
- DeepSeekで知られるMLA(Multi-Head Latent Attention)をビデオ拡散モデルに世界初適用し、KVキャッシュメモリを92.7%削減することに成功
- 分単位の長尺動画生成を実現しVBenchの長尺評価で最高スコアを達成。NVIDIA B200でのスループットも1.23倍に向上し、バッチサイズ上限は8.0倍に拡大
- 「ビデオ拡散の注意行列は低ランクではない」という新理論的知見を提示。MLAの成功はスペクトル構造よりもアーキテクチャのボトルネックによる学習適応が鍵と判明
研究の背景と課題
動画生成AIは近年急速に進歩しましたが、長尺動画の生成にはメモリ面での大きな壁があります。自己回帰型のビデオ拡散モデルでは、生成した各フレームの情報を「KVキャッシュ」として保持し続ける必要があり、動画が長くなるほどキャッシュが膨れ上がります。GPUのメモリ不足(OOM: Out of Memory)によって処理が停止するため、高品質な長尺動画生成は実用上ほぼ不可能で、数秒程度が現実的な上限とされてきました。
動画VLMでのトークン早期圧縮のように動画AI全体での効率化研究は活発に進んでいますが、ビデオ生成モデル側のKVキャッシュ削減は未開拓の領域でした。VideoMLAは、大規模言語モデルで実績のあるMLA技術をビデオ拡散モデルに初めて持ち込み、この問題を正面から解決しようとした研究です。
MLAとは?LLMからビデオ拡散へ
MLA(Multi-Head Latent Attention)は、DeepSeek V2やDeepSeek V3などの大規模言語モデルで採用されたアテンション機構です。従来のMHA(Multi-Head Attention)がヘッドごとに個別のキーとバリューを保持するのに対し、MLAはすべてのヘッドで共有する低次元の「潜在ベクトル」にまとめて圧縮します。LLMで証明されたこの仕組みを、VideoMLAはビデオ拡散モデルに転用しています。
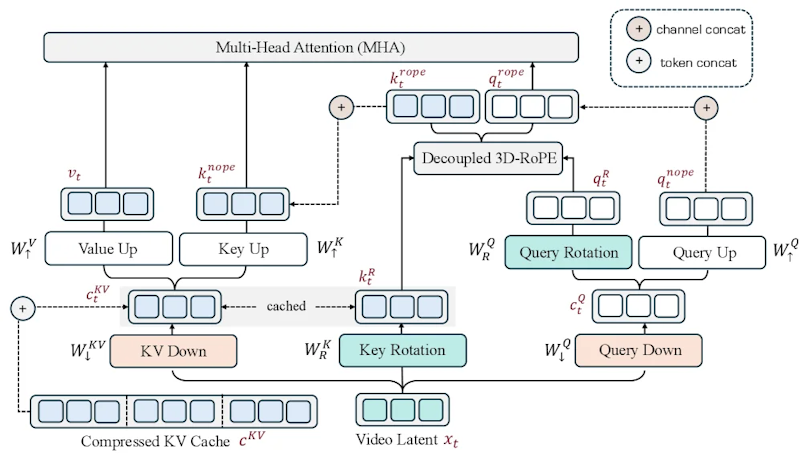
VideoMLAは、Wan2.1-1.3Bをベースとするビデオ拡散モデルに組み込まれています。各入力トークンに対して「コンテンツ潜在ベクトル」と「位置キー」を分離して扱います。コンテンツ情報は192次元の共有潜在ベクトルに圧縮され、位置情報は3D-RoPE(3次元の回転位置エンコーディング)で別途保持されます。この設計により、1トークンあたりの保存データ量を3,072スカラーから224スカラーへと約93%削減しながら、空間・時間的な位置情報を正確に維持できます。
低ランク仮説を実験で覆す
MLAがなぜ言語モデルで機能するかについて、従来は「アテンション行列が低ランクの構造を持つから」という仮説が広く受け入れられていました。事前学習済みモデルの重み行列が実質的に低いランクに収まっているため、圧縮しても情報の損失が少ない、という考え方です。VideoMLAはこの仮説がビデオ拡散では成り立たないことを実験で明確に示しています。
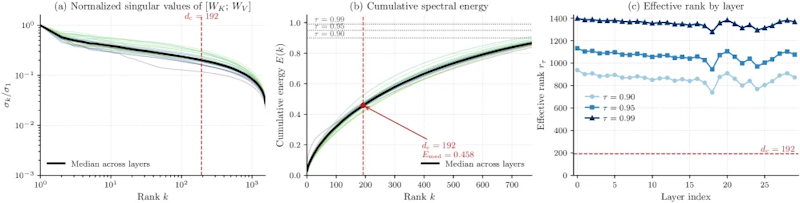
Wan2.1-1.3Bの全30層を特異値分解で解析すると、99%のスペクトルエネルギーを保持するために必要な有効ランクはすべての層で1,300を超えます。これは圧縮後の192次元を大きく上回る値です。にもかかわらず、VideoMLAは高い生成品質を維持します。
この矛盾を解くために論文は、「アーキテクチャのボトルネック構造自体が、学習を通じてランク効率を生み出す」という新たな説明を提唱しています。SVD初期化でも無作為初期化でも、学習中に潜在ベクトルが利用可能なランク次元をほぼ完全に活用することが確認されました。元の重み行列の低ランク構造に依存するのではなく、学習による適応が圧縮の成功を支えているという、従来仮説とは異なる理論的知見です。この発見は、LLM技術をビデオ生成に転用する際の設計指針として重要な意味を持ちます。
実験結果:分単位の長尺動画で最高品質
VideoMLAはVBenchベンチマークで評価され、30秒および60秒の長尺動画生成においてOverall Scoreは0.859を達成しました。これは評価した手法の中で長尺動画の総合スコアが最高です。動きの多様性を示すDynamic Degreeも30秒で0.981、60秒で0.958と高い値を維持しています。
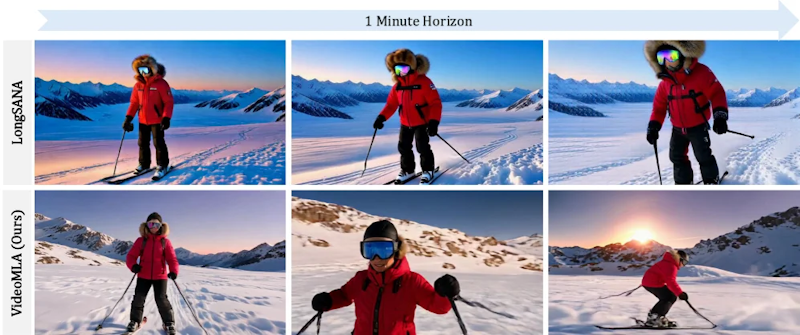
比較対象のLongSANAはソフトマックスを線形アテンションに置き換えることでメモリ問題に対処しますが、長時間になるほど映像が静止画に近づき品質が劣化する傾向があります。VideoMLAは1分間のロールアウト全体を通じて、視覚的な鮮明さと動きの多様性を保ちます。
NVIDIA B200でのスループットはベースラインに対して1.23倍に向上し、固定メモリ予算のもとでのバッチサイズ上限は8.0倍に拡大しました。KVキャッシュはSelf-Forcingベースラインに対して92.7%削減されており、同一フレームウィンドウでの比較ではLongSANAのSCDキャッシュより11.4倍小さいサイズを実現しています。
まとめと今後の展望
VideoMLAはLLM向けに開発されたMLA技術をビデオ拡散モデルに初めて適用した研究です。KVキャッシュを92.7%削減しながら分単位の長尺動画生成を実現し、VBenchの長尺評価で最高スコアを達成しています。
理論的な貢献も見逃せません。低ランク仮説がビデオ拡散では成立しないという実験的反証と、アーキテクチャのボトルネック構造が学習適応を通じてランク効率を生むという代替説明は、LLM技術をビデオ生成へ転用する際の重要な設計指針となります。現時点ではWan2.1-1.3Bでの検証にとどまっており、より大きなモデル・高解像度・さらなる長尺化への拡張は今後の課題として残されています。







