
- 推論モデルは回答前に思考プロセスを展開し、複雑な問題を段階的に解決するAI
- テストタイムコンピュートにより、難易度に応じて計算資源を動的に配分できる
- DeepSeek-R1はGRPOによる強化学習のみで推論能力を獲得した革新的モデル
推論モデルとは何か
推論モデル(Reasoning Model)とは、回答を生成する前に内部で思考の連鎖を展開し、複雑な問題をステップごとに分解・検証するAIモデルのことです。従来の生成AIが質問を受け取ると即座に応答するのに対し、推論モデルは「考えるプロセス」そのものをモデル化しています。
この思考プロセスは「推論トークン」として展開され、複数のアプローチを検討してから最終出力を生成する点が特徴です。2026年3月現在、OpenAI o3、Anthropic Claude(Extended Thinking)、Google Gemini 2.5 Pro、DeepSeek-R1など、主要なAI企業が推論モデルを相次いで投入しています。
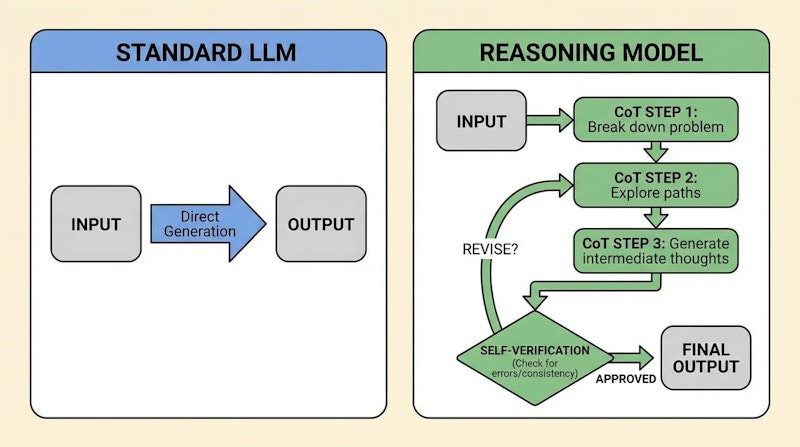
従来のLLMとの違い
従来のLLM(大規模言語モデル)は、入力されたプロンプトに対して統計的なパターンマッチングで即座に応答を生成します。一方、推論モデルは以下の点で大きく異なるでしょう。
思考プロセスの可視化:推論モデルは内部で思考ステップを展開し、そのプロセスを推論トークンとして記録します。開発者はこの思考プロセスを確認できるため、AIがどのような論理で結論に至ったかを追跡可能です。
自己検証メカニズム:推論モデルは複数の解法を検討し、自己検証を行ってから最終回答を出力します。これにより、複雑な数学問題やコードレビューなどで高い精度を実現しています。
計算資源の動的配分:問題の難易度に応じて、より多くの推論トークンを割り当てることで精度を向上させることができます。これは「テストタイムコンピュート」と呼ばれる重要な概念です。
主要な推論モデルの特徴
OpenAI o シリーズ
OpenAI o3は現時点で最高性能を誇る推論モデルです。o3-miniは約10分の1のコストで高速動作する軽量版として提供されています。両者とも数学、コーディング、科学分野で従来モデルを大きく上回る精度を達成しました。
Anthropic Claude(Extended Thinking)
Claudeの拡張思考機能は、low/medium/high/maxの4段階で推論レベルを調整できる柔軟性が特徴です。100万トークンのコンテキストウィンドウを備え、長文書の精緻な分析に強みを持ちます。
Google Gemini 2.5 Pro
Gemini 2.5 ProのFlashバージョンは、思考モードのON/OFFを切り替え可能な「完全ハイブリッド推論」を実現しています。シンプルなタスクでは高速応答、複雑なタスクでは深い推論と使い分けができる点が利点でしょう。
DeepSeek-R1
DeepSeek-R1はMITライセンスで公開されたオープンソースの推論モデルです。MoE(Mixture of Experts)アーキテクチャにより、671Bパラメータを約37Bの計算コストで運用する効率性を実現しました。後述するGRPOという独自の強化学習手法で訓練されている点が技術的に注目されています。
技術的な仕組み
テストタイムコンピュート
推論モデルの核心技術が「テストタイムコンピュート(Test-Time Compute)」です。これは推論時に計算資源を投入することで精度を向上させるアプローチで、従来のモデルサイズによるスケーリングとは異なる軸での性能向上を可能にしています。
重要な特性として、思考トークン数と精度が対数的な関係を示す点が挙げられます。つまり、難しい問題には多くの推論トークンを割り当て、簡単な問題には少なく抑えることで、コストと精度のバランスを動的に調整できるわけです。
Chain of Thought(思考の連鎖)
推論モデルはChain of Thought(CoT)という技術を基盤としています。CoTは問題を小さなステップに分解し、順次解決していく手法で、人間が複雑な問題を解く際の思考プロセスに近い方法論です。
さらに高度な手法として、Tree of Thought(ToT)があります。ToTは複数の解法を木構造で展開・評価し、最適な経路を選択する技術で、より複雑な問題に対応できます。
強化学習による推論能力の獲得
推論モデルの訓練には、RLHF(Reinforcement Learning from Human Feedback:人間のフィードバックからの強化学習)が活用されています。従来の教師あり学習では、正解データを大量に用意する必要がありましたが、強化学習では「良い推論プロセス」を報酬として学習することで、より汎用的な推論能力を獲得できるのです。
特にDeepSeek-R1は、教師データなしの強化学習のみで推論能力を獲得した点が革新的です。これは強化学習におけるポリシー陳腐化問題を克服する新たなアプローチとして注目されています。
DeepSeek-R1の学習プロセスを例に
DeepSeek-R1は「GRPO(Group Relative Policy Optimization)」という独自の強化学習手法で訓練されています。GRPOの仕組みを理解することで、推論モデルがどのように学習するかが見えてくるでしょう。
Phase 1: コールドスタート:最初に少量の高品質な思考プロセスデータで基礎を作ります。この段階では、正しい推論の「型」を教える教師あり学習を適用するのです。
Phase 2: GRPO による強化学習:GRPOは従来のPPO(Proximal Policy Optimization)からCritic(価値関数)を削除し、グループスコアから直接アドバンテージを推定する手法です。具体的には、同じプロンプトに対して複数の回答を生成し、それらの報酬を標準化(平均0、標準偏差1)することでアドバンテージを計算します。
例えば「8+5=?」という問題に対して4つの回答を生成し、報酬が [1.0, 0.9, 0.0, 1.0] だった場合、平均0.725、標準偏差0.453となり、正規化されたアドバンテージは [0.61, 0.39, -1.60, 0.61] となるでしょう。この正規化により、Criticモデルなしで効率的な学習が可能になっています。
Phase 3: SFT によるフィルタリング:強化学習で生成された推論プロセスから高品質なものを選別し、教師あり学習でさらに洗練させます。
Phase 4: アライメント:最後に、人間の価値観や安全性基準に合わせる調整を行うわけです。この段階で有害な出力を抑制し、倫理的なガイドラインに従うよう学習されます。
このプロセスにより、DeepSeek-R1は教師データに依存せず、自己学習で推論能力を獲得しました。従来のモデルが「正解を覚える」のに対し、推論モデルは「考え方そのもの」を学習していると言えるでしょう。
推論トークンとコスト構造
推論モデルの運用において重要なのが、推論トークンのコスト構造を理解することです。推論トークンとは、モデルが内部で思考プロセスを展開する際に消費するトークンで、最終出力とは別にカウントされます。
これは「計算資源の配分問題」として捉えることができます。従来のLLMでは推論プロセスがブラックボックスでしたが、推論モデルでは開発者が思考の深さを制御できるようになったのです。
コストと精度のトレードオフ:推論トークンを増やせば精度は向上しますが、APIコストも比例して増加します。OpenAI o3の場合、従来モデルの約5倍のコストがかかるとされています。そのため、タスクの重要度に応じて推論レベルを調整する運用が求められるでしょう。
レイテンシの考慮:推論トークンの生成には時間がかかります。リアルタイム対話が必要なチャットボットには不向きですが、法務文書のレビューや複雑なコード解析など、精度が優先されるタスクには最適です。
動的な計算資源配分:最新の推論モデルは、問題の難易度を自動判定し、必要な推論トークン数を調整する機能を持ち始めています。簡単な質問には高速応答、複雑な質問には深い思考を割り当てることで、効率的な運用が可能になるでしょう。
使い分けのポイント
推論モデルが有効な場面
推論モデルは以下のようなタスクで真価を発揮します。
複雑なコードレビュー:単なる構文チェックではなく、アーキテクチャの妥当性や潜在的なバグを論理的に分析する場面で強みを発揮するでしょう。
数学・科学問題の解析:多段階の計算や証明が必要な問題では、推論プロセスを追跡できる点が大きな利点となります。
法務・財務文書の精査:契約書のリスク評価や財務諸表の矛盾検出など、高い精度が求められる分野で活用できます。
戦略的意思決定支援:複数の選択肢を比較検討し、それぞれのメリット・デメリットを論理的に整理する場面に適しています。
従来モデルが適切な場面
一方で、以下のようなタスクでは従来の高速なLLMの方が適切です。
定型的なテキスト生成:メール作成、要約、翻訳など、思考の深さが不要なタスクではオーバースペックとなります。
リアルタイム対話:チャットボットやカスタマーサポートなど、即時応答が求められる場面では推論モデルのレイテンシがボトルネックになるでしょう。
FAQ対応:定型的な質問に対する回答では、推論プロセスは不要です。
大量処理:数千件のデータを一括処理する場合、コスト面で従来モデルの方が有利となります。
プロンプティングのコツ
推論モデルを効果的に使うには、従来のプロンプティング手法とは異なるアプローチが必要です。
Chain of Thought 指示は不要:従来のLLMでは「ステップバイステップで考えてください」という指示が有効でしたが、推論モデルでは逆効果になる場合があります。推論プロセスはモデルが自動的に実行するため、むしろシンプルで明確な問題記述が効果的でしょう。
「何をしてほしいか」を明示:目的と期待する成果物を具体的に記述することが重要です。「この契約書のリスク要因を特定し、優先度順に列挙してください」のように、明確なゴールを示すことで推論モデルは適切な思考プロセスを展開します。
「どう考えるか」はモデルに委ねる:推論の進め方を細かく指定するよりも、問題の全体像を示した上で、思考プロセスはモデルに任せる方が良い結果が得られます。
思考予算の調整:重要なタスクでは推論レベルを「high」や「max」に設定し、十分な推論トークンを割り当てることが推奨されます。一方、探索的なタスクでは「low」や「medium」で素早く複数の案を生成する方が効率的でしょう。
推論モデルの注意点と限界
推論モデルは強力ですが、いくつかの注意点があります。
コストと速度のトレードオフ:従来モデルの約5倍のコストと、応答遅延が発生します。全てのタスクで推論モデルを使うのではなく、本当に必要な場面を見極めることが重要でしょう。
ハルシネーションの完全解決には至っていない:推論プロセスを持つことで精度は向上しましたが、依然として事実誤認や論理的な飛躍が発生する可能性があります。重要な意思決定では、人間による検証が不可欠です。
思考プロセスの透明性:各社のモデルで思考プロセスの可視化レベルに差があります。Claude Extended Thinkingは思考プロセスを詳細に表示しますが、他のモデルでは内部推論が完全にブラックボックスの場合もあるでしょう。
学習データの偏り:推論モデルも既存のLLMと同様、訓練データの偏りを反映します。特定の文化や視点に偏った推論を展開する可能性に注意が必要です。
まとめ
推論モデルは、AIが「考える」能力を持つという意味で、LLMの進化における重要なマイルストーンと言えます。従来のモデルが統計的なパターンマッチングで応答を生成するのに対し、推論モデルは思考プロセスそのものをモデル化し、複雑な問題を段階的に解決する能力を獲得しました。
OpenAI o3、Claude Extended Thinking、Gemini 2.5 Pro、DeepSeek-R1など、各社が独自のアプローチで推論モデルを開発していますが、共通するのはテストタイムコンピュートという概念です。計算資源を推論時に動的に配分することで、タスクの難易度に応じた柔軟な性能調整が可能になっています。
特にDeepSeek-R1のGRPOによる学習手法は、教師データなしで推論能力を獲得できることを示した点で画期的でしょう。これは今後の推論モデル開発において、重要な方向性を示していると考えられます。
推論モデルの活用においては、コストと精度のトレードオフを理解し、タスクの特性に応じて適切に使い分けることが重要です。複雑なコードレビュー、数学問題、法務文書の精査など、高い精度が求められる場面では推論モデルが威力を発揮します。一方、定型的なテキスト生成やリアルタイム対話では、従来の高速なLLMの方が適切な場合も多いでしょう。
2026年以降、推論モデルはさらに進化し、より効率的なアルゴリズム、低コスト化、リアルタイム応答の実現など、現在の課題が順次解決されていくことが期待されます。AI開発者や利用者にとって、推論モデルの特性と適用場面を理解することは、今後ますます重要になっていくはずです。





