
- CoTによる教師あり微調整がハイブリッドLLMのNIAH長文書検索性能を最大67.2%から9.4%まで激減させると実証
- 原因はクエリ・キー射影行列が短距離バイアスを獲得する現象で、勾配が距離とともに指数減衰することを数学的に証明
- QK-RestoreはW_QとW_Kのみをファインチューニング前の重みに戻し、追加学習なしでNIAH性能を最大76.4%に回復
研究の背景
Transformerの計算コストを削減するため、近年はMambaのような線形注意機構(State Space Model)とSoftmax注意を組み合わせた「ハイブリッドLLM」が注目されています。HypeNetやJet-Nemotronがその代表例で、長文書処理の計算量を線形に抑えながら、限定的に残したSoftmax注意層で長距離の情報検索を担う設計です。
こうしたハイブリッドモデルは、事前学習後に推論能力を高めるためChain-of-Thought(CoT)の教師あり微調整(Supervised Fine-Tuning、以下CoT-SFT)を行うのが一般的です。ところが今回の研究では、このCoT-SFTが長距離の記憶・検索能力を深刻に損なうという副作用が明らかになりました。研究チームはこの現象を「Attention Amnesia(注意健忘)」と名付けています。
Attention Amnesiaの発見
研究チームはNIAH(Needle-In-A-Haystack)と呼ばれるベンチマークで問題を検証しました。NIAHは大量のテキスト(干し草の山)の中に特定の情報(針)を埋め込み、モデルがそれを正しく取り出せるかを評価するタスクです。コンテキスト長が長くなるほど、また埋め込む針の数が増えるほど難易度が上がります。
実験の結果、HypeNet-9BモデルではCoT-SFT後にNIAH-S2@256K(256,000トークンのコンテキスト内に2箇所の針を埋め込む設定)の性能が67.2%から9.4%まで急落しました。推論能力(MATH500やGSM8Kのスコア)は向上しているにもかかわらず、長文書の中から情報を探し出す能力が壊滅的に低下したのです。「推論は上手くなったが、本文を読む力を失った」状態です。
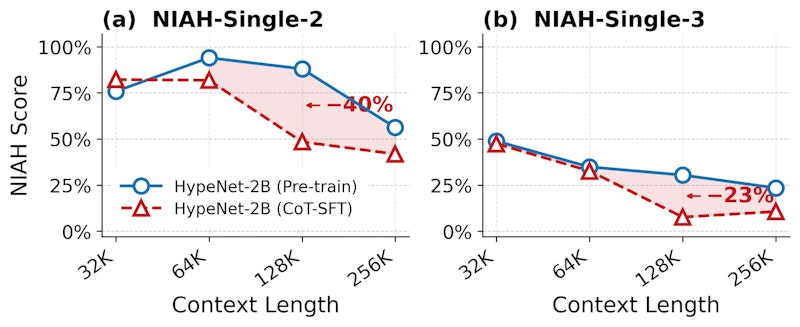
この問題はハイブリッドモデルに特有の現象です。純粋なTransformerモデル(Qwen2.5-3B等)では同様のCoT-SFTを行ってもNIAH性能の急激な劣化は観察されませんでした。なぜハイブリッドモデルだけが影響を受けるのか、その謎に理論的な解答が与えられています。
劣化のメカニズム
研究チームは定理4.6(勾配局所性定理)として、Attention層のクエリ行列(W_Q)とキー行列(W_K)への更新勾配が、トークン間距離τに対してρ^τという指数関数で減衰することを数学的に証明しました。ここでρはCoT推論データのMarkov連鎖から決まるスペクトラルギャップに由来する定数です。
CoTによる推論データは、思考の流れが局所的な連鎖構造(Markov性)を持っています。つまり次のステップは直前の数ステップにのみ強く依存し、遠くの文脈への依存は薄い。この性質が学習時の勾配を短距離方向へ偏らせます。結果として、W_QとW_Kは遠くのトークンへの注意を犠牲にし、近くのトークンのみを参照するよう変化していきます。
ハイブリッドモデルでは線形注意層が長距離記憶の大部分を担っているため、Softmax注意層に残された「長距離情報のルーティング」という役割が失われると、全体の長文脈能力が崩壊します。純粋なTransformerではすべての層がSoftmax注意を持つため、一部の層が短距離バイアスを持っても他の層が補完できますが、ハイブリッドモデルでは補完の余地が少ないのです。

さらに定理5.1(ルーティング・抽出勾配分離定理)では、W_QとW_Kへの勾配は距離とともに指数減衰するのに対し、W_V(値行列)とW_O(出力行列)への勾配は位置に関わらず一様に下限を持つことも証明されています。この非対称性こそが、次章で紹介するQK-Restoreを理論的に正当化します。
QK-Restore:学習不要の修復手法
「W_QとW_Kの劣化がボトルネックなら、この2つだけをSFT前の状態に戻せばよい」という発想がQK-Restoreの骨子です。手順はシンプルで、CoT-SFT完了後のモデルに対し、各Attention層のW_QとW_Kだけをファインチューニング前のチェックポイントから上書き復元します。
W_VやW_Oなど値の抽出に関わるパラメータはSFT後の状態をそのまま維持します。「どこに注意するか(長距離ルーティング)」をSFT前の重みで担保しつつ、「その情報から何を取り出すか(推論適応)」はSFT後の重みで担う分担です。これにより、長文書の検索能力と推論能力の両立を目指します。
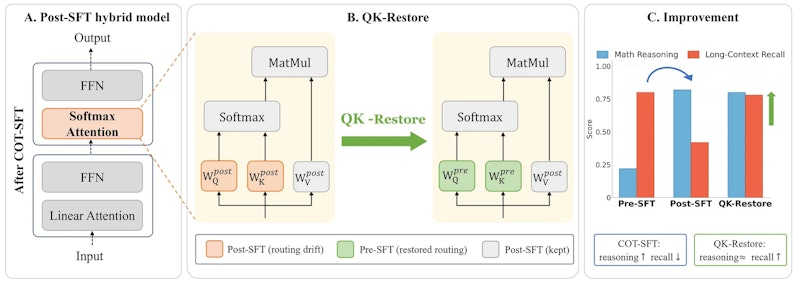
発展版のQK-ProはProcrustes問題(2つの行列の差を最小化する直交変換を求める問題)として定式化し、元の長距離ルーティング特性を保ちながら推論への適応も反映させるバランス調整を行います。長距離記憶と推論能力のトレードオフをより精密に制御したい場合に有効です。Optical Reasoningとは?推論を「画像」に変換してトークン29%削減を実現する新手法のように、LLMの推論効率化には多様なアプローチが存在しますが、QK-Restoreはファインチューニング後の能力劣化を防ぐという点で独自の位置づけです。
実験結果
HypeNet-5BへのQK-Restore適用では、NIAH-S3@256KでSFT後の65.4%から76.4%へ11ポイントの改善を達成しました。HypeNet-9B(NIAH-S2@256K)ではSFT後9.4%から42.6%への大幅な回復が確認されています。Jet-Nemotron-2Bでも同様に10.6%から30.2%へ向上し、手法の汎用性が示されました。
推論性能については、MATH500やGSM8KのスコアがQK-Restore適用前後でほぼ変化しない(±1ポイント以内)ことが確認されています。CoT-SFTで獲得した推論能力を保ちながら、長距離記憶も回復できるという結果です。追加の学習を一切必要としない点も実用上の大きな利点で、SFT済みのモデルに対してW_QとW_Kを上書きコピーするだけで適用できます。
ただし、すべてのモデルと設定で完全な回復が得られるわけではありません。Qwen2.5-3Bのような純粋なTransformerでは勾配の減衰パターンが異なり、Attention Amnesiaの影響も異なることが確認されています。QK-RestoreはハイブリッドアーキテクチャのSoftmax注意層を持つモデルに特に有効な手法です。
まとめ
本研究は、ハイブリッドLLMの実用化において見落とされがちだった「CoT-SFTが長距離記憶を損なう」という副作用を初めて系統的に報告し、そのメカニズムを理論的に解明した点に意義があります。グラジェント(勾配)の局所性という理論的根拠にもとづいてW_QとW_Kに原因を特定し、学習不要の修復手法まで示した一貫した研究です。
ハイブリッドアーキテクチャのモデルをファインチューニングする実務者にとって、Attention Amnesiaのリスクを認識しておくことは重要です。QK-Restoreはそのリスクへの対処として即効性が高く、今後のファインチューニングパイプラインへの組み込みが期待されます。課題としては、完全回復に至らないケースへの対応や、より多様なハイブリッドアーキテクチャへの検証が引き続き必要です。







