
- 統一離散視覚トークナイザーが4つの損失関数で意味的識別性・言語整合性・再構成品質を同時に最適化し、理解・生成・編集の3タスクに使える汎用表現を実現
- 7Bパラメータの単一自己回帰モデルが画像理解・テキストから画像生成・画像編集を統合処理し、各ベンチマークで連続表現モデルと競争力ある性能を達成
- 強化学習がタスク間の相乗効果を生み出し、WISE総合スコアが0.50から0.56、GEdit-Bench G_Oが5.75から6.68へ向上
研究の背景と課題
画像を「理解する」タスクと「生成する」タスクは、これまで別々のモデルで扱われてきました。視覚言語モデル(VLM)は画像の内容を把握して質問に答えることを得意としますが、新たな画像を作り出す能力は持ちません。一方、拡散モデルなどの生成モデルは高品質な画像を生成できますが、画像の意味を深く理解することは苦手です。
この分断の根本にあるのが表現の問題です。理解タスクでは意味的な特徴を抽出する連続表現が有利ですが、自己回帰モデルによる生成には離散トークンが必要です。さらに画像編集は理解と生成の両方を組み合わせる必要があり、従来は専用のアーキテクチャが別途必要とされてきました。ARM(AutoRegressive large Multimodal model)はこの課題に正面から向き合い、統一された離散表現と7Bパラメータの自己回帰モデルで3タスクを単一フレームワークに統合した研究です。
統一離散視覚トークナイザー
ARMの核心となるのが、独自設計の統一離散視覚トークナイザーです。ベースには事前学習済みのSigLIP2エンコーダー(凍結状態で使用)を用い、その出力をAttentionベースの射影ブロックでコンパクトなトークン列に変換した後、FSQ(Finite Scalar Quantization)で離散化します。
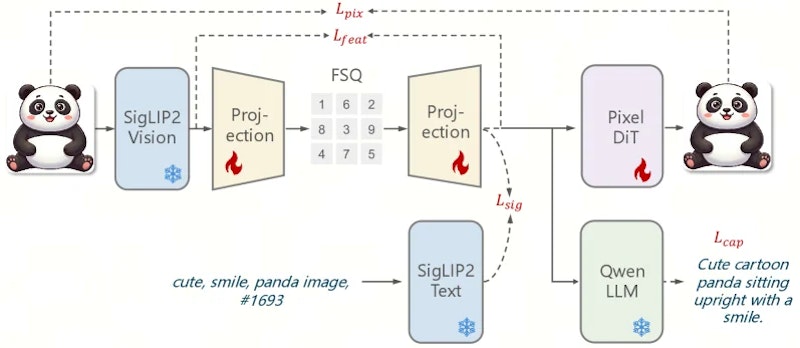
このトークナイザーを学習させるために、4つの補完的な損失関数が組み合わされています。キャプション損失で言語整合性を確保し、拡散トランスフォーマーを使ったピクセル再構成損失で視覚的忠実度を維持します。加えてSigmoidコントラスト損失で意味的な識別性を高め、特徴蒸留損失で視覚的意味論を保持します。この4つの目標を同時に最適化することで、理解・生成・編集のすべてに使える汎用的な離散表現が得られます。
意味的なトークナイザーを用いることで、推論時にClassifier-Free Guidance(CFG)への依存度が下がるという効果も確認されています。CFGは条件付き生成と無条件生成の出力を組み合わせてサンプリング品質を高める手法ですが、CFGなしでも品質の劣化が少なく、推論を高速化できる実用的なメリットがあります。
4段階の訓練パイプライン
7Bパラメータの自己回帰モデルは、テキストと画像のトークン列を混合した大規模データで訓練されます。訓練は4段階に分かれており、まず2.5兆トークン規模の事前学習でベースとなる視覚言語能力を獲得します。その後、継続訓練と教師ありファインチューニング(SFT)を経て、最終段階で強化学習による最適化が行われます。
拡散デコーダとしてはSANA 1.5とFluxの2種類が検討されており、共通の視覚トークンを用いた再構成品質と、テキストから画像への生成品質が比較検証されています。異なるデコーダを使いながらも同一のトークン表現を共有できることが、ARMの統一設計の強みです。
強化学習によるタスク間の相乗効果
ARMの特徴的な取り組みの一つが、強化学習(RL)を用いたタスクレベルの最適化です。視覚品質、指示遵守、編集一貫性といった各タスク固有の評価指標を報酬として用い、GPT-4系モデルを報酬モデルとして活用しています。
RLの適用で明らかになったのが、タスク間の相乗効果(cross-task synergy)です。テキストから画像を生成するタスクでRLを適用すると、画像編集タスクの性能も同時に向上するという現象が観察されました。単一の統合モデルだからこそ生まれるこの効果は、理解・生成・編集を別々に訓練するアプローチでは得られない利点です。強化学習を活用して視覚空間推論能力を向上させるAstraなど、RL活用はマルチモーダル研究全体で注目が集まっています。

主要な実験結果
ARMは画像理解のベンチマークでも連続表現を使うモデルと肩を並べる性能を示しています。POPE(物体の存在確認タスク)では87.3、MMMU(多分野の視覚的質問応答)では40.2、MME Perceptionでは1463を記録しています。
画像生成のGenEvalでは総合スコア0.86を達成し、画像編集のGEdit-Bench G_Oスコアは、RL適用前の5.75からRL適用後の6.68へと向上しました。WISE(生成・編集を総合評価するスコア)も0.50から0.56へと改善しており、RLがモデル全体の品質を底上げしていることがわかります。
まとめと今後の展望
ARMは、意味的な離散トークン表現と自己回帰モデリング、そして強化学習を組み合わせることで、画像理解・生成・編集を7Bパラメータの単一モデルに統合することに成功しました。理解と生成・編集を共通の表現で扱うことで生まれるタスク間の相乗効果は、統合アーキテクチャならではの強みです。
連続表現を使う既存の大規模マルチモーダルモデルと比べても、理解性能で遜色のない結果を示したことは、離散表現の可能性を広げる重要な知見です。今後は、より多様なモダリティへの拡張や、さらに大規模なパラメータでの検証が期待されます。自律エージェントへの応用では、画像の理解と生成・編集を一貫したインターフェースで扱えることが大きな利点になると考えられます。コードはGitHubで公開されており、研究コミュニティが自由に実験を再現・発展させられる環境が整っている点も、今後の研究加速につながるでしょう。







