 データセット
データセット GPT-4で地理情報推論力を評価するデータセット「MapEval」の提案
新データセット「MapEval」を提案し、地理空間推論能力を評価。リアルな地理情報を基にした新たなLLM評価方法を確立。最新のGPT-4等で性能を検証し、課題を発見する試み。
データセット 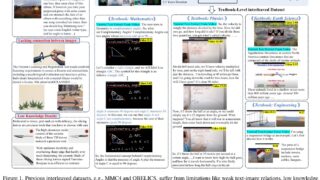 データセット
データセット 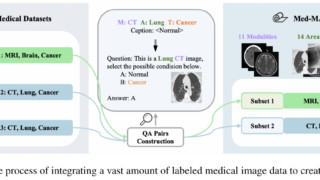 マルチモーダル
マルチモーダル  オープンソース
オープンソース  言語・LLM
言語・LLM