクチャを変えるのではなく、訓練データの構成方法そのものを変えるデータ中心のアプローチを採用しています。
具体的には、同一の問題に対して複数の独立した推論軌跡(温度τ=1.0でサンプリング)を生成し、それらを1つの訓練インスタンスにまとめます。各軌跡は互いに独立しているため、モデルは「前の軌跡に依存して次を生成する」というパターンを学習できなくなります。エラーを含む軌跡もあえて取り込むことで、モデルはノイズのある情報から正しい答えを識別する能力も獲得します。画像拡散モデルの分野でも推論の並列化・高速化を追求するDDiTが提案されているように、拡散モデルにおける効率的な推論設計は共通の重要課題です。
推論時には、マクロ-マイクロ階層構造の並列デコード戦略を適用します。マクロレベルでは複数の推論ブロック間で厳密な並列処理を強制し、ミクロレベルでは各ブロック内の信頼度ベースの更新を柔軟に許可する設計です。これにより、並列性を保ちながら各ブロック内の品質も担保しています。
実験結果
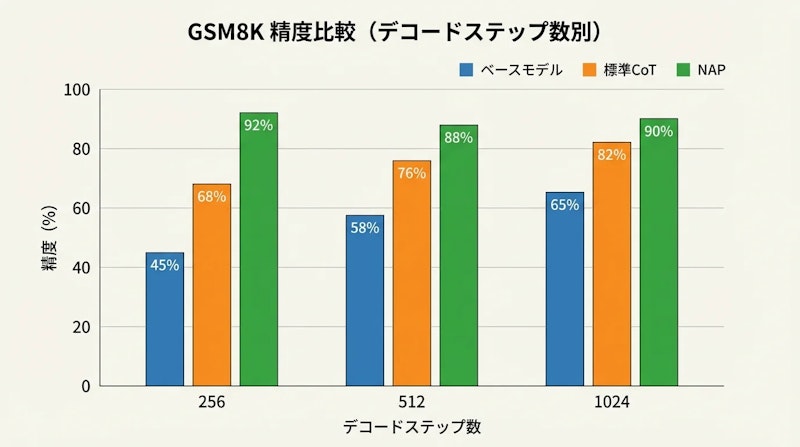
数学推論ベンチマークGSM8KとMATH-500を用いて、Dream-7Bベースでの性能を検証しました。NAPの効果は特に少ないデコードステップ(高い並列性)の条件で顕著です。
デコードステップ数 | ベースモデル | 標準長CoT | NAP |
|---|---|---|---|
256ステップ | 35.0% | 46.5% | 60.9%(+14.4pt) |
512ステップ | 49.4% | 56.9% | 70.9%(+14.0pt) |
1024ステップ | 68.9% | 78.0% | 83.6%(+5.6pt) |
GSM8Kでは256ステップという少ないステップ数でNAPが60.9%を達成し、標準長CoTファインチューニングの46.5%を大きく上回りました。MATH-500においても、256ステップでNAP-Dream-7Bが23.8%を達成し、ベースモデルの8.8%から大幅に改善しています。デコードステップが少ない条件ほどNAPの優位性が拡大する傾向は、手法がまさに並列デコードの本質的な問題を解決していることを示しています。
まとめと今後の展望
本研究は「DLMは並列デコードができる」という前提に根拠ある疑問を投げかけ、ARnessとSeqDep分析によってその原因を訓練データの構造的問題として特定しました。解決策も、モデルアーキテクチャではなくデータ構成を変えるというシンプルかつ本質的なアプローチです。
課題として残るのは、NAPで使用する複数軌跡の生成コストと、マクロ-マイクロ分割の設計に関する汎化性です。実験はGSM8KとMATH-500に限定されており、他のドメインへの適用可能性は今後の検証が必要です。とはいえ、LLaDAをはじめとするDLMの実用化に向けた基盤的な知見を提供した点において、この研究はDLM研究に重要な方向性を示しています。コードはGitHubで公開されており、再現研究への参入障壁が低いことも評価できます。






