 マルチモーダル
マルチモーダル 画像の安全性を自動判断するAI技術「MLLM-as-a-Judge」
新たな手法「MLLM-as-a-Judge」を提案。画像の安全性を自動判断し、CLUEフレームワークを活用して関連性や条件を高度に判定。従来より高精度・効率的な結果を実現し、応用可能性も示唆。
マルチモーダル 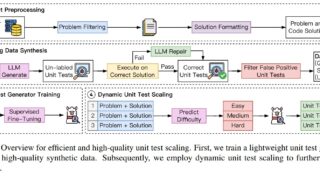 言語・LLM
言語・LLM 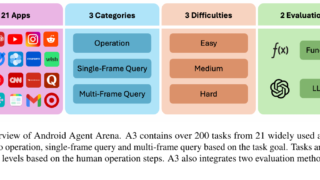 言語・LLM
言語・LLM  データセット
データセット 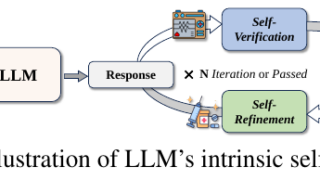 言語・LLM
言語・LLM 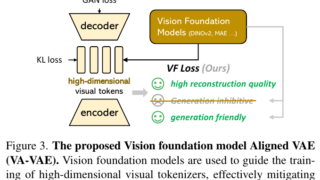 画像
画像  データセット
データセット  言語・LLM
言語・LLM  画像
画像  言語・LLM
言語・LLM