
- 世界シミュレーターを「想像の道具」として呼び出すエージェント型VLMフレームワーク「Astra」が、未見視点の空間推論を克服する新手法として提案された
- 2段階の強化学習カリキュラムにより選択的なシミュレーター呼び出しを習得し、MMSI-Benchで+9.0点という大幅な精度向上を実現
- 世界シミュレーターの視点一貫性チューニングでポーズ整合性スコアを9.0から72.5に大幅改善し、MindCubeでも+5.9点を達成
研究の背景
視覚言語モデル(VLM)は画像とテキストを組み合わせた推論を得意とする一方で、「観察していない視点からシーンがどのように見えるか」を問う空間推論は長らく課題として残っています。部屋の写真1枚から「右側の壁の配置は?」や「真上から見るとどう見える?」といった問いに正確に答えるには、入力画像の範囲を超えた三次元的な理解が求められます。
既存のVLMは観察された視点に強く依存しており、複数視点間の一貫性を保ちながら空間構造を推論する能力が不足しています。人間であれば「そちら側はこうなっているはず」と頭の中で想像して補完できるところを、モデルは入力画像の範囲外の推測が難しいのです。

Astraの仕組み
2026年6月に発表された「Astra」は、VLMがリアルタイムに世界シミュレーターを呼び出して「想像された観察」を取得する、エージェント型の空間推論フレームワークです。システムはAstra-VL(推論ポリシー)とAstra-WM(世界シミュレーター)の2コンポーネントで構成されます。
Astra-VLはQwen3-VLをベースとし、与えられた質問に答えるために「シミュレーターを呼び出すかどうか」「どのカメラ動作を指示するか」「生成された画像をどう推論に組み込むか」を自律的に決定します。一方、Astra-WMはテキストで指定されたカメラ動作(例:「右へ0.5メートル移動して正面を向く」)を受け取り、現在の観察から新しい視点の画像を生成します。
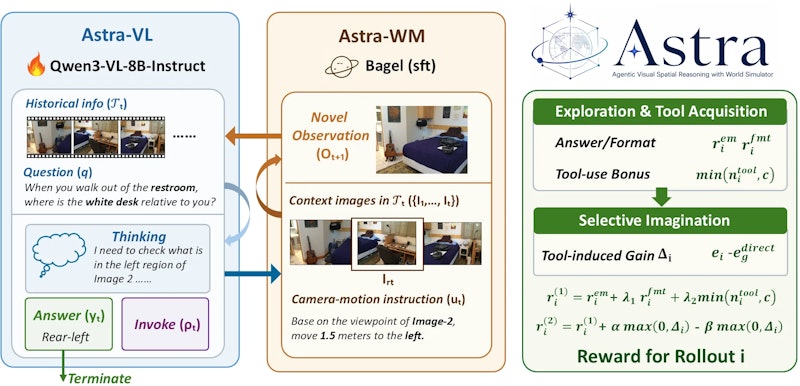
Astra-WMの視点一貫性
世界シミュレーターのベースモデル(Bagel)をそのまま利用すると、視覚的にはそれらしい画像が生成されても空間的な整合性が欠けることがあります。Astraではこの問題に対処するため、「視点一貫性チューニング(View Consistency Tuning)」と呼ばれる専用の追加学習を実施しています。
訓練データには屋内の多視点シーンデータセット(ScanNet、Matterport3D、ARKitScenes等)から品質検証済みの544,197サンプルが使われました。カメラペアの選定にはカバレッジ比率0.85以上の制約と視点多様性の条件が課せられており、空間的に信頼性の高い画像生成を実現しています。この改善により、ポーズ整合性スコアがBagelの9.0からAstra-WMの72.5まで大幅に向上しました。
2段階の強化学習
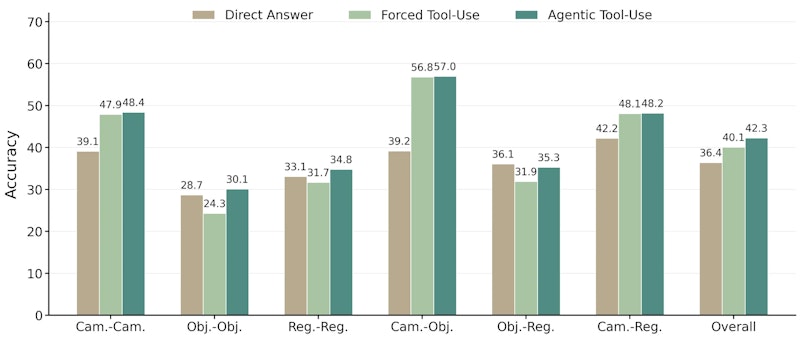
Astra-VLがシミュレーターを「いつ使うか」を学習するには、単純な報酬設計では機能しないことが実験から明らかになっています。ツール使用ボーナスだけでは98.1%という過剰な呼び出し率になり、逆に正解報酬だけでは4.9%まで使用率が崩壊してしまいます。
そこでAstraでは2段階のカリキュラムを採用しています。フェーズ1では正解報酬に加えてシミュレーター使用ボーナスを上限付きで与え、まず有効なシミュレーター操作そのものを習得させます。フェーズ2では「シミュレーターを使ったほうが正解に近づくケース」を比較学習で強化し、有害な呼び出しにはペナルティを与えます。この設計により61.5%という適切な呼び出し率での選択的な想像が実現しました。
実験結果
多様な空間推論タスクのベンチマークMMSI-Benchでは、Qwen3-VL-8Bのベースライン29.8%に対して、Astra-VLの適用後に38.8%(+9.0ポイント)を達成しました。3Dシーン内の空間関係を問うMindCubeでも36.8%から42.7%(+5.9ポイント)に向上しています。
また、Gemini-3-Flashに世界シミュレーターを組み合わせる実験では、Astra-WMを使った場合に45.1%から49.5%へと改善した一方、視点一貫性チューニングなしのBagelでは45.8%にとどまりました。世界シミュレーターの生成品質が空間推論精度に直結することが確認されています。視覚潜在空間を使って「想像してから予測する」手法のFuture-L1など、VLMに想像力を付与するアプローチは各所で成果を上げており、Astraはその中でも実際の3D世界モデルとの統合を深めた手法です。
まとめと今後の展望
Astraは、VLMに「想像して推論する」能力を与えるフレームワークとして、空間推論分野での有力な方向性を示しています。単に生成モデルへのアクセスを与えるだけでは不十分で、「いつ・どこで・どのように想像するか」を学習させる訓練設計が成否を左右することが実証されました。
今後はロボティクスや3Dシーン理解、室内ナビゲーションなど、三次元空間の把握が求められる応用領域での活用が期待されます。一方で、現時点では屋内シーン中心の訓練データに依存しており、屋外環境や複雑な動的シーンへの汎化は今後の課題として残っています。






