
- 知覚と推論を分離するフレームワークにより、全文入力の2%のコンテキストで絶対精度12.5ポイント向上を達成
- 3層階層グラフメモリとORAループ(観察・推論・行動)によるエージェント型検索で、長時間動画のトークン爆発問題を根本解決
- 4つの主流ベンチマークでSOTA更新、人間専門家との精度差を3.7ポイントまで縮小し、LLMの推論能力との正の線形相関も実証
研究の背景と課題
近年のビジョン言語モデル(Vision Language Model、VLM)は短い動画の理解では高い性能を示す一方、数時間に及ぶ長時間動画の処理では根本的なボトルネックが存在します。最大の問題は「トークン爆発」です。長い動画をフレームごとにトークンへ変換すると入力の長さが膨大になり、モデルが重要な情報に集中できなくなる「注意散漫」も同時に引き起こされます。
従来のアプローチでは、フレームを均等にサンプリングして入力数を減らす方法や、動画全体を圧縮して要約する方法が取られてきました。しかしいずれも、関連するシーンが特定の時間帯に集中している場合に必要な情報を取り逃がすという弱点を抱えています。MemDreamerはこの課題を、「動画を見る(知覚)フェーズ」と「質問に答える(推論)フェーズ」を完全に分離する設計で解決します。
MemDreamerの全体像
MemDreamerは大きく2つのステップで動作します。まず知覚フェーズで、動画をストリーミング処理しながら階層グラフメモリを構築します。次に推論フェーズで、エージェント型検索機構がそのメモリから必要な情報を効率よく引き出し、LLMが最終的な回答を生成します。
この2段階の分離により、推論時にLLMが処理するコンテキストは動画全体の2%程度に抑えられます。それでも精度が上がる理由は、後述するメモリ構造と検索機構の設計にあります。
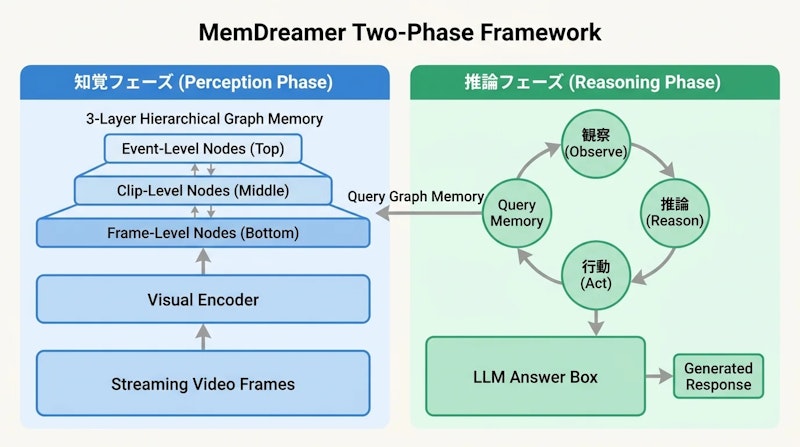
3層階層グラフメモリ
動画の内容を整理するグラフメモリは、抽象度の異なる3つの層で構成されます。最も細かいフレーム層では個々のフレームの視覚情報を保持し、その上のクリップ層では連続するフレームをまとめたシーン単位の情報を管理します。さらに上位のイベント層では、複数のシーンにまたがる出来事や因果関係を抽象的に表現します。
この3層構造によって、MemDreamerは「その瞬間に何が映っていたか」という細かい情報から「全体としてどのような出来事が起きたか」という大局的な理解まで、一つのグラフ上で保持できます。ノード間のエッジ(辺)は時間的・意味的な関係を表し、検索時の手がかりとして機能します。
エージェント型検索機構
推論フェーズでは、Observation-Reason-Action(ORA)ループと呼ばれる反復的な検索プロセスが動きます。まず「観察(Observation)」として質問に関連しそうなグラフのノードを参照し、次に「推論(Reason)」としてその情報が十分かどうかを判断します。不十分であれば「行動(Action)」として次に参照すべきノードを選び、ループを繰り返します。
このORAループは、人間が動画を振り返るときの思考プロセスに近い形で動作します。「あのシーンにヒントがあるかもしれない」と仮説を立て、確認し、さらに別の箇所を参照するという探索的な推論によって、全体の2%に当たる少量の情報だけで正確な回答が可能になります。視覚潜在空間を活用したFuture-L1のように、VLMが内部で情報を組み合わせながら推論するアプローチと共通する考え方です。
実験結果と性能評価
MemDreamerは4つの主流長時間動画理解ベンチマークで評価され、いずれもSOTA(最高性能)を更新しました。注目すべきは全文入力との比較です。フルコンテキストを使う従来の最強手法に対して、わずか2%のコンテキストしか使わないMemDreamerが12.5ポイント高い絶対精度を達成しています。
また、人間の専門家が同じベンチマークに回答した場合との差は3.7ポイントにまで縮小しました。コンテキスト効率と精度という、従来はトレードオフの関係にあった2つの指標を同時に改善した点が、このフレームワークの技術的な強みを端的に示しています。
LLM推論能力との相関
本研究で特に興味深い知見として、VLMの論理推論能力と長時間動画理解の性能の間に強い正の線形相関があることが実験的に示されました。つまり、動画専用の訓練を増やすよりも、モデルの汎用的な推論能力を高めることが動画理解性能の向上に直結するということです。
この知見はマルチモーダルモデルの開発戦略にも大きな示唆を持ちます。動画理解の向上をめざす際に、動画データの拡充だけでなく、テキストベースの推論訓練を強化することが効果的である可能性を示しているからです。モデルのスケーリングをどの方向に進めるべきかという議論にも、新たな視点を提供します。
まとめと今後の展望
MemDreamerは、長時間動画理解における「情報をすべて読み込む」という従来の発想を転換し、「必要な情報だけを賢く探す」アーキテクチャを実現しました。3層の階層グラフメモリによる構造化された記憶と、ORAループによるエージェント型検索の組み合わせが、コンテキスト効率と精度の両立という難題を解決しています。
今後の課題としては、グラフメモリの構築に要する計算コストの削減や、数十時間規模のさらに長い動画への適用が挙げられます。一方で、知覚と推論を分離するこのフレームワークは動画理解にとどまらず、長文書や複雑なマルチモーダル入力の処理にも応用できる可能性を持っており、今後の展開が注目されます。







