 強化学習
強化学習 エージェント協調強化の新技術「SRMT」開発成功
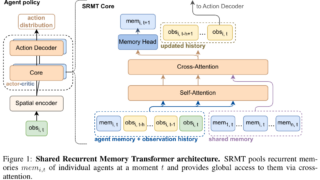
協調を高めるために、エージェント間で記憶を共有する新手法SRMTを開発SRMTはエージェントが共有メモリを用いて高度な意思決定を行い、報酬最大化を学習シミュレーション実験でSRMTは他の手法を上回る成功率と汎用性を確認論文:SRMT: Sh...
強化学習  動画
動画  ニュース
ニュース  ニュース
ニュース  強化学習
強化学習  言語・LLM
言語・LLM