
- ステートフルなPythonカーネルを行動インターフェースに採用し、知覚・幾何プリミティブを事前ロードした反復実行ループで空間推論を実現
- 20の空間推論ベンチマークで平均59.9%を達成し、既存エージェントを平均+11.2ポイント上回る性能を記録
- 追加学習不要で6種のVLMバックボーンに汎用適用でき、複数の幾何学的演算を組み合わせる多段階推論タスクで特に大きな性能改善を実現
研究の背景と課題
物体がどこにあるか、物体同士がどう位置関係にあるか、3D空間でどう動くかを把握する能力を「空間推論」と呼びます。ロボットの操作、自律走行車のシーン理解、AR/VRのインタラクションなど、実世界の応用において欠かせない能力です。
近年、画像とテキストを同時に扱えるVision Language Model(VLM: 画像と言語を統合した大規模モデル)は目覚ましい発展を遂げています。しかし、語義的な理解や物体認識では高い性能を示す一方、「この2つの物体の距離は何メートルか」「カメラはどの方向を向いているか」といった定量的な空間推論には大きな課題が残っています。
こうした課題に対するエージェントの行動インターフェースには主に2種類ありました。一つは完全なプログラムを事前に生成してから一度だけ実行する「単一パスコード」、もう一つはJSON/XMLなど構造化されたコマンドでツールを呼び出す「構造化ツール呼び出し」です。前者は中間結果を見ながら修正できず、後者は操作の組み合わせ方が固定されるため、複雑な多段階の幾何学的推論には対応しにくいという問題がありました。
SpatialClawの提案手法
NVIDIAの研究チームが提案するSpatialClawは、ステートフル(状態を保持できる)なPythonカーネルを行動インターフェースとして採用することで、この問題に正面から取り組みます。「カーネル」とは実行環境のことで、入力画像・距離推定・物体検出・幾何学計算といった知覚・幾何プリミティブ(基本演算)があらかじめ読み込まれた状態で用意されています。

最大の特徴は、コードを書いて実行し、結果を確認してから次のコードを書くという反復実行ループです。単一パスが「答えを出す前にすべての計算を決める」のに対し、SpatialClawは「途中結果を見ながら次の手を考える」ことができます。これは人間が試行錯誤しながら計算を進めるスタイルに近い設計です。また、前のセルで生成した変数や中間結果が次のセルでもそのまま使えるステートフルな設計により、条件分岐やループを使った柔軟な制御フローも実現できます。
エージェントループの仕組み
SpatialClawは5段階のループでアクションを実行します。まず「プランナー」が質問とツールのドキュメントを受け取り、分析計画を立てます(このとき画像は参照しません)。次に「メインエージェント」がPythonコードセルを生成してカーネルで実行します。
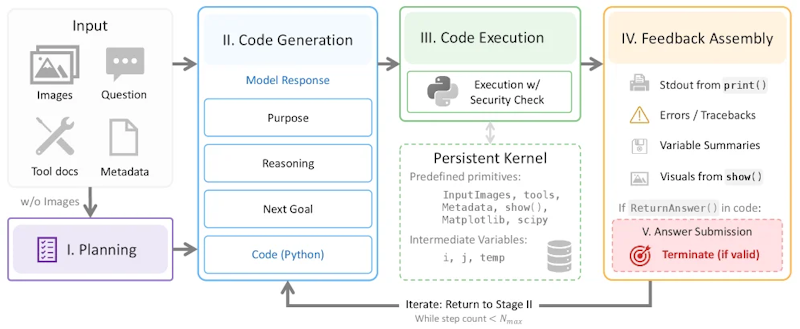
実行後のフィードバック(標準出力、変数の内容、show()で登録した中間画像)はモデルのコンテキストに追加され、エージェントはそれを確認して次のコードセルを生成します。このループはReturnAnswer()が呼ばれるか、あらかじめ設定した最大ステップ数に達するまで繰り返されます。
この設計により、最初の深度推定が期待通りでなければ別の手法に切り替える、中間の物体検出結果を確認してからバウンディングボックスの座標を計算する、といった適応的な問題解決が可能になります。VLMの推論能力を引き出すインターフェース設計は近年注目の研究テーマで、推論根拠を画像として扱うOptical Reasoningなど異なるアプローチも登場しており、行動インターフェースの選択が性能を左右するという認識が広まっています。
実験結果
SpatialClawは、物体間の距離・方向・大きさ・カメラ姿勢推定など多様なタスクを含む20個の空間推論ベンチマークで評価されました。平均精度は59.9%で、従来の空間推論エージェントを平均+11.2ポイント上回りました。6種類の異なるVLMバックボーンにおいても追加学習なしで一貫した改善が確認されています。
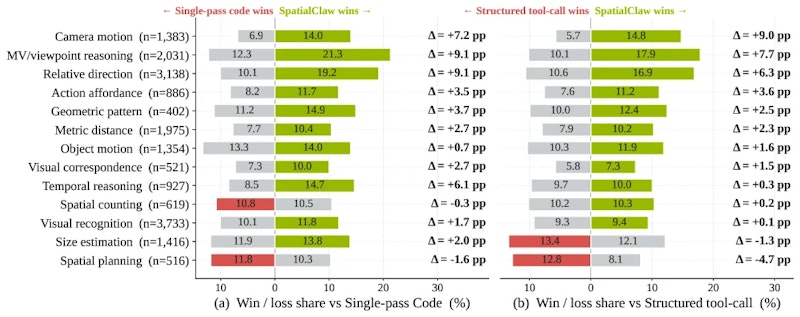
特に改善が顕著だったのは、距離推定・カメラ方向推定・物体の相対位置判断など、複数の幾何学的演算を組み合わせる必要があるカテゴリです。一方、「物体は左にあるか右にあるか」のような言語的な空間表現については、行動インターフェースの違いによる差は小さい傾向でした。
性能向上の要因分析では、改善の半数以上を「コードの柔軟な組み合わせ(コード合成)」が占め、「制御フローの活用」が19.5%、インターフェースに依存しない知覚タスクでの改善が28.3%という内訳でした。なお、失敗ケースの分析では深度推定の精度不足や誤った前提に基づく連鎖誤りが主な課題として挙げられており、改善余地も示されています。
まとめ
SpatialClawは、ステートフルなPythonカーネルという行動インターフェースの選択が空間推論の精度に大きく影響することを示した研究です。中間結果を確認しながら推論を修正できる設計は、単一パスや構造化ツールでは難しかった多段階の幾何学的問題解決を可能にします。
20ベンチマークにわたる+11.2ポイントの改善と6種のVLMへの追加学習不要な適用は、手法の再現性と汎用性の高さを示しています。ロボットの物体操作、自律走行車のシーン理解、3Dシミュレーション環境での評価など、幅広い実世界応用への展開が期待される成果です。







