
- 新しいフレームワーク「EnerVerse」はロボットの未来状態予測と操作指令生成を統合的に行う枠組み
- 「Chunk Diffusion」と「Free Anchor View」という技術で予測の不連続性や空間情報の欠落を解消
- 実験で優れた性能を示し、Sparse Memoryにより計算資源を節約しながらタスクを効果的に遂行
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
本論文の概要
本論文では、ロボット操作における「未来空間」生成を目的とした新しいフレームワーク「EnerVerse」が提案されています。このフレームワークは、未来状態の予測とその情報を活用した具体的な操作指令の生成を統合的に行うことで、課題の解決を目指します。特に、未来空間(Future Anchor View: FAV)の生成に焦点を当て、これによりロボットが環境や物体とのインタラクションを合理的かつ効果的に学習できるよう設計されています。
モデル構造は、複数の主要コンポーネントから構成されており、特徴的な技術として、「Chunk Diffusion」や「Free Anchor View(自由視点生成)」が採用されています。特に、Chunk Diffusionは観測データを元に連続性を考慮した未来フレームを生成する機能を持つのに対し、Free Anchor Viewは視点の柔軟性を保証し、カメラの異なる視点でも空間認識を向上させています。この組み合わせにより、従来手法が直面していた予測の不連続性や空間情報の欠落といった課題を効果的に解消しています。
実験評価では、ロボット操作シナリオ用のベンチマーク「LIBERO」が使用され、EnerVerseの性能が検証されました。評価基準として、位置精度(Spatial)、視覚認識(Visual)、およびタスク成功率(Task Success)が取り上げられ、提案手法がこれらの指標で従来手法を上回る結果を示しました。また、生成したFAVがより高品質でタスク実行の重要な手がかりとなることが確認されました。
さらに、本研究では、メモリ利用やクロス視点データ処理の効果も分析されています。例えば、Sparse Memoryを用いることにより、計算資源を節約しつつ効果的なタスク遂行が可能であることを実証しています。また、現実環境での操作タスクも実施され、実際のロボット操作においても本手法の有効性が示されました。
図表の解説
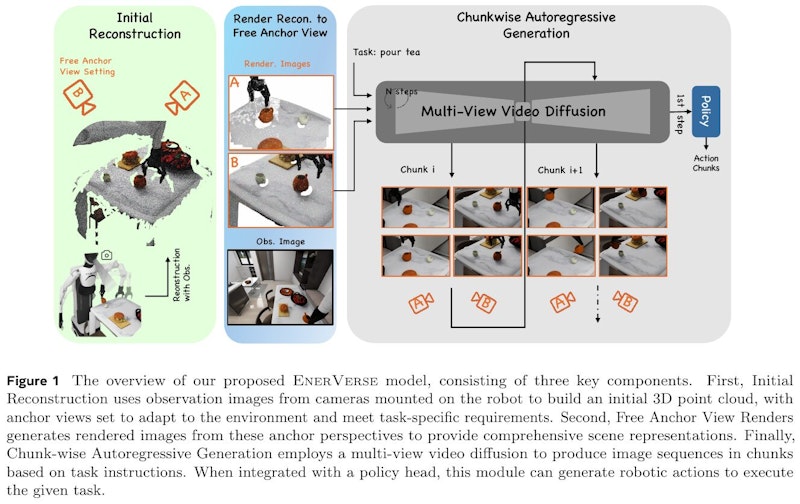
画像はEnerVerseモデルの概要を示しています。このモデルはロボットの操作タスクに使用され、3つの主要なコンポーネントで構成されています。まず、「初期再構成」ではロボットに搭載されたカメラからの観察画像を用いて3D点群を作成し、環境に適応するアンカービューを設定します。次に、「フリーアンカービュー」の生成により、これらの視点からシーンを詳細にレンダリングします。最後に「チャンク毎の自己回帰生成」によりビデオの断片を生成し、ロボットの動作を導きます。これにより、ロボットは対象タスクを遂行する能力が向上します。
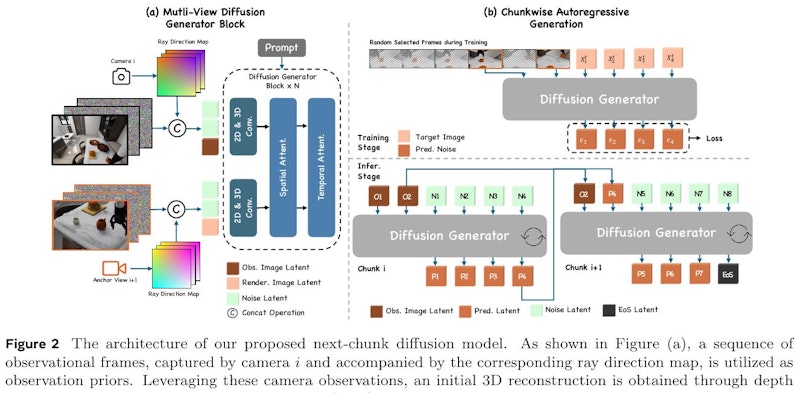
この画像は、EnerVerseシステムの「次のチャンクの拡散モデル」のアーキテクチャを示しています。図の左側では、観察フレームと光線方向マップを使用して、3D再構築が開始されます。これにより、フリーアンカービュー(FAV)が設定されます。図(a)はマルチビュー拡散ブロックを示し、カメラ位置から得られた画像と生成された画像を組み合わせて新たな視点の映像を生成します。 図(b)は「チャンク単位の自己回帰生成」を示し、訓練段階では観察フレームにノイズを加え、推論段階でそのノイズを除去し、新たなフレームセットとして利用します。この方法で、無限長のビデオシーケンスを効率的に生成することが可能です。これにより、ロボットの操作タスクでの意思決定が改善されます。
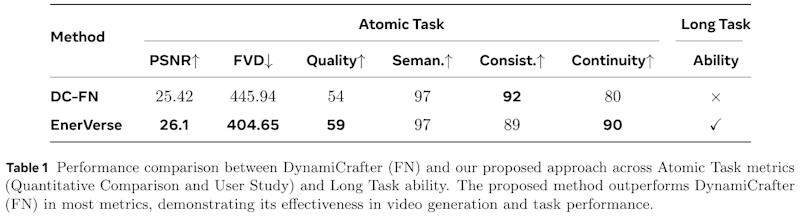
この表は「EnerVerse」という新しい手法が、既存の「DynamiCrafter」(DC-FN)という手法と比較してどれほど優れているかを示しています。評価項目は「Atomic Task」と「Long Task」に分かれています。 「Atomic Task」では、PSNR(画質の指標)が高いほど良く、EnerVerse(26.1)がDC-FN(25.42)よりも優れています。FVD(動画の質の指標)は低いほど良く、EnerVerse(404.65)はDC-FN(445.94)よりも優れていることがわかります。品質(Quality)、意味的整合性(Semantic)、連続性(Consistency)、継続性(Continuity)についてもEnerVerseの方が全般的に良いスコアを示しています。 さらに「Long Task」における能力も、EnerVerseの方がDC-FNよりも優れており、提案手法が長期的なタスクに適していることを表しています。
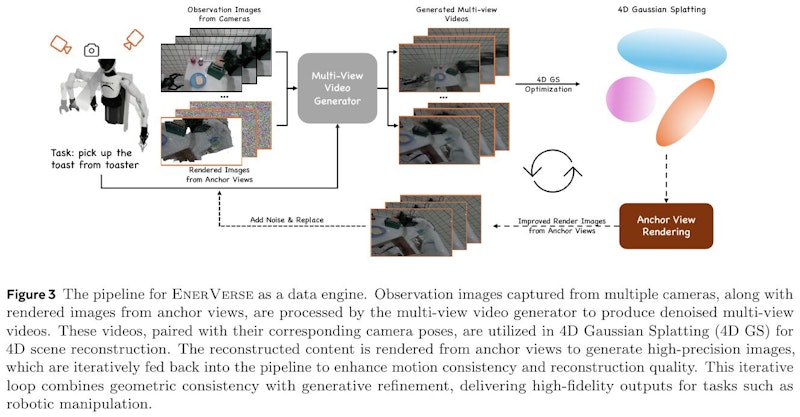
この図は、EnerVerseというデータエンジンのパイプラインを示しています。複数のカメラから取得した観察画像とアンカービューから生成されたレンダリング画像を利用して、マルチビュー動画を生成します。これらの生成された動画は、カメラの位置情報とともに4次元のシーン再構築に使用されます。再構築されたコンテンツはアンカービューからレンダリングされ、高精度の画像を生成します。このプロセスは、動作の一貫性と再構築の品質を向上させるために反復的に行われます。この方法により、ロボット操作のようなタスクで高品質な出力を得ることができます。
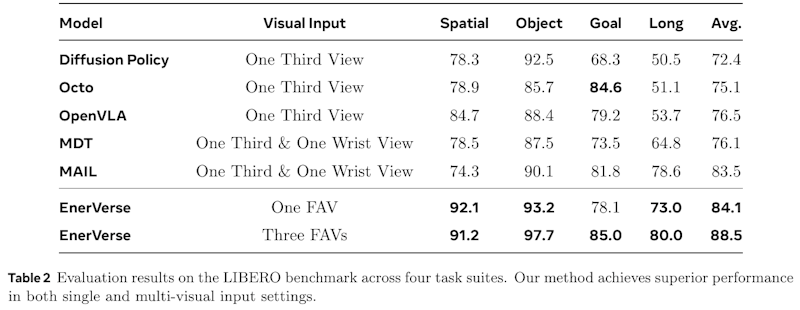
この表は、様々なモデルがLIBEROベンチマークでどのように性能を発揮するかを示しています。具体的には、Spatial, Object, Goal, Longという4つのタスクセットで評価されています。表の下部に示されているEnerVerseモデルは、「One FAV」(1つの自由アンカービュー)や「Three FAVs」(3つの自由アンカービュー)を使っています。これらの視覚入力によって、特にSpatialやObjectタスクで高い性能を発揮しています。結果として、EnerVerseは他のモデルと比べて平均して高い評価を受けています。このことは、多視点入力がロボットの操作を大いに改善することを示しています。
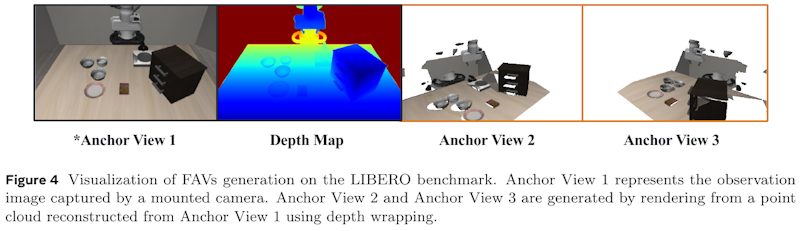
この画像は、ロボット操作のための将来空間生成フレームワーク「EnerVerse」に関する研究からのもので、LIBEROベンチマーク上での自由アンカービュー(FAV)の生成を視覚化しています。画像の左端、アンカービュー1は固定カメラで撮影された観察画像を示しています。その隣の深度マップを使い、アンカービュー1から得られたポイントクラウドを元に、アンカービュー2とアンカービュー3が生成されています。この手法により、多視点から環境を観察することができ、ロボットの操作や分析を強化します。FAVは、狭い環境での物理的制約を避けたり、モーションモデルの曖昧さを低減するのに役立ちます。

この表は、LIBERO-Longタスクにおける「Sparse Memory」(スパースメモリ)使用の有無によるパフォーマンスの比較を示しています。具体的には、Sparse Memoryを使用しない場合のスコアは30.8であり、使用する場合のスコアは73とされています。この結果から、Sparse Memoryの導入により、タスクのパフォーマンスが大きく向上することが示されています。Sparse Memoryは、情報の冗長性を減らし、より有効に状況を理解する助けとなります。この技術は、ロボティクスの長距離操作タスクにおいて特に有効です。

この図は、EnerVerseとDynamiCrafter(FN)の2つのモデルによる単一ビューのビデオ生成の比較を示しています。指定されたタスク「下の引き出しから青いプラスチックボトルを取り出し、カウンターに置く」を完了するプロセスを可視化しています。EnerVerseは、42フレーム目で終了フレーム(EOS)を予測します。 上段のDynamiCrafter(FN)では、タスクの進行に伴い複数の不自然なシーンが生成されています。一方、下段のEnerVerseは、タスク全体の未来のシーンを連続的に正確に生成し、最後の終了フレームまで論理的な一貫性を保っています。このことから、EnerVerseがより正確で連続したビデオシーケンスを生成できることが示されています。







