
画像とテキストの学習において、従来のCLIPのような対照学習ではなく、テキストを直接分類ラベルとして扱う「SuperClass」という手法を提案。大規模なバッチサイズや複雑なテキスト処理が不要になり、より効率的な学習が可能になりました。ImageNetなどの様々なタスクでCLIPと同等以上の性能を達成しています。
論文:Classification Done Right for Vision-Language Pre-Training
GitHub:https://github.com/x-cls/superclass
本記事で使用している画像は論文中の図表、またはそれを参考に作成した画像を使用しております。
この研究のポイントは?
本論文は、画像と言語の学習において、従来のCLIPのような対照学習の課題を解決する手法「SuperClass」を提案しています。
- 課題:CLIPが必要とする大規模なバッチサイズ(64,000以上)とテキストエンコーダーの計算コストが高く、研究者が利用しづらい点。
- 解決手法:テキストを直接分類ラベルとして扱い、テキストエンコーダーを不要にし、テキストの前処理や選別も行わず、生のテキストトークンをそのまま教師信号として使用。
- ポイント①:より少ないバッチサイズ(16,000)でCLIPと同等以上の性能を達成し、計算コストを大幅に削減。
- ポイント②:ImageNetでの線形評価では85.0%の精度を達成し、最新のDINOv2の84.5%を上回る。
つまり、シンプルな分類学習でありながら高性能な視覚-言語モデルの学習を可能にし、より多くの研究者が利用できる手法を実現した研究と言えます。
概要
近年、画像と言語の学習において、CLIPのような対照学習が主流となっていますが、大規模なバッチサイズ(64,000以上)とテキストエンコーダーの計算コストが高いという課題がありました。
この問題に対して、本研究では「SuperClass」という新しい手法を提案しています。SuperClassの特徴は、テキストを直接分類ラベルとして扱う点です。従来の手法では、テキストから「良質なラベル」を抽出するための複雑な前処理や手作業による選別が必要でしたが、SuperClassではテキストトークンをそのまま教師信号として使用します。
また、テキストエンコーダーを不要にすることで、計算コストを大幅に削減しています。実験結果では、より少ないバッチサイズ(16,000)でCLIPと同等以上の性能を達成しました。特にImageNetでの線形評価では85.0%の精度を記録し、最新のDINOv2の84.5%を上回りました。
さらに、視覚・言語タスクにおいても優れた性能を示し、VQAv2やT-VQAなどのタスクでCLIPを上回る結果を残しています。この研究は、シンプルな分類学習でありながら高性能な視覚-言語モデルの学習を可能にし、計算リソースの制約がある研究者でも利用しやすい手法を実現した点で重要な意義があります。
提案手法
本研究では「SuperClass」という新しい画像-テキスト学習手法を提案しています。従来のCLIPでは、画像とテキストを別々のエンコーダーで処理し、対照学習を行う必要がありましたが、SuperClassではテキストを直接分類ラベルとして扱います。
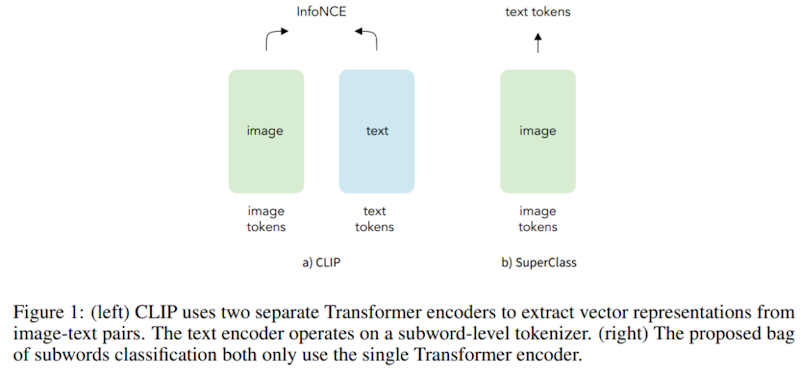
具体的には、テキストをサブワードレベルでトークン化し、そのトークンを分類のカテゴリとして使用します。テキストの前処理や選別は一切行わず、生のテキストトークンをそのまま教師信号として活用します。
また、各トークンの重要度を反映するため、逆文書頻度(IDF)を重みとして導入しています。この手法の特徴は、テキストエンコーダーが不要になり、計算コストを大幅に削減できる点です。また、CLIPが必要とする大規模なバッチサイズ(64,000以上)も、SuperClassでは16,000程度まで削減できます。
実験
本研究では、Datacomp-1Bデータセットを用いて実験を行い、SuperClassの性能を評価しています。主な実験として、ImageNet-1Kでの線形評価、10ショット分類、ゼロショット分類、画像キャプション生成などを実施しました。
実験結果では、SuperClassはImageNet-1Kの線形評価でViT-Largeモデルを使用した場合に85.0%の精度を達成し、最新のDINOv2の84.5%を上回りました。
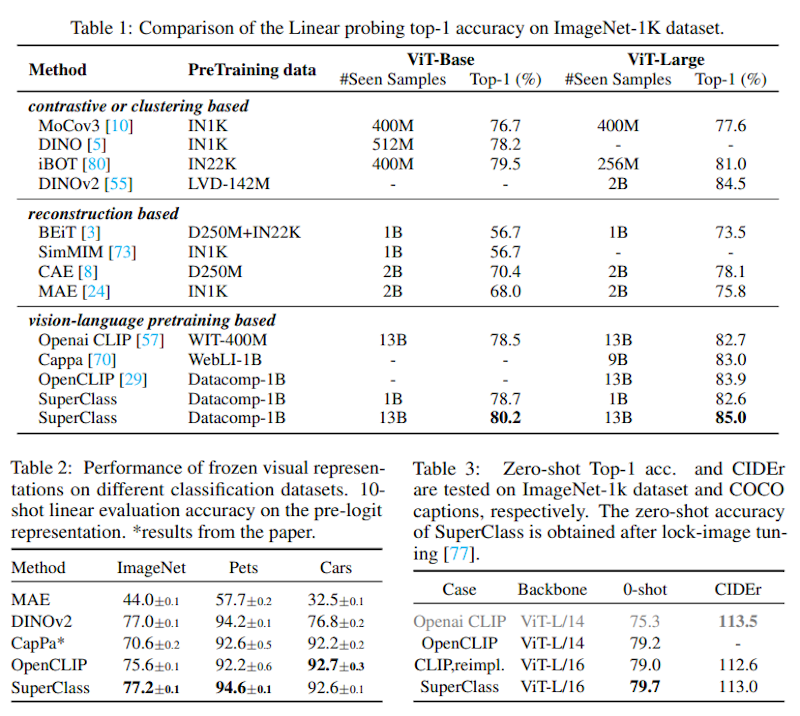
また、CLIPと比較してもViT-BaseとViT-Largeの両方で高い性能を示しています。特筆すべき点として、SuperClassはCLIPが必要とする大規模なバッチサイズ(64,000以上)を必要とせず、16,000程度のバッチサイズで同等以上の性能を実現しました。
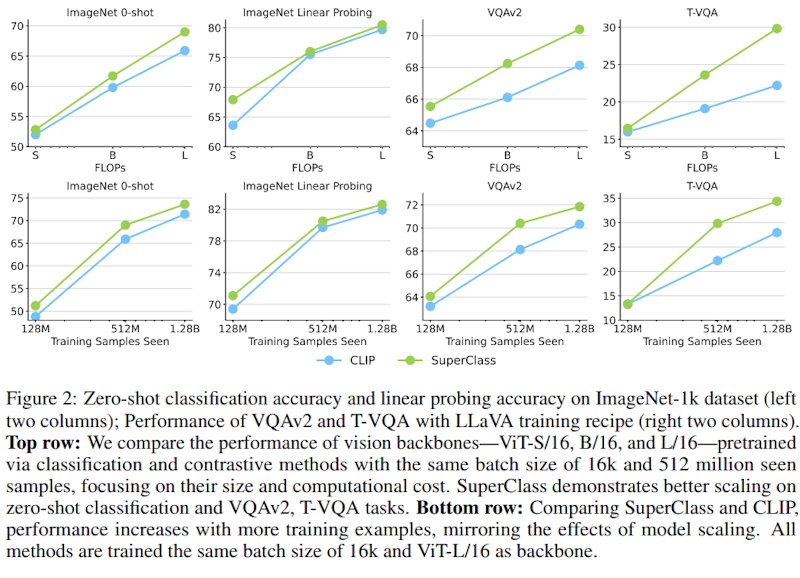
さらに、テキストエンコーダーが不要なため、計算コストも大幅に削減できています。視覚・言語タスクにおいても、VQAv2やT-VQAなどのタスクでCLIPを上回る性能を示しました。特にOCRや細かい認識を必要とするタスクで優れた性能を発揮しています。
モデルサイズやデータ量のスケーリング実験では、SuperClassはCLIPと同等かそれ以上のスケーリング性能を示し、より効率的な学習が可能であることが実証されました。また、異なるトークナイザーや損失関数の比較実験も行い、提案手法の有効性を確認しています。
結論
本研究では、画像とテキストの学習において、分類ベースの事前学習手法「SuperClass」が従来のCLIPのような対照学習と比較して優れた性能を示すことを実証しました。SuperClassの最大の利点は、テキストエンコーダーが不要で、より小さなバッチサイズでも効率的な学習が可能な点です。
本研究は、画像-テキストデータを用いた事前学習において、シンプルな分類学習が効果的な戦略となり得ることを示しました。この成果は、今後の視覚エンコーダーの事前学習手法の研究に新たな方向性を提示しています。







