強化学習 強化学習で新次元に達したDeepSeek-R1の性能がGPT-4超え 事前学習済みモデルに強化学習を適用したDeepSeek-R1-Zeroが、自律的な思考時間調整を実現。さらに、SFTを補完しつつOpenAI GPT-4-1217を超える性能を示し、省資源な推論の可能性を示唆。 2025.03.31 強化学習論文解説
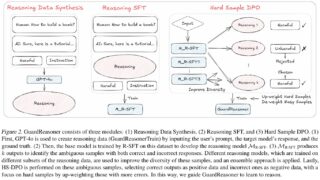
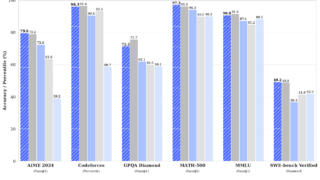
言語・LLM 【GuardReasoner】LLM応答の安全を制御!出力の有害性を検出 LLMの応答を安全に制御する新手法「GuardReasoner」を提案。合成データを用いた教師あり学習で推論精度を向上し、多様なベンチマークで高い安全性と説得力を実証。 2025.02.03 言語・LLM論文解説
 強化学習
強化学習