 言語・LLM
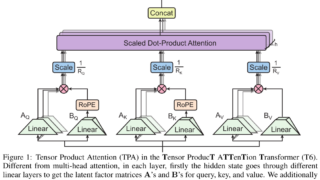
言語・LLM メモリ効率を向上するアテンション機構「TPA」でTransformer軽量化
テンソル積を用いた効率的な注意メカニズムTPAを提案。従来のTransformerとの統合が簡単で、メモリ効率や計算負荷を改善し、資源節約に貢献。計算資源が限られる環境での利点を強調。
言語・LLM 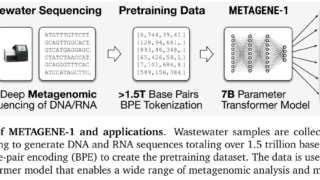 データセット
データセット  言語・LLM
言語・LLM 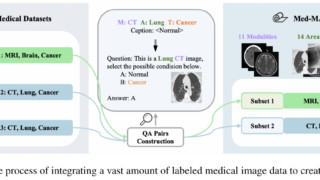 マルチモーダル
マルチモーダル  マルチモーダル
マルチモーダル  言語・LLM
言語・LLM  動画
動画  マルチモーダル
マルチモーダル  動画
動画  ニュース
ニュース