強化学習 【Meta-CoT】高難度な数学タスクに優れたフレームワークでLLMの推論能力を向上 新たなフレームワーク「Meta-CoT」で複雑な推論能力を向上!自己強化型学習法とバックトラッキング機能を活用し、モデルの正確性と自己修正能力を強化。特に高難度の数学タスクで優れた性能、「Big MATH」が貢献。 2025.01.30 強化学習論文解説
言語・LLM LLMの考えすぎを抑え効率性20%向上する手法 LLMの考えすぎ問題がモデルの効率と精度に与える影響を分析し、Reasoning Preference Optimizationで緩和。提案手法により数学テストの精度と効率が約10%-20%向上。o1やQwQ-32Bなどを用い、数学的問題や一般知識に基づくテストを実施。 2025.01.06 言語・LLM論文解説
 強化学習 強化学習
強化学習 強化学習 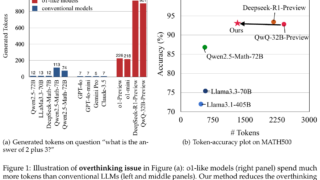 言語・LLM
言語・LLM