
- agent-evalはAIエージェントのライブラリ操作能力を正答率・トークン消費・エラー回数・実行時間の4指標で多角的に評価するベンチマークフレームワーク
- CLIドキュメント補助は大規模モデルの実行時間を短縮するが、Qwen3-14BなどではMatch率が100%から0%に急落する逆効果が実証された
- コードはGitHub(huggingface/is-it-agentic-enough)で公開。TransformersをはじめPythonライブラリ全般を対象に評価を誰でも実施できる
エージェントの「現場能力」を測る
AIエージェントが実際の開発業務で役立つかどうかは、最終的な答えが正しいかどうかだけでは測れません。HuggingFaceは2026年6月18日、この問いに正面から向き合うベンチマークフレームワーク「agent-eval」を公開しました。
agent-evalは、AIエージェントがソフトウェアライブラリをどれだけ正確かつ効率的に扱えるかを検証するツールです。開発者が自分のライブラリを評価対象として持ち込める設計になっており、特定のモデルや実行環境に依存しない汎用的な測定基盤として機能します。フレームワーク自体は任意のPythonライブラリに適用可能で、HuggingFaceのTransformersライブラリが初期の実験対象として使われています。
3段階のテスト設計
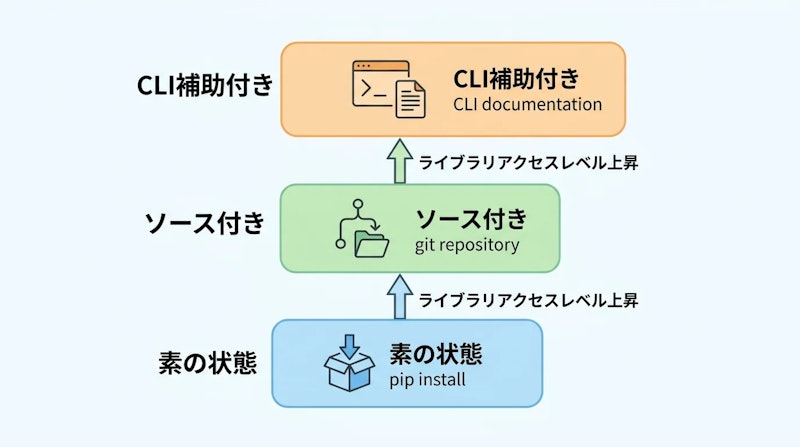
agent-evalは、エージェントがライブラリに接触する状況を3段階に分けて評価します。
- Bare(素の状態): pipインストール情報のみを提供
- Clone(ソース付き): フルのソースリポジトリをクローンした状態で提供
- Skill(CLI補助付き): CLIドキュメントと使用例をパッケージ化して提供
この段階的な設計により、「ドキュメントの充実度がエージェントの性能にどう影響するか」を定量的に分析できます。提供情報が増えるほど性能が上がるという単純な話でなく、モデルの規模によって最適な補助レベルが異なるという複雑な関係が明らかになっています。
結果より「過程」を数値化する4指標
従来のベンチマークが正答率(Match %)のみに注目しがちだったのに対し、agent-evalは実行の「過程」を重視した複数の指標を組み合わせます。
- Match %: 最終出力が期待する結果を含んでいるか
- 中央値時間・トークン数: 消費した計算リソース(新規・キャッシュ・生成トークンを区別して計測)
- エラー率: 出力が空になるサイレントエラーを含む失敗の頻度
- マーカー採用率: エージェントがツールとどう相互作用したかを示す独自指標
これらを組み合わせることで、「正解を出してはいるが極端にトークンを消費している」「エラーから回復できているが実行時間が長すぎる」といった、正答率だけでは見えない性能の差を捉えられます。ライブラリ設計者はこの多面的な評価を通じて、エージェントにとって「使いやすい」APIやドキュメントの形を具体的に把握できます。
CLIドキュメント補助の実証知見
実験で特に注目すべき発見が、CLIドキュメント補助(Skillティア)のモデル規模による効果の逆転です。
大規模モデルではCLIドキュメントを提供することで実行時間が短縮されました。Pythonコードを試行錯誤でデバッグする代わりに、ドキュメント化されたインターフェースを活用して効率的に問題を解けるためです。初期段階で入力トークン数が増えるものの、全体的な効率は向上しています。
一方、Qwen3-14BなどのサイズのモデルではCLIドキュメントが逆効果となりました。ドキュメントを実行可能なツールと誤解し、一部タスクでMatch率が100%から0%に急落するケースも確認されています。近年は7B規模のモデルでもアーキテクチャ設計の工夫でSWE-benchの高スコアを達成する手法が登場していますが、agent-evalの実験はモデルの規模だけでなく「提供するドキュメントの質と形式」が性能を大きく左右することを示しています。
自分のライブラリで試すには
agent-evalはGitHubリポジトリ(huggingface/is-it-agentic-enough)で公開されており、誰でも自分のライブラリを対象に評価を実施できます。CLIコマンド agent-eval を実行すると、モデル・リビジョン・タスクの組み合わせを横断的にテストし、HuggingFace Jobsに分散実行します。結果はSpacesにインタラクティブなレポートとして公開され、エージェントの実行トレースはBucketsに保存されてHub上のビューアから閲覧できます。
このフレームワークの根底には「テストされていなければ動かない、ドキュメントがなければ存在しない」という設計哲学があります。エージェント時代においては、ドキュメントの発見しやすさや明確さがUXの問題だけでなく、計算コストに直結する技術的課題となります。ライブラリ設計者にとって、自分のAPIがエージェントにどう「見える」かを定量的に確認できるツールとして、agent-evalは実用性の高い選択肢といえます。








