 マルチモーダル
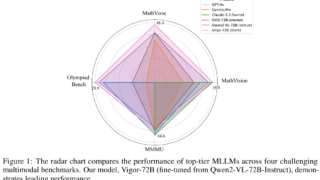
マルチモーダル 長い思考指示と知識蒸留で視覚タスク性能を向上したMLLM「Virgo」の提案
視覚推論力を向上させるMLLM「Virgo」が登場!長い思考指示と知識蒸留の2アプローチで性能向上を実証。データの質が結果に及ぼす影響も重要と確認。
マルチモーダル  マルチモーダル
マルチモーダル  強化学習
強化学習  画像
画像 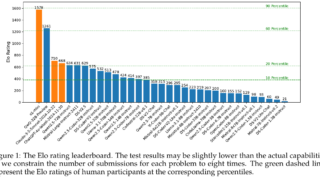 データセット
データセット 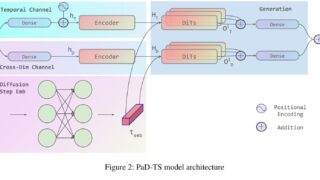 データセット
データセット 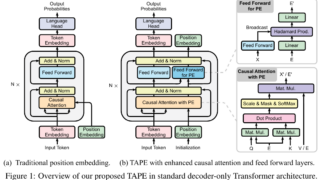 言語・LLM
言語・LLM  動画
動画  言語・LLM
言語・LLM  動画
動画