マルチモーダル 【VITA-1.5】音声と視覚の統合技術で人と機械の自然な対話を実現 VITA-1.5モデルは音声と視覚情報を統合し、人と機械の自然なコミュニケーションを強化。視覚と言語を学習後に音声を統合し、リアルタイムに動的処理と瞬時の出力を実現します。 2025.01.29 マルチモーダル論文解説
ニュース VLCメディアプレーヤー、新AI字幕機能で翻訳革命! VLCメディアプレーヤーが新AI機能を導入!オフラインで字幕を自動生成し、100以上の言語に翻訳可能。プライバシーを守りつつ、グローバルな動画視聴体験を飛躍的に向上させます。 2025.01.14 ニュース技術
データセット YouTubeの教育動画データセットで視覚質問の応答性能を向上 この研究では、YouTubeの教育動画を元にしたマルチモーダルデータセットを構築し、音声認識や字幕同期を用いて説明文を生成するパイプラインを開発。提案データセットは視覚質問応答タスクの性能を向上させることに成功。 2025.01.07 データセット論文解説
 マルチモーダル マルチモーダル
マルチモーダル マルチモーダル  ニュース
ニュース 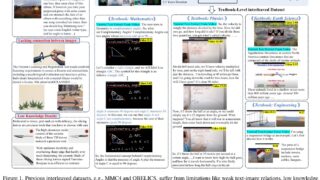 データセット
データセット