
この論文では、人間の視覚的な注意や好みを予測する統合モデル「UniAR」を提案しています。従来は個別のモデルで対応していた「視線の動き」「重要な部分の予測」「審美性の評価」などを1つのモデルで実現し、様々な種類の画像(自然画像、Webページ、グラフィックデザインなど)に対して高精度な予測を可能にしました。
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
この研究のポイントは?
この論文では、人間の視覚的な注意と反応を予測する統合モデル「UniAR」を提案しています。

- 課題:従来の研究では「視線の動き」「重要な部分の予測」「審美性の評価」などが個別のモデルで対応されており、統合的なアプローチが欠けていたこと
- 解決手法:画像とテキストプロンプトを入力とするマルチモーダルTransformerモデルを採用し、11の公開データセットを用いて学習を行いました。
- ポイント①:1つのモデルで複数の視覚的行動予測タスクを高精度に実行できるようになったこと
- ポイント②:自然画像、Webページ、グラフィックデザインなど、様々な種類の視覚コンテンツに対して、視線の動きや重要度、好みなどを統合的に予測できます。
背景と概要
人間の視覚的な注意や好みを予測するモデルは、これまで個別のタスクや特定の種類の画像に特化して開発されてきました。例えば、視線の動きを予測するモデル、重要な部分を予測するモデル、審美性を評価するモデルなどが別々に存在していました。
この論文では、そうした断片的なアプローチを統合し、1つのモデルで多様な予測を可能にする「UniAR」を提案しています。UniARは、画像とテキストプロンプトを入力として受け取り、マルチモーダルTransformerを用いて処理を行います。具体的には、自然画像、Webページ、グラフィックデザインなど様々な種類の視覚コンテンツに対して、以下の3種類の予測を統合的に行うことができます:
- 人間の注意や重要度を示すヒートマップの予測
- 視線の動きの順序(スキャンパス)の予測
- 主観的な好みや審美性の評価の予測
11の公開データセットを用いた実験では、特定のタスクに特化した既存の最先端モデルと同等以上の性能を達成しました。また、学習していない新しいタスクと入力の組み合わせにも対応できる汎用性を示しています。
提案手法
本研究では、人間の視覚的な注意や好みを予測する統合モデル「UniAR」を提案しています。このモデルは、マルチモーダルTransformerを基盤とし、画像とテキストプロンプトを入力として受け取ります。
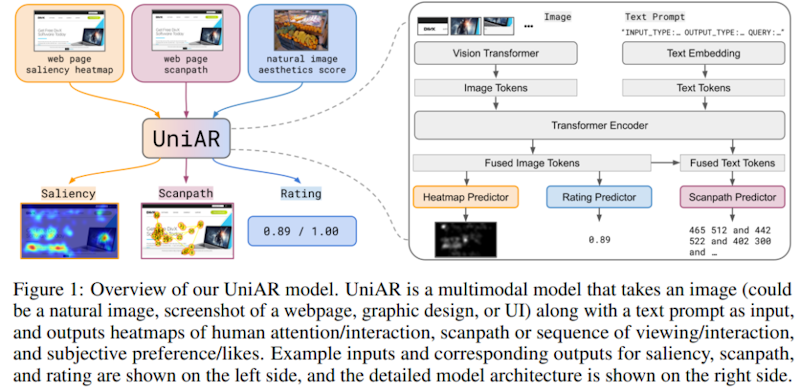
モデルのアーキテクチャは、画像エンコーディング用のVision Transformer、テキストトークンを埋め込むための単語埋め込み層、そして画像とテキストの表現を融合するT5 Transformerエンコーダーで構成されています。さらに、3つの予測ヘッドを備えています。
1つ目は注意・重要度のヒートマップを予測するヘッドで、画像内の注目領域を可視化します。
2つ目は視線の動きの順序を予測するスキャンパス予測ヘッドで、人間がどのような順序で画像を見るかを予測します。
3つ目は画質や審美性のスコアを予測する評価ヘッドです。
テキストプロンプトには入力の種類(自然画像やWebページなど)、予測タスクの種類(注意ヒートマップや審美性スコアなど)、タスクに関連する情報(探索対象の物体名など)が含まれます。

11の公開データセットを用いて学習を行い、自然画像、Webページ、グラフィックデザインなど様々な種類の視覚コンテンツに対して、既存の特化型モデルと同等以上の性能を達成しました。また、学習していない新しい入力とタスクの組み合わせにも対応できる汎用性を示しています。
実験
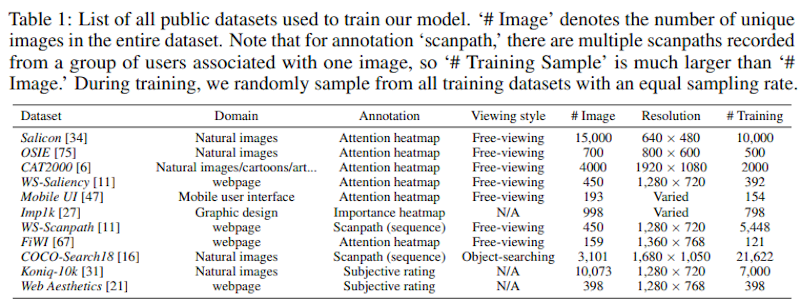
本研究では、11の公開データセットを用いて実験を行いました。データセットには自然画像、Webページ、グラフィックデザインなど多様な視覚コンテンツが含まれています。
実験の評価は主に3つの側面から行われました。
まず、注意・重要度のヒートマップ予測では、7つのデータセットで検証を実施し、多くの評価指標で既存の最先端モデルを上回る性能を達成しました。特にMobile UIとImp1kデータセットでは、全ての評価指標で従来手法を超える結果となりました。
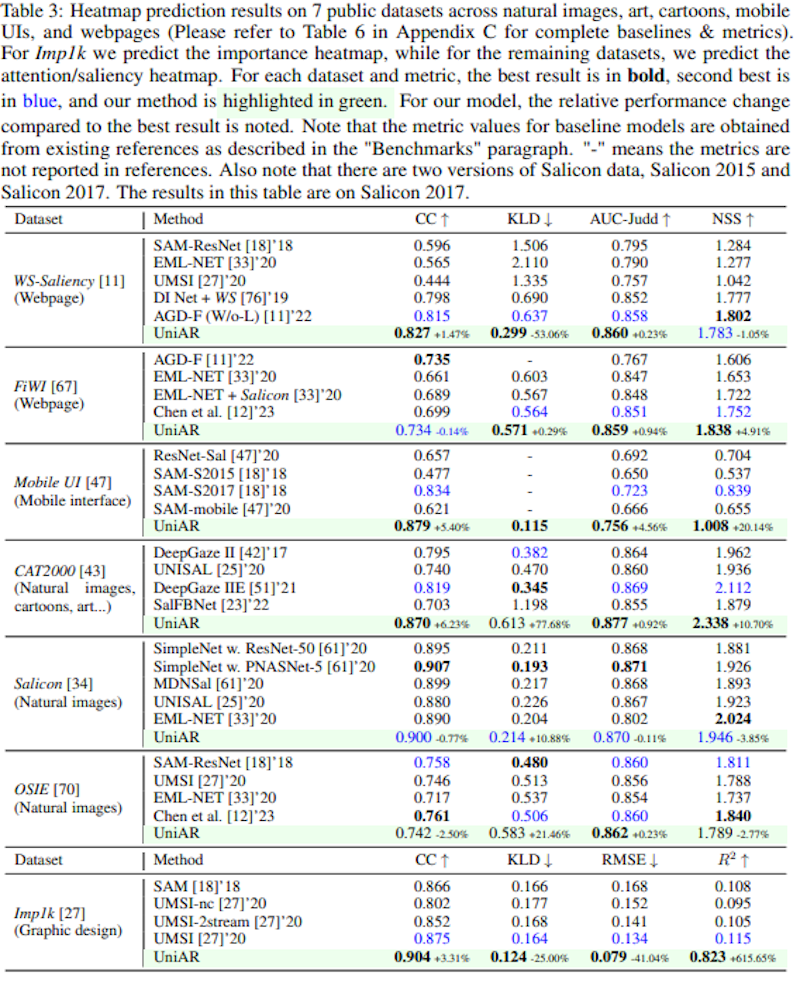
次に、視線の動きの順序(スキャンパス)予測では、COCO-Search18とWS-Scanpathの2つのデータセットで評価を行いました。WS-Scanpathデータセットでは全ての指標で最高性能を記録し、COCO-Search18でも競争力のある結果を示しました。
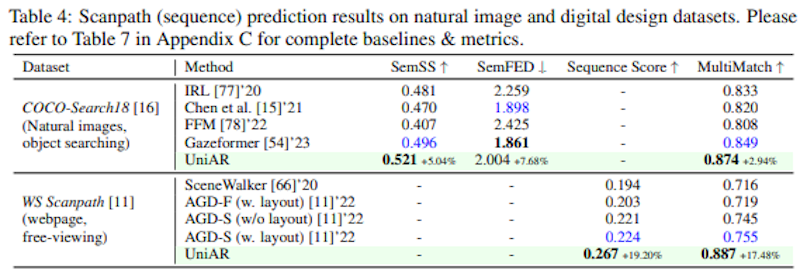
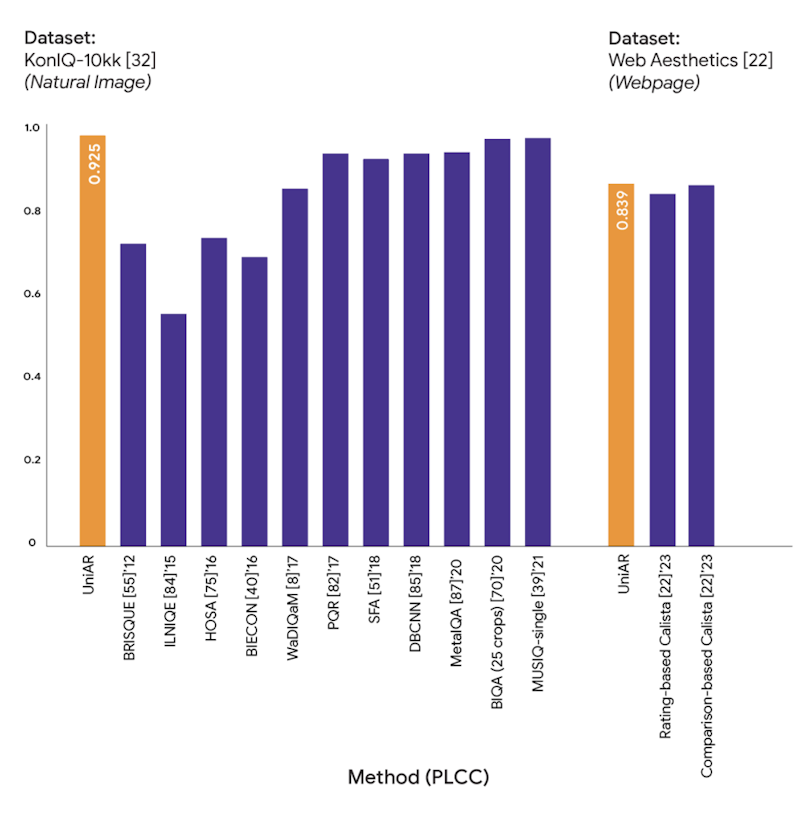
さらに、画像の審美性評価では、KonIQ-10kとWeb Aestheticsデータセットを使用し、PLCCメトリックで最高性能を達成しました。
モデルの学習には、Adafactorオプティマイザーを使用し、学習率0.1、バッチサイズ128で実施しました。画像は512×512の解像度で処理され、アスペクト比を維持したままパディングを適用しています。学習には64台のGoogle Cloud TPU v3を使用し、約12時間で2万ステップの学習を完了させました。
また、異なるタスクやドメイン間での知識転移能力も検証され、直接学習していない組み合わせでも競争力のある性能を示すことができました。
結論
本研究では、人間の視覚的な注意と反応を予測する統合モデル「UniAR」を提案し、その有効性を実証しました。実験結果から、UniARは11の異なるデータセットにおいて、既存の特化型モデルと同等以上の性能を達成しました。特に、Mobile UIとImp1kデータセットでは、全ての評価指標で従来手法を上回る結果となりました。
この研究成果は、UIデザインの評価や視覚コンテンツの最適化において、効率的なフィードバックを可能にし、人間中心のデザイン改善に貢献することが期待されます。







